4.2. L’approche par Modélisation Phonétique Différenciée
Les meilleures performances en IAL sont actuellement le fruit des modèles phonotactiques dont l’un des principaux avantages est qu’ils peuvent être estimés automatiquement sans nécessiter de données étiquetées spécifiques à la langue à traiter. Comme nous l’avons vu précédemment, de tels systèmes nécessitent néanmoins de disposer d’un — ou de plusieurs — module(s) de décodage acoustico-phonétiques.
Cependant, la conception des décodeurs acoustico-phonétiques constitue une étape particulièrement onéreuse tant au niveau de la collecte des données que sur le plan de l’étiquetage. Bien qu’obtenant — pour onze langues enregistrées en milieu bruité — un bon score d’identification (environ 90%), les systèmes d’IAL actuels sont conçus, comme le souligne Pellegrino (1998), sur la base d’un paradoxe fondamental puisque « l’étape la plus coûteuse du processus (i.e. le décodage acoustico-phonétique) n’est pas explicitement exploitée pour la discrimination des langues, mais implicitement employée comme pré-traitement de la modélisation phonotactique » (Pellegrino, 1998:99).
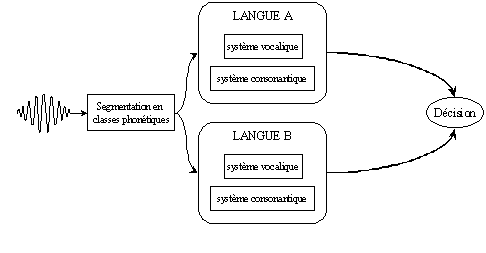
Pour pallier ce manque, l’auteur propose une approche originale visant à utiliser conjointement les modèles acoustico-phonétiques et phonotactiques de manière à exploiter le maximum d’informations. Cette démarche est essentiellement fondée sur l’étude de typologie linguistique développée par Maddieson (1984) et Vallée (1994). Elle vise à distinguer — à l’intérieur des systèmes phonologiques des langues du monde — des classes majeures de sons (i.e. consonnes vs voyelles) de manière à modéliser automatiquement les systèmes phonologiques des langues à traiter. Les sons appartenant à chacune de ces deux classes pouvant être à leur tour répartis en sous-classes — dites naturelles — en fonction de leurs propriétés acoustiques (i.e. voyelle orale vs nasale, consonne plosive vs fricative, etc). Les typologies linguistiques ainsi obtenues peuvent être utiles en IAL car lorsque l’on modélise un ensemble de sons homogènes (comme par exemple, les voyelles), on peut plus facilement prendre en compte certaines contraintes spécifiques (comme, pour le cas des voyelles, les limites de l’espace acoustique dans lequel elles sont produites). Ces remarques ont ainsi mené l’auteur à envisager une modélisation différenciée de chacun des sous-systèmes phonologiques (i.e. système consonantique vs système vocalique). Cette modélisation est, dans un second temps, redéfinie en tenant compte des contraintes liées à la représentation acoustico-phonétique de la parole spontanée (i.e. phénomènes de co-articulation). Le schéma suivant présente les différentes phases opérées lors de l’utilisation d’une telle méthode.
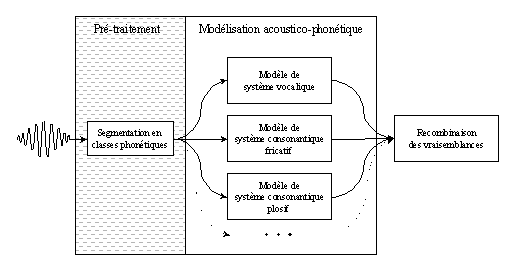
La phase de pré-traitement réalise l’étiquetage des différentes classes retenues à l’aide d’algorithmes de différentes natures (analyse spectrale, modèles statistiques, etc). Afin de rendre possible l’étiquetage automatique, les algorithmes basés sur un apprentissage supervisé65 ont été volontairement écartés. Par ailleurs, de sorte à rendre fonctionnel ce type de modèle sur un nombre indéterminé de langues, les algorithmes retenus sont totalement indépendants de la langue traitée et doivent, pour ce faire, présenter un caractère universel, par exemple, de type consonne vs voyelle ; consonne fricative vs consonne plosive, etc.
Un modèle acoustico-phonétique est alors élaboré pour chacune des classes retenues66 (notion de modélisation différenciée). Ils sont dépendants de chaque langue afin de pouvoir — lors de la phase de reconnaissance — permettre d’estimer la vraisemblance de chaque langue en fonction des caractéristiques acoustiques présentes à l’intérieur du signal de parole testé. Enfin, lorsque les modèles adoptés pour chaque classe phonétique le permettent, on peut exploiter les contraintes phonotactiques de chaque langue dans un modèle de type grammaire n-gramme afin d’obtenir un système d’IAL dont la propriété principale est d’exploiter explicitement les caractéristiques acoustico-phonétiques sans nécessiter l’utilisation de données manuellement étiquetées. A l’heure actuelle, seule la différenciation globale consonne vs voyelle est prise en compte (figure 72).