3 Etablissement de la Grammaire de référence
La procédure d’identification et d’extraction des syntagmes nominaux passe d’abord par la reconnaissance de leurs constituants, leurs unités lexicales. Or, la reconnaissance de ces constituants n’est pas une tâche facile, outre les ambiguïtés des unités lexicales dont nous avons parlé (la synonymie et la polysémie), il y a ambiguïté par rapport au rôle qu’elles peuvent jouer dans une phrase. Exemples de ces problèmes : les cas de quelques unités lexicales qui peuvent jouer le rôle d’un substantif (nom) dans un contexte et, d’adjectif dans un autre. De plus, dans la grammaire traditionnelle on trouve des mots classés dans une catégorie qui en fait, jouent le rôle d’une autre catégorie. Par exemple des participes utilisés souvent à la place d’un adjectif, des pronoms toniques qui occupent souvent la place d’un nom substantif.
M. LE GUERN soutiens que ‘ « La question des parties du discours se situe, le plus souvent de manière implicite, à l’articulation du lexique et de la syntaxe. Il s’agit, en effet, de déterminer les sous-ensembles du lexique contenant les éléments qui se voient assigner dans le discours le même comportement syntaxique. » ’ 105
Par ailleurs, comme en français, on trouve aussi dans la langue portugaise les articles contractés, c’est-à-dire les mots qui sont composé d’une préposition et d’un article (de + article, em + article ou por + article) :
- da
- de + a (de la) ;
- do
- de + o (du) ;
- na
- em + a (en la) ;
- no
- em + o (en le) ;
- pelo
- por + o (par le).
Le problème est de savoir comment classer ces unités lexicales ou plutôt comment les traiter. Où doit-on les classer si on utilise les catégories de la grammaire traditionnelle ? Est-ce qu’il faut créer une catégorie « ad-hoc », appelée Articles Contractés ? Or, ce genre de mots est formé à partir de deux autres mots qui appartient, en fait, à des catégories déjà existantes.
La création d’une classe « ad-hoc » ‘ « …n’apporte et ni retranche aucune information structurale par rapport aux formes de surface … et ne peut donc constituer, pour l’analyse syntaxique, une meilleure base de départ que ces formes elles-mêmes. » ’ 106 . A quoi sert cette catégorisation des unités lexicales ? La catégorisation des mots devrait prendre en compte le but du traitement de ces unités. Ce sont quelques arguments utilisés par Alain BERRENDONNER pour montrer le besoin d’avoir un système de classification, plus homogène et qui puisse servir non seulement à une tâche purement classificatoire, mais aussi à d’autres finalités comme celle de l’analyse syntaxique, de l’indexation automatique etc. Ainsi, Alain BERRENDONNER a établi deux principes de base pour la construction d’un analyseur morphologique : 1) ‘ « il faut commencer par définir explicitement et rigoureusement un ensemble de conditions auxquelles doit satisfaire son produit de sortie R, compte tenu des fonctions qu’on envisage de lui confier dans la suite du traitement. » ’ ‘ 107 ’ ‘ ; 2) Le second principe est que définir ainsi un produit de sortie pour l’AM, c’est, du même coup, choisir une grammaire de référence : R la représentation visée est un certain type d’analyse linguistique du texte T, e formuler certaines exigences explicites à propos de R revient à sélectionner, parmi toutes les grammaires de références possibles, celle qui est capable de générer une représentation conforme à ces exigences. » ’ 108 .
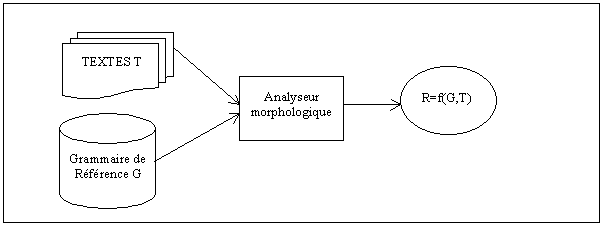
Ces deux principes peuvent être représentés par le schéma de la figure 9.3 (schéma emprunté à l’ouvrage d’Alain BERRENDONNER cité plus haut), montrant le rapport entre les éléments d’entrée et de sortie avec l'analyseur morphologique. Le résultat R est fonction du Texte T et de la grammaire de référence G.
Ainsi, dans ce travail la grammaire de référence donnera la définition d’un ensemble de caractéristiques nécessaires à repérer, pour chaque unité lexicale (mot, mot composé), en vue de faciliter l’identification d’un syntagme nominal. Ces caractéristiques sont des informations spécifiques à chaque unité lexicale, comme sa catégorie grammaticale, sa flexion en genre, en nombre, sa personne parmi d’autres spécificités.
Comme il a été déjà signalé, nous allons utiliser comme base pour ce travail l’approche développée par Alain BERRENDONNER pour la langue française. D’abord, ses arguments nous semblent très pertinents et il a réussi à construire un modèle de classification beaucoup plus homogène, cohérent et enrichi que celui de la grammaire traditionnelle. Le produit de son travail est, donc beaucoup plus approprié au traitement automatique de textes, soit pour la reconnaissance et extraction des syntagmes nominaux, soit pour une analyse syntaxique.
La langue portugaise ressemble beaucoup à la langue française, elles ont la même origine, leurs structures grammaticales sont pareilles. Cependant, comme toutes les langues, le portugais a quelques spécificités qui marquent une différence.
Le modèle proposé demande la régularisation de toutes formes d’amalgames à travers leur décomposition suivant leurs composants primitifs étant donné que ces composants sont déjà classés dans des catégories existantes dans la grammaire de référence. Ainsi, il faut faire un pré-traitement de ces unités lexicales, comme par exemple les articles contractés (ao, do, da, à, etc.), comme les amalgames préposition + pronom démonstratif (daquele de + aquele, naquele em + aquele, etc) parmi d’autres cas. Le pré-traitement peut être réalisé soit comme un premier balayage sur tout le texte soit au fur et à mesure qu’on traite chaque unité lexicale. La dernière option est plus intéressante du point de vue de vitesse de traitement, tandis que la première oblige à faire deux parcours sur le même texte, ce qui demande un peu plus de temps.
S’on choisit de faire le pré-traitement au moment de l’identification de chaque unité lexicale, il faut encore savoir comment le faire, on peut mettre les formes contractées dans la base de données LEXIQUE ou les déclarer dans le module de Segmentation et Identification d'Unités Lexicales (SIDUL). La première solution est, à notre avis, la meilleure, étant donné l’avantage de construire un module SIDUL plus indépendant des données lexicales. Le seul inconvénient est le temps de traitement qui peut rendre l’analyse un peu plus lente. Il est vrai que la deuxième voie serait une solution plus rapide en ce qui concerne le temps de traitement de données. Cependant, elle rend le module SIDUL plus particulier puisque toutes les contractions ou amalgames y sont mis. Il faudra, donc, le changer chaque fois qu’on aura besoin d’inclure une nouvelle forme de contraction. Ce qui peut rendre le logiciel d’analyse un peu gourmand par rapport à l’utilisation de la mémoire.