4 VERS L’IDENTIFICATION AUTOMATIQUE DES PARLERS ARABES
4.1. Historique et Enjeux de l’Identification Automatique des Langues
‘« Each domain has its Holy Grail, and Automatic Speech recognition is ours » (Flanagan, 1976).’La phrase de Flanagan citée en exergue illustre bien à la fois la difficulté et l’attrait de la reconnaissance automatique de la parole. Quel est donc cet étrange problème, que le travail d’un nombre de plus en plus important de chercheurs et d’ingénieurs, de phonéticiens et d’informaticiens, pendant près de quarante ans, n’a pas encore suffi à résoudre en totalité ?
L’identification Automatique des Langues, discipline née dans les années soixante-dix, est devenue un domaine majeur de la communication parlée. Son objectif est d’identifier — par le biais d’un système informatique — la langue utilisée par un locuteur inconnu pendant un temps plus ou moins long. Les recherches dans ce domaine ont été initiées aux Etats-Unis par la firme Texas Instruments, à la demande du Ministère de la Défense Américain (DoD), et se sont poursuivies avec plus ou moins d’intensité jusqu’à aujourd’hui.
Les années quatre-vingt dix ont vu s’accentuer l’intérêt pour l’IAL. Depuis cette date, un grand nombre d’études traitant de ce sujet ont été publiées (Muthusamy & al., 1994 et Muthusamy & al., 1997) et les performances des systèmes développés actuellement sont plus qu’encourageantes. Ce regain d’intérêt pour l’IAL s’explique essentiellement par l’attrait des applications possibles en Traitement Automatique de la Parole (TAP) et l’envergure des multiples enjeux qui s’y rapportent. Au niveau scientifique, les recherches en IAL peuvent s’avérer intéressantes dans le cadre des sciences cognitives dont on observe aujourd’hui le développement. En effet, les processus mis en oeuvre par l’enfant lors de l’acquisition de la langue maternelle soulèvent des questions encore sans réponses quant aux traits distinctifs utilisés au niveau cognitif63. L’analyse conjointe des mécanismes mis en oeuvre par un système d’IAL et des structures linguistiques d’une langue pourrait aider à la formulation d’hypothèses concernant l’émergence de certains traits phonologiques.
De la même manière, les systèmes d’IAL pourraient jouer un rôle important dans le cadre de l’enseignement des langues étrangères et pour l’analyse des phénomènes d’inter-langues. On pourrait imaginer de développer des systèmes automatiques prenant à leur charge la correction des productions orales des étudiants : plus le locuteur se perfectionne, plus son discours s’éloigne du modèle de la langue maternelle pour se rapprocher de celui de la langue étrangère.
Les enjeux économiques s’avèrent eux aussi de plus en plus importants. Dans le contexte de mondialisation des systèmes de communication que l’on connaît aujourd’hui, le TAP tend en effet à prendre une place prépondérante au sein de la société où il trouve des applications diverses, couvrant à la fois des domaines aussi variés que la Défense Nationale (interception et traduction de conversations téléphoniques), le Commerce (transactions internationales) et la Santé Publique (avec pour application principale l’orientation des appels de détresse dans les standards hospitaliers d’urgence, existant déjà aux Etats-Unis avec le célèbre numéro 911 où des standardistes humains réalisent la tâche d’identification linguistique avant de diriger l’appel vers des traducteurs spécialisés dans la langue en question). Les applications vocales et multimodales (serveurs vocaux, systèmes de dictée vocale, bornes interactives d’information, etc.) connaissent également un développement impressionnant.
Il est évident que dans le contexte actuel le multilinguisme est une réalité incontestable et qu’on ne peut plus se contenter de traiter exclusivement les langues de grande diffusion telles que l’anglais, le français, l’allemand, l’espagnol, le portugais, l’italien et le japonais comme c’est encore souvent le cas. De plus, les langues parlées sur des espaces couvrant plusieurs milliers de kilomètres carrés se déclinent souvent sous des formes dialectales particulières que les systèmes d’IAL actuels se doivent de prendre en compte.
Comme nous l’avons rappelé précédemment, l’objectif d’un système d’IAL est de déterminer automatiquement — à partir d’un énoncé plus ou moins court et prononcé par un locuteur inconnu — la langue qui est employée. Dans ce cadre, deux approches sont a priori envisageables.
On peut d’une part chercher à comprendre l’énoncé, et donc à reconnaître le contenu sémantique véhiculé par une séquence d’unités lexicales. On se situe alors dans le cadre de la compréhension multilingue, pour lequel il est nécessaire de disposer d’un module de reconnaissance de la parole continue pour chacune des langues considérées (Lamel & al., 1996).
Une autre approche consiste à rechercher dans le signal acoustique des indices caractéristiques des langues (et/ou des dialectes) en faisant abstraction du sens du message. C’est cette dernière approche — par identification d’unités discriminantes — qui est actuellement la plus employée en IAL car elle présente l’avantage de pouvoir être appliquée à des langues pour lesquelles on ne dispose pas encore de systèmes de compréhension.
L’approche par identification repose donc sur la détermination d’indices discriminants pertinents pour la distinction des langues entre elles (ou des dialectes entre eux). Ces caractéristiques linguistiques particulières peuvent être recherchées à tous les niveaux de la langue :
-
acoustico-phonétique (i.e. nature des sons et fréquence d’occurrence attribuée à chacun d’eux dans le système de la langue)
-
phonotactique (i.e. règles d’enchaînement des unités phonétiques)
-
phonologique (organisation systématique des unités phonétiques)
-
prosodique (organisations rythmiques et/ou motifs mélodiques)
-
lexical (recherche de mots fréquents dans le vocabulaire)
-
morpho-syntaxique (organisation des unités dans la chaîne parlée), etc...
Selon la tâche d’identification effectuée, certains de ces niveaux s’avèrent plus adaptés pour une tâche d’identification automatique de la langue à partir du signal de parole. Les indices les plus souvent pris en compte en IAL sont empruntés au champ plus général de la reconnaissance automatique de la parole (RAP). Il s’agit plus spécifiquement d’indices de nature(s) acoustico-phonétique et/ou phonotactique.
Les systèmes actuels les plus performants sont basés sur la modélisation statistique de ces indices (Modèles de Markov Cachés et grammaires statistiques n-grammes (Rabiner, 1983 ; Calliope, 1989 ; Carré & al., 1991).
La méthode consiste, pour chacune des langues à traiter, à élaborer un — ou plusieurs — modèles phonétique et phonotactique à partir d’enregistrements acoustiques dits d’apprentissage, puis à comparer les modèles ainsi obtenus avec l’énoncé à identifier (issu d’un corpus de test), dans le but de déterminer lequel est le plus probable (approche probabiliste) (Kadambe, 1994 ; Zissman, 1996).
Cette approche statistique nécessite de disposer d’enregistrements pour un très grand nombre de locuteurs, et ce pour chacune des langues à traiter de manière à obtenir des modèles d’apprentissage robustes. A ce facteur, s’ajoutent deux autres aspects essentiels influençant fortement les performances des systèmes: le nombre de langues traitées et la durée des énoncés dont on dispose pour effectuer la tâche d’identification.
De manière générale, la nature des langues traitées est aujourd’hui fortement limitée aux langues de grande diffusion64. Le coût engendré par la constitution d’un corpus linguistique étant très important, les bases de données disponibles sont peu nombreuses (Tableau 53).
| CORPUS MULTILINGUES DISPONIBLES | |||||||
| CALLFRIEND | CALLHOME | EUROM_11 | GLOBAL PHONE | IDEAL | OGI 22 | OGI MLTS | |
| Langues & dialectes representés | * Allemand * Anglais américain * Arabe égyptien * Coréen * Espagnol (Caraïbes) * Espagnol (autre) * Farsi * Français canadien * Hindi * Japonais * Mandarin * Mandarin (Taïwan) * Tamoul * Vietnamien |
* Allemand * Anglais américain * Arabe égyptien * Espagnol * Japonais * Mandarin |
* Allemand * Anglais * Danois * Espagnol * Français * Grec * Hollandais * Italien * Norvégien * Portugais * Suédois |
* Arabe * Chinois * Coréen * Croate * espagnol * Japonais * Portugais * Russe * Turc |
* Allemand * Anglais (GB) * Espagnol *Français |
* Allemand * Anglais * Arabe (oriental) * Cantonais * Coréen * Espagnol` * Farsi * Français * Hindi * Hongrois * Italien * Japonais * Malais * Mandarin * Polonais * Portugais * Russe * Suédois * Swahili * Tamoul * Tchèque * Vietnamien |
* Allemand * Anglais * Coréen * Espagnol * Farsi * Français * Hindi * Japonais * Mandarin * Tamoul * Vietnamien |
| Noimbre de langues | 12 langues 3 dialectes |
6 langues | 11 langues | 9 langues | 4 langues | 22 langues | 11 langues |
| Type de parole | Conversation | Conversation | Lue | Lue | Spontanée Lue |
Spontanée |
Spontanée |
| Conditions d’enregistre-ment | Téléphone | Téléphone | Studio | Studio | Téléphone | Téléphone | Téléphone |
Bien que forts utiles pour la mise en place d’expériences en IAL et pour l’évaluation des modèles développés dans ce cadre, ces corpus présentent l’inconvénient de ne traiter d’une part, que les langues les mieux décrites dans la littérature linguistique et correspondant aux langues de grande diffusion ; d’autre part de ne prendre en compte — dans la majorité des cas — que les formes standardisées de ces langues en ignorant complètement le fait que la plupart des langues actuellement parlées dans le monde se déclinent sous des formes dialectales plus ou moins ressemblantes. En effet, pour ce qui concerne l’arabe plus spécifiquement, outre le fait que cette langue apparaît encore relativement peu dans les différentes bases en comparaison avec l’anglais, l’allemand, l’espagnol ou le japonais, il est intéressant de constater que la seule variété dialectale représentée est orientale. Il s’agit plus particulièrement du dialecte égyptien. Cette situation ne va pas sans nous rappeler les premiers temps de la dialectologie arabe, où seul le parler du Caire faisait l’objet de recherches spécifiques.
Le dernier facteur de complexité porte sur la durée des énoncés à identifier. Si le locuteur ne prononce que quelques mots (environ 1 seconde de parole), la tâche d’identification linguistique sera difficile, car l’énoncé risque de s’avérer — statistiquement parlant — très peu représentatif de la langue, c’est-à-dire pauvre en unités discriminantes. Ceci implique qu’un enregistrement de plusieurs secondes de parole (environ une dizaine) est souvent souhaitable pour parvenir à un taux d’identification significatif. A l’heure actuelle, la plupart des systèmes d’IAL sont testés avec des enregistrements de 45 secondes.
La plupart des études menées dans le cadre de l’IAL sont basées sur une modélisation markovienne qui permet d’effectuer un décodage acoustico-phonétique du signal. Ces systèmes s’articulent essentiellement autour de deux modules : le premier effectue un décodage acoustico-phonétique de manière à fournir une ou plusieurs séquences d’unités phonétiques discrètes en entrée d’un second module — généralement basé sur une grammaire statistique — qui modélise alors les contraintes phonotactiques de la langue. C’est au niveau de ce second module que la tâche d’identification est réalisée. les différentes étapes effectuées par un système d’IAL sont résumées sur la figure 70.
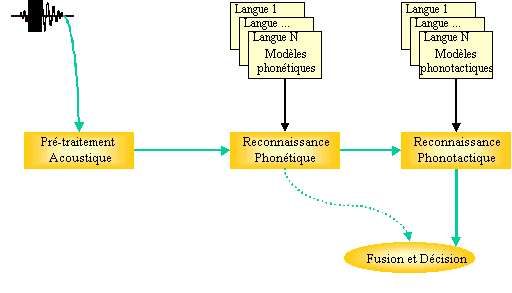
Dans le processus de reconnaissance de la parole, le décodage acoustico-phonétique occupe une place importante. Il reste encore à l’heure actuelle un problème clé du fait de la redondance en informations linguistiques et extra-linguistiques du signal vocal qu’il faut réduire dans des proportions importantes afin d’envisager de le traiter automatiquement.
La principale difficulté tient, pour une grande part, à la variabilité inter et intra locuteurs et à la nature continue — c’est-à-dire très fortement coarticulée — de la parole spontanée. Bien que sur le plan perceptuel, la notion de phonème (i.e. unité élémentaire de son), paraisse naturelle — sauf controverse spécifique, tous les phonéticiens trouveront généralement le même nombre de phonèmes dans un énoncé — il n’existe pas obligatoirement de segment (i.e. portion du signal) qui puisse lui correspondre au niveau acoustique.
Rappelons que, traditionnellement, dans un système de reconnaissance et de compréhension de la parole, un décodeur acoustico-phonétique a pour fonction :
-
d’extraire des paramètres pertinents,
-
de segmenter la parole en unités clairement définies,
-
d’identifier ces unités ou, tout au moins, de leur donner des attributs significatifs.
Certains systèmes à décodage acoustico-phonétique privilégient l’utilisation d’un décodeur unique commun à toutes les langues à traiter. Ce décodeur est construit soit à partir des propriétés phonétiques d’une seule langue (Lund, 1995 ; Hazen, 1997 et Navràtil, 1997), soit à partir d’un ensemble de propriétés couvrant l’espace phonétique de toutes les langues concernées par la tâche d’identification (Berkling, 1995 ; Kwan, 1995, Corredor-Ardoy, 1997).
La seconde approche possible consiste à utiliser en parallèle plusieurs décodeurs dépendants d’une langue et ne correspondant pas nécessairement aux langues à identifier. (Yan, 1996 ; Zissman, 1996).
Le principal avantage de ces dernières méthodes est de réduire considérablement la quantité de données étiquetées nécessaires pour certaines langues, voire de supprimer ce besoin car lorsque l’on ne dispose pas de sources étiquetées pour une langue spécifiquement, on parvient tout de même à la décoder par le biais d’autres systèmes phonétiques plus ou moins ressemblants. Cet avantage est essentiel dans le cas où l’on augmente le nombre de langues à traiter et/ou que l’on travaille sur des langues moins connues. Ceci explique le succès que connaissent aujourd’hui ces méthodes.
Néanmoins, selon Pellegrino (1998), l’ensemble de ces systèmes présentent un inconvénient majeur. En effet, en opérant une projection acoustique des données d’une langue x dans l’espace phonétique d’une langue y, on risque d’aboutir à une perte d’informations qui peut se révéler capitale lors de la tâche d’identification.
Pour pallier ce problème, l’auteur développe dans son travail une méthode originale visant à réaliser une meilleure exploitation de l’identité phonétique des langues à identifier, sans pour autant faire appel à des sources étiquetées. Cette procédure appelée Modélisation Phonétique Différenciée a été appliquée à nos données en arabe dialectal dans le but d’opérer une tâche d’identification dialectale par zones géographiques principales. Avant de présenter les conditions expérimentales spécifiques à notre protocole, nous entendons présenter brièvement les caractéristiques du modèle statistique développé en amont.