1.2. Profils et temps lexicaux
1.2.1. Spécificités et écarts réduits
Se donner pour objectif de compter les formes d’un texte ne prend toute sa dimension qu’avec la procédure que l’on va retenir pour effectuer ces mesures. Dans notre cas, il s’agit de l’écart réduit. Mais un calcul, quel qu’il soit, n’a aucune valeur en soi sans l’adjonction de repères ou de points fixes de comparaison. Etant donné qu’une fréquence “en langue” n’a aucun sens - ‘“la langue permet de fabriquer des fréquences, elle n’est pas fréquentielle en elle-même”’ 111 -, il va donc falloir utiliser une norme que l’on a pris l’habitude de qualifier d’“endogène”, autrement dit une norme interne au corpus et réduite à lui. Les quatre parties “naturelles” que l’on a isolées dans l’existence de Lyon-Libération trouvent ici leur pleine “mesure”. L’intérêt consiste en effet à dresser, pour chacune des formes de notre corpus parvenues à un certain seuil, une sous-fréquence théorique dans chaque partie. Pour obtenir ces sous-fréquences théoriques, il faut au préalable calculer la fréquence relative de chaque forme, autrement dit sa probabilité p d’apparaître dans une partie du corpus (et, concomitamment, sa probabilité q de ne pas s’y trouver). Examinons de plus près ce qui est en jeu ici.
Sachant que la ventilation de la totalité des formes dans les quatre périodes de notre corpus est la suivante :

nous obtenons pour chaque partie du corpus les valeurs - arrondies - suivantes (on remarquera au passage la quasi-équivalence entre les deux premières périodes) :
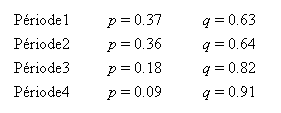
La valeur de l’écart réduit est calculée de la manière suivante :

Soit n le nombre total d’occurrences d’une forme dans le corpus et np sa fréquence théorique.
La fréquence réelle de cette forme est égale au nombre d’occurrences qu’elle comporte dans chaque partie du corpus. Un exemple tiré du texte que nous avons soumis à l’ordinateur devrait clarifier ce qui pourrait encore rester flou. La forme « capitale » possède 23 occurrences ainsi réparties dans l’ensemble du corpus :
Période1 = 11 oc. ; Période2 = 8 oc. ; Période3 = 4 oc. ; Période4 = 0 oc.
Pour la première période, la valeur de l’écart réduit sera donc :

En procédant au même calcul sur les périodes successives, on obtient les écarts réduits suivants : -0.1 ; -0.1 ; -1.5. En statistique, il faut savoir qu’une hypothèse, pour être validée, est toujours opposée à ce qu’on appelle l’hypothèse nulle, fondée sur le libre jeu du hasard :
‘On définit toujours un intervalle à l’intérieur duquel il serait imprudent de rejeter l’hypothèse nulle et de valider l’hypothèse contraire, cet intervalle est appelé l’intervalle d’acceptation ou le seuil de rejet. Autrement dit, il s’agit de montrer qu’un résultat n’est pas le seul fruit du hasard mais qu’il peut être au contraire expliqué par une cause non aléatoire.112 ’La norme en la matière est de considérer un écart réduit comme significatif quand il est ≥2 en valeur absolue. En recourant à une table d’écarts réduits, on constate en effet qu’à un écart de 2 correspond une probabilité de 0,046. Ce qui revient à dire qu’il y a 4 (ou... 4,6) chances sur 100 de se tromper en considérant un écart à la moyenne comme significatif et que le résultat ne peut pas être expliqué par une cause aléatoire fondée sur le libre jeu du hasard. Une forme sera par conséquent définie comme spécifique dès qu’elle aura atteint ou dépassé le seuil de deux écarts réduits. Dans le cas d’un écart positif, le terme est privilégié, c’est-à-dire en excédent. Dans le cas contraire, il est sous-représenté ou en déficit. Maurice Tournier a bien mis en valeur que les fréquences sont par essence relatives puisque déterminées à l’aune d’une norme endogène. Dans ces conditions, il ne faudra pas s’étonner de voir une forme particu-lièrement sur-employée dans une partie du corpus l’être en sens contraire dans une ou plusieurs autres113. Pour en revenir à notre exemple, on peut observer qu’aucun écart réduit de la forme « capitale » n’est ≥2 en valeur absolue. Il n’y a donc pas lieu de rejeter l’hypothèse nulle, ce qui nous amène à dire que son emploi est banal dans le discours éditorial de Lyon-Libération. Banal mais non commun puisque cette forme est absente de la dernière période rédactionnelle. Pierre Lafon nous semble avoir résumé avec à propos ce qui est en jeu dans une analyse mesurée du lexique : ‘“Formes communes et formes de base possèdent chacune un aspect de la généralité, tandis que du côté de la particularité, l’originalité représente une forme achevée de spécificité”’ 114. Par forme originale, il faut entendre une forme dont toutes les occurrences sont condensées à l’intérieur d’une des parties qui composent un corpus (la forme originale par excellence est à ce titre l’hapax, autrement dit celle qui ne compte qu’une seule occurrence dans tout le corpus). Par formes de base, l’auteur entend désigner ‘“les formes qui ne présentent aucune spécificité, celles en somme dont les fluctuations ne dépassent pas un niveau que le hasard pourrait seul assumer”’ 115. Elles procèdent donc bien de la généralité : leur présence dans un discours ‘“est à proportion ajustée à sa longueur”’ 116. Il n’empêche que toutes banales qu’elles soient (nous pourrions dire encore invariantes), ces formes n’en sont pas pour autant obligatoirement communes. Autrement dit, leurs occurrences ne se trouvent pas nécessairement réparties dans chaque partie d’un corpus. Mais Pierre Lafon a montré, à la lumière des approches quantitatives, que la généralité révèle une réalité plus complexe qu’on ne pourrait le penser de prime abord. Autrement dit, ce n’est pas parce qu’elle est commune qu’une forme échappe à toute spécificité et même, aussi paradoxal que cela puisse paraître, ‘“de nombreuses formes communes se trouvent aussi être spécifiques”’ 117. Pierre Lafon en arrive à la conclusion que s’il est intéressant de dresser la liste des formes non spécifiques, c’est avant tout à l’aune des formes communes qu’il convient de le faire. Nous avons donc procédé de la sorte vis-à-vis de formes qui se prêtent particulièrement bien à ce repérage : les noms propres (que le codage a pris soin de conforter comme “désignants rigides”) et les désignants territoriaux dont il est permis d’apprécier une double configuration d’emploi, pour chacun pris isolément, selon qu’il est employé au singulier ou au pluriel.
Il est encore à noter qu’il nous arrivera d’affiner le constat de spécificité en procédant à de nouveaux calculs d’écarts réduits à partir des occurrences d’une forme sur-employée qui répondent à un critère commun, comme celui par exemple de prendre place dans une même expression (ce qu’au laboratoire de Saint-Cloud, on désigne comme des “polyformes”). Ce calcul de “sous-spécificités”, en quelque sorte, ne peut être mené à bien qu’à condition d’une part de prendre en compte la récurrence d’un phénomène identique à l’échelle du corpus entier, sans quoi le calcul de l’écart réduit est rendu obsolète, et d’autre part que ce “retour du même” soit suffisamment fréquent. Il faut bien garder à l’esprit que cette manière de procéder ne “crée” pas de nouveaux items dont la prise en compte serait à même de remettre en cause le découpage initial du texte. Les fréquences relatives des formes, autrement dit leur probabilité d’apparaître dans chaque période rédactionnelle, restent les mêmes. Le fait d’isoler une polyforme maintient leur autonomie à chacune des formes qui la compose. Calculer les écarts réduits de « il a » dans les quatre parties du corpus ne revient pas à indexer un nouveau terme « il a » dans le dictionnaire mais à mesurer la probabilité d’emploi de « il » lorsqu’il est suivi de « a » ou, de la même façon et dans le même temps, de « a » lorsqu’il est précédé de « il »118. Si nous avons réservé ces calculs supplémentaires à des combinaisons mettant en jeu deux formes (rarement au-delà) accolées, il nous est arrivé toutefois en certains cas de procéder à un découpage s’appuyant sur les différentes significations du terme lui-même et non plus sur son positionnement dans la chaîne du discours.
Nous pourrions dire in fine que l’intérêt majeur de l’écart réduit réside dans le fait qu’il est un écart à la moyenne pondéré en fonction de la longueur respective de chaque partie du corpus, ce qui ne nécessite aucun équilibrage préalable. Autant dire qu’il était particulièrement adapté à notre corpus, dont on a pu constater la dissymétrie appuyée entre la dernière période et les deux premières par exemple. Il est important de souligner cependant que les spécificités n’ont un sens que si l’on opère sur des formes suffisamment employées, autrement dit dont les fréquences théoriques garantissent la validité des écarts réduits. Pour notre corpus, seules les formes - retenues pour l’analyse - dont la fréquence est supérieure à 10 ont été soumises au test probabiliste en vue d’en apprécier les profils d’emploi au gré des quatre périodes rédactionnelles119.