4 Conclusion
Pendant la procédure d’extraction des syntagmes nominaux du corpus, bien qu’on ait pris toutes les précautions, il a été difficile de garder une certaine homogénéité. Les raisons principales sont : (a) la diversité de style de rédaction des articles, étant donné qu’ils ont été écrits par quinze auteurs différents. On s’est rendu compte qu’il y a un lien étroit entre la facilité d’extraction des syntagmes nominaux et la clarté des articles ; (b) le manque d’un ensemble de règles pour orienter plus précisément la procédure d’extraction des syntagmes nominaux ; (c) le processus d’extraction n’a pas été continu, car des événements divers ont interrompu le travail. Ainsi, il a fallu faire une révision des syntagmes nominaux extraits, au fur et à mesure du chargement de la base de données et de la construction de l’arborescence.
Les résultats de cette étape sont consolidés dans la figure 3.1, où on trouve le nombre de syntagmes nominaux avec et sans doublons, le nombre de mots, de paragraphes, de lignes et de pages dans chaque article.
Le nombre de syntagmes nominaux avec doublons tient compte de la multiplicité d’occurrence d’un même syntagme nominal dans un article donné, tandis que le nombre de syntagmes nominaux sans doublons ne le fait pas. On a constaté par ailleurs qu’il y a des doublons qui peuvent apparaître ou non sur l’ensemble des syntagmes nominaux appartenant à plus d’un article différent. La colonne des syntagmes nominaux sans doublons ne tient pas compte de cet aspect là.
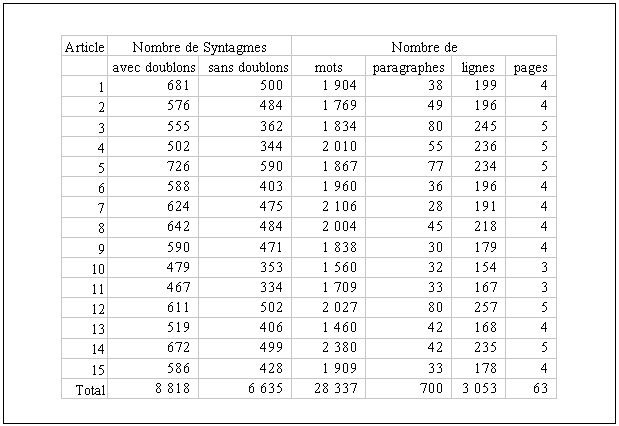
A partir de ce tableau et en tenant compte du nombre de syntagmes nominaux avec doublons (cette variable a été prise parce qu’elle représente la totalité de syntagmes nominaux d’un article), on arrive aux moyennes suivantes :
- Nombre moyen de syntagmes nominaux par lignes = 2,88
- Nombre moyen de syntagmes nominaux par paragraphe = 12,60
- Nombre moyen de syntagmes nominaux par page 67 = 139,96
- Nombre moyen de mots par syntagmes = 3,21
On a utilisé la moyenne bien que l’on sache qu’il s’agit d’une mesure d’utilité douteuse pouvant être facilement influencée par une valeur trop grande (ou trop petite) lui faisant perdre complètement sa représentativité. Le but de la présentation du tableau des moyennes n’est pas de chercher une relation entre les variables, mais de décrire le travail d’extraction des syntagmes nominaux. Concernant les moyennes il faut tenir compte des aspects suivants :
- La taille des paragraphes varie largement. On trouve des paragraphes avec une seule ligne et d’autres avec dix lignes ou plus. Cet aspect dépend du style de rédaction des auteurs ;
- En ce qui concerne la taille des pages, on peut dire qu’elle présente presque le même problème, étant donné que les dernières pages de chaque article ne sont pas toujours pleines ;
- A propos du nombre moyen de syntagmes nominaux par ligne, bien que l’on trouve des lignes remplies à moitié, elles apparaissent en générale complètes ;
- Au sujet du nombre moyen de mots par syntagmes nominaux, on peut croire qu’il représente plutôt les syntagmes de premier et de deuxième niveau et à la rigueur ceux de troisième niveau, mais en aucun cas il ne s’agirait des syntagmes de quatrième et de cinquième niveau. Ces derniers sont très longs, composés quelquefois de vingt mots ou plus. Ainsi, pour obtenir une valeur plus fiable il aurait fallu faire ce calcul plutôt à chaque niveau.
Pour une analyse plus approfondie et si l’on envisage de trouver des relations entre les variables présentées dans la figure 3.1, un travail spécifique mérite d’être faite en considérant des critères plus orientés vers ce type d’étude.
En ce qui concerne la procédure d’extraction des syntagmes nominaux, nous avons découvert quelques points assez importants qui se prêtent à des études plus approfondies. Ce sont :
Bien qu’on ait adopté des solutions pour chacun de ces points, l’analyse et la formalisation de solutions définitives sont indispensables.
« Il n'y a pas de grandeur pour qui veut grandir. Il n'y a pas de modèle pour qui cherche ce qu'il n'a jamais vu. »
Eluard (Eugène Grindel, dit Paul), L'Évidence poétique (Gallimard).