Chapitre 9
Grammaire de Référence
1 Considérations préliminaires
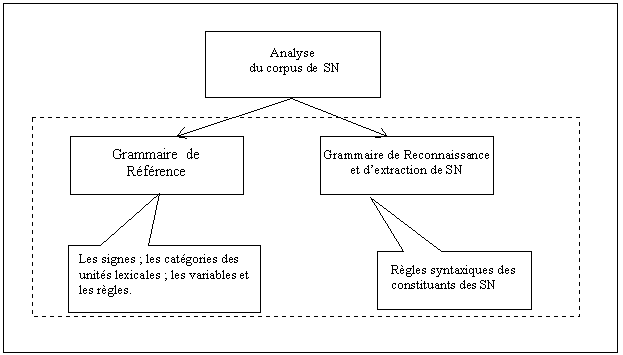
Tout d’abord, le but de cette partie de la thèse est d'établir un modèle pour la construction d’un système automatique de reconnaissance et d’extraction des syntagmes nominaux (SN) dans un ensemble de documents textuels écrit en langue portugaise. Ce modèle sera composé de deux modules : 1) module de description lexicale, appelé Grammaire de Référence ; et 2) module Grammaire de Reconnaissance et d’Extraction de SN. La figure 9.1 montre le schéma de développement de ce modèle.
La démarche utilisée pour la construction de ce modèle est partie de l’analyse du corpus des SN extraits lors de la construction de la maquette développée dans le cadre du cours de DEA 97 .
La Grammaire de Référence contient les caractéristiques, des unités lexicales, nécessaires à la reconnaissance d’un SN. Comme caractéristiques, grosso modo, on trouve : 1) la catégorie de l’unité lexicale ; 2) variables et règles nécessaires pour lever l’ambiguïté sur une unité lexicale au moment de la reconnaissance des unités lexicales dans la procédure d’extraction des SN. La Grammaire d’extraction contient les règles syntaxiques pour la reconnaissance et l’extraction des SN.
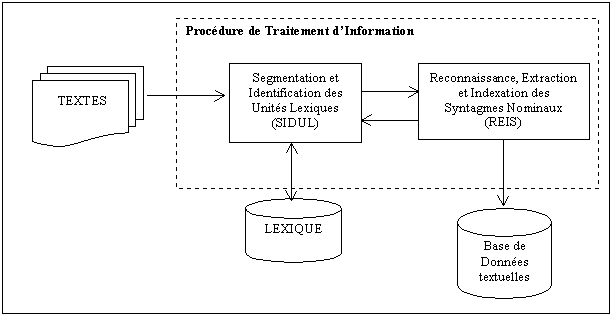
Ce modèle servira de base pour le développement de l’analyseur morpho-syntaxique. La figure 9.2 montre, grosso modo, le schéma de fonctionnement de la Procédure de Traitement d’Information (PTI). Il y aura deux grands modules : 1) Module de Segmentation et d’Identification des Unités Lexicales (SIDUL) ; 2) Module de Reconnaissance, d’Extraction et d’Indexation des Syntagmes Nominaux (REIS). Le module SIDUL segmente le texte, utilise et fait la mise à jour de la base de données LEXIQUE pour l’identification des unités lexicales. Le module REIS utilise les informations de l’unité lexicale trouvées par le SIDUL pour la reconnaissance et extraction des syntagmes nominaux. Le module REIS est, donc, composé de deux sous-modules, un qui est responsable pour l’analyse morpho-syntaxique et l’autre qui est responsable pour l’organisation des SN, c’est-à-dire, pour l’indexation automatique. Le schéma de la figure 9.2 est légèrement différent de celui de la figure 8.2 car dans cette section il fallait mettre en évidence la segmentation de texte et l’identification.
La base de données LEXIQUE contiendra toutes les unités lexicales, trouvés dans les textes analysés, avec leurs caractéristiques. Celles qui sont décrites dans la Grammaire de Référence, que nous définirons dans ce chapitre. La mise à jour est faite au fur et à mesure que les textes seront traités et indexés. Le début sera un peu difficile car il y aura une grande quantité d’unités à caractériser et à inclure dans la base LEXIQUE. A partir d’une certaine quantité de documents traités, le volume d’unités lexicales à inclure dans la base LEXIQUE doit diminuer sensiblement.
La proposition de ce travail est de garder les unités lexicales dans toute leur forme propre, on ne fera pas ce qu’on appelle de lemmatisation 98 . Aujourd’hui les modules de mémoires secondaires (les disques durs) ne sont pas chers et sont très rapides. Ainsi, on peut utiliser un logiciel de gestion de bases de données relationnelles pour créer cette base de données au lieu de développer un analyseur morphologique basé sur la lemmatisation. Une autre solution serait de chercher un système qui ferait la segmentation du texte et l’analyse morphologique. Or, cela peut ne pas être une bonne solution car il faut faire beaucoup d’efforts pour s’adapter aux contraintes du logiciel choisi. Ce genre de logiciel est normalement une sorte de boîte noire. De plus, on reste toujours dépendant du constructeur du logiciel. Dans l’approche présentée ici, le module de reconnaissance et d’extraction des syntagmes nominaux fait un échange fréquent avec le module SIDUL. Ainsi, il faut que le module SIDUL (à développer) ou un logiciel analogue (déjà prêt) soit capable de s’intégrer dans le module REIS. Il ne s’agit pas de deux procédures isolées. Ainsi, la meilleure solution est de concevoir et construire le module SIDUL à partir d’une application basée sur un système de gestion de bases de données relationnelles. La contrainte est que le logiciel de gestion de base de données utilisé soit compatible avec le langage de développement des deux modules : SIDUL et REIS. C’est-à-dire que le langage utilisé, pour la programmation de ces modules, puisse donner accès aux données créées par le système de gestion de bases de données relationnelles.
Le développement d’un système complet de segmentation et d’identification d’unités lexicales, en utilisant le principe de lemmatisation, ne fait pas partie de cette thèse car ce développement demanderait un effort équivalent au développement d’une autre thèse. Cependant, la solution d’utiliser un logiciel de gestion de bases de données relationnelles nous semble bonne. Ce qui importe dans cette recherche c’est la définition d’un analyseur morpho-syntaxique capable de fournir des informations pour l’identification et l’extraction des syntagmes nominaux.
La Grammaire de Référence des unités lexicales est important pour la création de la base de données LEXIQUE, tandis que les règles de la grammaire d’extraction de syntagmes nominaux feront partie des algorithmes du REIS, le module qu’inclut l’analyseur morpho-syntaxique.
Dans ce chapitre nous présenterons la grammaire de référence des unités lexicales et nous proposerons une structure de données pour la construction de la base de données LEXIQUE.