Notes
67.
L’emphase (ou pour le cas de l’arabe : la pharyngalisation) se définit en effet, du point de vue articulatoire, comme la surimposition d’une articulation secondaire (ici la rétraction de la racine de la langue accompagnée de la restriction de la cavité pharyngale, voir entre autres, Ghazali, 1977b) à une articulation primaire. En arabe, comme nous l’avons déjà vu au cours de ce travail, ce trait de pharyngalisation est phonologiquement associé aux consonnes dentales /t
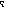 ; d
/, interdentale /
; d
/, interdentale /
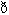 / et/ou sibilantes /s
, z
/. Ce trait peut par ailleurs, s’étendre à d’autres segments (vocaliques et/ou consonantiques) à l’intérieur d’une même unité phonologique (i.e. suite d’un radical et de ses affixes), lui conférant ainsi une coloration toute particulière perceptible à l’oreille et visible sur le signal acoustique au niveau des transitions formantiques. L’analyse acoustique de ce phénomène d’assimilation contextuelle (progressive et/ou régressive) se révèle être le siège d’une grande variabilité dialectale sur le domaine arabophone. Il constitue néanmoins, avec la gémination, l’une des caractéristiques phonologiques les plus originales de l’arabe (et d’une partie des langues sémitiques). Néanmoins, dans leurs travaux visant à identifier les traits phonétiques des consonnes de l’arabe de manière automatique, Boudraa & al. (1994) et Selouani & Caelen (1998) ont montré que les performances des systèmes de reconnaissance automatique pouvaient être améliorés par l’intégration d’un ensemble de sous-réseaux de neurones spécialisés dans l’identification de ces traits phonétiques spécifiquement. Les résultats obtenus montrent que les réseaux d’experts connexionnistes constituent des systèmes d’appoints simples et performants.
/ et/ou sibilantes /s
, z
/. Ce trait peut par ailleurs, s’étendre à d’autres segments (vocaliques et/ou consonantiques) à l’intérieur d’une même unité phonologique (i.e. suite d’un radical et de ses affixes), lui conférant ainsi une coloration toute particulière perceptible à l’oreille et visible sur le signal acoustique au niveau des transitions formantiques. L’analyse acoustique de ce phénomène d’assimilation contextuelle (progressive et/ou régressive) se révèle être le siège d’une grande variabilité dialectale sur le domaine arabophone. Il constitue néanmoins, avec la gémination, l’une des caractéristiques phonologiques les plus originales de l’arabe (et d’une partie des langues sémitiques). Néanmoins, dans leurs travaux visant à identifier les traits phonétiques des consonnes de l’arabe de manière automatique, Boudraa & al. (1994) et Selouani & Caelen (1998) ont montré que les performances des systèmes de reconnaissance automatique pouvaient être améliorés par l’intégration d’un ensemble de sous-réseaux de neurones spécialisés dans l’identification de ces traits phonétiques spécifiquement. Les résultats obtenus montrent que les réseaux d’experts connexionnistes constituent des systèmes d’appoints simples et performants.
; d
/, interdentale /
/ et/ou sibilantes /s
, z
/. Ce trait peut par ailleurs, s’étendre à d’autres segments (vocaliques et/ou consonantiques) à l’intérieur d’une même unité phonologique (i.e. suite d’un radical et de ses affixes), lui conférant ainsi une coloration toute particulière perceptible à l’oreille et visible sur le signal acoustique au niveau des transitions formantiques. L’analyse acoustique de ce phénomène d’assimilation contextuelle (progressive et/ou régressive) se révèle être le siège d’une grande variabilité dialectale sur le domaine arabophone. Il constitue néanmoins, avec la gémination, l’une des caractéristiques phonologiques les plus originales de l’arabe (et d’une partie des langues sémitiques). Néanmoins, dans leurs travaux visant à identifier les traits phonétiques des consonnes de l’arabe de manière automatique, Boudraa & al. (1994) et Selouani & Caelen (1998) ont montré que les performances des systèmes de reconnaissance automatique pouvaient être améliorés par l’intégration d’un ensemble de sous-réseaux de neurones spécialisés dans l’identification de ces traits phonétiques spécifiquement. Les résultats obtenus montrent que les réseaux d’experts connexionnistes constituent des systèmes d’appoints simples et performants.