4.5.3. Résultats et discussion
Nos résultats — bien que relativement peu significatifs d’un point de vue statistique compte tenu du faible nombre d’enregistrements disponibles pour l’élaboration des modèles d’apprentissage — révèlent des tendances générales intéressantes que nous nous proposons de présenter dans le présent paragraphe. Il conviendrait naturellement d’observer leur évolution à partir d’un corpus d’apprentissage plus complexe et de tester ces critères sur un ensemble de données plus large afin de confirmer leur robustesse. Considérons dans un premier temps les résultats obtenus en fonction du nombre de classes gaussiennes retenus (Figure 75).
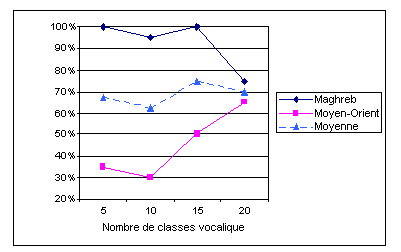
Les modèles composés d’un faible nombre de classes gaussiennes distinguent assez mal les deux zones dialectales représentées dans les différents stimuli : la plupart des échantillons de parole sont ainsi identifiés comme étant de l’arabe maghrébin (cf. le taux d’identification élevé pour la catégorie Maghreb et le faible score correspondant à l’identification de la zone orientale). Cette tendance sous-entend qu’un modèle plus complexe (i.e. comportant un nombre de classes vocaliques supérieur) est nécessaire pour parvenir à caractériser de manière plus fine l’organisation vocalique des parlers orientaux. Toutefois, quand la taille du modèle augmente cet effet tend à disparaître et l’on obtient, avec le nombre — ici optimal — de 20 classes vocaliques, un score d’identification par zone de 70 %. L’utilisation du test statistique de Pearson (Khi2) établit que ce score est significativement supérieur à la chance (P χ2 > 3.84) = .05. Le T-Test effectué sur les taux d’identification moyens obtenus pour chaque zone dialectale ne révèle quant à lui aucune différence significative, ce qui prouve que le modèle est aussi performant pour la discrimination de l’une et l’autre des deux aires dialectales à identifier. Si l’on compare ces résultats avec ceux obtenus à partir d’un apprentissage fondé conjointement sur les caractéristiques spectrales et sur la durée des segments vocaliques, on observe que — dans ce dernier cas et pour le même nombre de composantes gaussiennes — les scores d’identification correcte atteignent 78 %, (Figure 76).
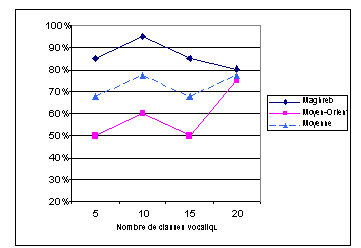
Toutefois, il est important de souligner que les taux d’identification correcte obtenus avec des modèles de petites tailles sont sensiblement meilleurs lorsque l’on prend en considération l’information de durée vocalique, c’est-à-dire que la modélisation des systèmes vocaliques s’effectue dans à un espace à neuf dimensions plutôt que huit. Ainsi, alors que le taux correspondant à l’identification de la variété occidentale reste élevé, le score d’identification des variétés orientales passe à 50 % avec 5 classes vocaliques (ce qui correspond certes, à une classification résultant du hasard), et à 60 % avec 10 composantes. Ces scores moyens s’expliquent du fait que le modèle n’est pas assez complexe (en termes de classes vocaliques) pour permettre une bonne discrimination des systèmes vocaliques orientaux. Néanmoins, il est important de remarquer que la prise en compte du paramètre de durée vocalique tend à faire disparaître le biais des « petits » modèles (i.e. composés de 5 ou 10 classes) qui avaient tendance à classifier la plupart des échantillons de parole dans la catégorie Maghreb. Avec 20 classes gaussiennes nous obtenons 78 % d’identification correcte. L’analyse statistique de ce score permet d’écarter l’hypothèse qu’il soit dû au hasard (P χ2 > 3.84) = .05. Par ailleurs, les différences de scores obtenus par le modèle à 20 composantes pour la discrimination du Maghreb vs du Moyen-Orient se révèlent non-significatives sur le plan statistique, ce qui nous autorise à dire que le modèle est aussi performant pour l’identification des stimuli maghrébins que pour la discrimination des parlers orientaux.
Les expériences que nous venons de présenter nous ont permis d’observer plusieurs éléments importants. D’une part, nous avons vu que l’utilisation conjointe de plusieurs indices discriminants (i.e. ici la dispersion et la réalisation de l’opposition de durée vocaliques) conduit à une amélioration sensible des scores de reconnaissance. En effet, pour 40 tests effectués, nous obtenons 70 % d’identification correcte avec un modèle prenant en compte les caractéristiques formantiques des systèmes vocaliques seules. Lorsque l’on modélise conjointement les caractéristiques spectrales ainsi que l’information de durée des segments détectés, le score passe à 78 %. La différence des taux d’identification observée entre l’une et l’autre de ces deux conditions expérimentales présente un écart significatif au plan statistique (T (39 1.68) = 1.78 ; p = 0.5). Ceci nous autorise ainsi à considérer ces deux critères comme robustes pour la discrimination automatique des parlers arabes par zone géographique.
D’autre part, il convient de rappeler que le nombre de classes vocaliques constitue un facteur essentiel quant aux performances des systèmes d’identification automatique. Compte tenu du faible nombre de données dont nous disposons à l’heure actuelle, nos modèles d’apprentissage sont élaborés à partir des réalisations vocaliques de cinq locuteurs par zone uniquement, soit sur la base de la modélisation de quelque 2000 voyelles détectées par zone75. De ce fait, nous n’avons pas pu tester les résultats d’identification résultant d’une modélisation plus fine des systèmes vocaliques. Il est, en effet, fort probable qu’un modèle appris avec un nombre supérieur de composantes gaussiennes (c’est-à-dire mieux estimé) conduirait à de meilleures performances.
Nous avons rappelé au début de ce chapitre qu’ à l’heure actuelle et avec des modèles indépendants du locuteur, les meilleurs scores d’identification était obtenus à partir 45 secondes de parole. Afin de vérifier l’influence du facteur « durée de test » sur nos résultats, avons répété l’expérience d’identification par zone avec 10 tests. Rappelons que dans cette condition nous avons considéré les quatre répétitions de chaque locuteur comme un bloc unique. La décision d’identification porte donc sur deux minutes de parole continue et non pas sur trente secondes comme dans l’expérience précédente. Les propriétés du modèle ici utilisé correspondent au modèle optimal retenu dans l’expérience précédente (i.e. 20 classes vocaliques). Les résultats obtenus à l’issue de cette seconde expérimentation apparaissent dans le tableau 57.
| Conditions expérimentales (paramètres de modélisation) | Durée des tests | |
| 30 secondes (40 tests) | 2 minutes (10 tests) | |
| MFCC | 70% | 70% |
| MFCC + Durée | 78% | 90% |
Avec 10 tests, nous obtenons pour la première condition expérimentale (modélisation des caractéristiques formantiques seules) 70 % d’identification correcte. Dans ce cas, le manque de données ne nous permet pas d’écarter l’hypothèse que ce score puisse être dû au facteur chance (correspondant à 50 %). Toutefois, Lorsque l’on intègre au modèle le paramètre de durée vocalique les scores atteignent 90 % ce qui nous permet de rejeter statistiquement cette éventualité (P χ2 > 3.84) = .05.
Enfin, nous avons vu que sur 40 tests, l’intégration du paramètre de durée conduisait à améliorer de manière significative les scores d’identification (de 70 % à 78 %). Sur 10 tests, bien que les pourcentages obtenus à l’issue de la seconde condition (i.e. 8 MFCC + D) semblent indiquer de meilleures performances lorsque l’on prend en compte le paramètre de durée pour la modélisation des systèmes vocaliques (de 70 % à 90 %), la différence observée s’avère non-significative au plan statistique.