1.3.1.2. Nosofsky (1984, 1986, 1988, 1991) et Nosofsky et collaborateurs (1997)
Le modèle contextuel de Medin et Schaffer (1978) a été repris et amélioré par Nosofsky (1984, 1986, 1998) qui prend en compte la notion de fréquence. En effet, Nosofsky cherche à rendre compte du fait que tous les exemplaires d’une même catégorie ne sont pas jugés de façon équivalente, certains paraissant être de meilleurs représentants que d’autres (Rosch, 1973). Un déterminant majeur de cette graduation des structures catégorielles implique la similarité des exemplaires. Une autre variable pouvant jouer un rôle important est, d’après Nosofsky (1988), la fréquence des exemplaires : il est plausible de supposer que si la fréquence avec laquelle nous rencontrons un exemplaire d’une catégorie augmente, le fait de considérer cet exemplaire comme membre de la catégorie augmente aussi. Nosofsky (1988) a validé cette hypothèse dans deux expériences de catégorisation (i.e., les sujets devaient classer chaque stimulus présenté dans deux catégories, 1 ou 2, distinctes). Il s’agissait de stimuli rouges qui variaient sur les dimensions luminosité et saturation de la couleur. Nosofsky (1988) manipulait la fréquence de présentation de certains exemplaires. Dans l’Expérience 1, les exemplaires fréquents étaient des exemplaires très représentatifs de la catégorie 2. Dans l’Expérience 2, l’exemplaire fréquent était un exemplaire atypique de la catégorie 2 (i.e., à la frontière des deux catégories). Nosofsky a montré que la précision de la catégorisation augmentait pour les exemplaires fréquents de la catégorie 2, ainsi que pour les autres membres de cette catégorie (qui étaient similaires aux exemplaires fréquents), alors qu’elle déclinait pour les membres de la catégorie opposée qui étaient également similaires aux exemplaires fréquents. Précisons que la notion de fréquence réfère ici, à une estimation subjective du nombre de rencontre d’un objet en tant qu’exemplaire d’une catégorie particulière : “someone’s subjective estimate of how often they have experienced an entity as a member of a particular category” (Barsalou, 1985). Il s’agit d’une fréquence relative à une catégorie donnée, et non pas à la familiarité ou simplement à une “fréquence de rencontre”.
Nosofsky (1988) reprend alors l’équation de Medin et Schaffer (1978) permettant de calculer la probabilité P(J / i) de classer l’exemplaire i dans la catégorie J et propose deux interprétations du modèle contextuel. La première interprétation consiste à considérer que la somme des similarités de l’équation concerne tous les exemplaires distincts d’une catégorie. Ainsi, les exemplaires sont vus comme des “exemplaires-types”, ce qui suppose que de multiples présentations du même exemplaire donnent lieu à une unique représentation en mémoire. La seconde interprétation considère que la somme des similarités prend en considération l’ensemble des stimuli présentés. Les exemplaires sont alors assimilés à des “indices”, de multiples présentations du même exemplaire menant à de multiples représentations en mémoire. Cette seconde interprétation est sensible à la fréquence. En supposant que chaque présentation d’un exemplaire résulte en une unique trace en mémoire (Hintzman, 1986), la version sensible à la fréquence de l’équation P(J / i) est :
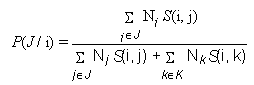
Nj, la fréquence relative avec laquelle l’exemplaire j est présenté lors d’une phase d’entraînement.
La première interprétation conduit à un modèle insensible à la fréquence tel que le modèle de Medin et Schaffer (1978) dans lequel cette notion de fréquence n’existe pas. Les travaux de Nosofsky (1988), ayant montré une supériorité du modèle sensible à la fréquence, intègre cette variable au modèle contextuel. Ainsi, le modèle de Nosofsky se rapproche des principes des modèles de mémoire à traces multiples (présentés ultérieurement), qui supposent que la fréquence ou le nombre de répétitions d’un exemplaire conduit à renforcer la représentation de cet exemplaire en mémoire (Hintzman, 1986, 1988).
Dans son article de 1991, Nosofky précise davantage son modèle. Il y apporte quelques modifications et propose une autre formalisation du modèle. Chaque exemplaire est représenté par un unique point dans un espace psychologique multidimensionnel 2. Les exemplaires sont donc définis sur un nombre variable de dimensions (traits) et peuvent être représentés graphiquement (géométriquement) sur chaque dimension. Pour tester son modèle, Nosofsky (1991) a utilisé des stimuli représentant des visages stylisés, définis selon quatre dimensions : la hauteur des yeux dans le visage, la distance entre les yeux, la longueur du nez et la hauteur de la bouche, chaque trait variant sur des valeurs continues (Figure 5).
Figure 5 - Illustration de quelques visages stylisés utilisés par Nosofsky (1991). Les visages de chaque rangée étaient définis comme appartenant à deux catégories différentes.

Comme ses prédécesseurs, Nosofsky postule que le processus de récupération d’un exemplaire est basé sur un calcul de similarité globale, mais ce calcul est différent de celui proposé par Medin et Schaffer (1978) : la similarité sij entre les exemplaires i et j est une fonction exponentielle décroissante de la distance psychologique entre i et j (notée dij) :
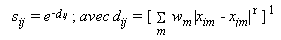
xim la valeur de l’exemplaire i sur la dimension psychologique m. Les coordonnées des xim sont généralement obtenues à partir d’une analyse multidimensionnelle (MDS). Ces coordonnées peuvent être représentées par les coordonnées physiques utilisées pour construire les stimuli dans l’espace (Figure 6).
Les wm représentent les poids attentionnels attribués à chaque dimension m. Les valeurs des wm sont comprises entre 0 et 1. Il s’agit de paramètres libres, estimés à posteriori (Nosofsky, 1986, 1991, 1997), censés refléter l’attention allouée à chaque dimension m. Les processus d’attention sélective sont supposés modifier la structure de l’espace multidimensionnel, c’est-à-dire la formation de l’unité mnésique.
r = 2 : Nosofsky utilise une métrique Euclidienne dans son calcul de la distance. Cette métrique est appropriée pour des stimuli composés de dimensions intégrées (integral dimensions stimuli), alors que la métrique dans laquelle r = 1 est plus appropriée pour des stimuli composés de dimensions séparées (Nosofsky, 1984).
Nosofsky et Palmeri (1997) font l’hypothèse que les processus de classification opèrent plutôt dans des domaines impliquant des stimuli composés de dimensions intégrées que séparées. Les stimuli à dimensions intégrées sont encodés, perçus et représentés comme un tout unitaire, les dimensions intégrées sont donc plus difficile à analyser. A l’opposé, les stimuli dont les dimensions sont séparées, peuvent donner lieu à un traitement indépendant sur chacune des dimensions, celles-ci restant psychologiquement distinctes même si on les combine, ce qui rend peut-être la conservation d’exemplaires complets moins efficace. Une autre difficulté impliquant les stimuli à dimensions séparées est que leur encodage peut nécessiter des traitements séquentiels (ou des traitements parallèles à capacités limitées). Notons que les stimuli utilisés par Medin et Schaffer (1978) variaient sur les dimensions forme, couleur, taille et nombre. Ces dimensions pouvaient donc être clairement considérées comme des dimensions séparées.
Certains facteurs comme la récence de présentation, le nombre de présentation d’un exemplaire (ou sa fréquence relative) font que les exemplaires peuvent résider en mémoire avec des “forces” différentes. Soit Mj, la force de la représentation en mémoire de l’exemplaire j. Le degré avec lequel l’exemplaire j est activé lorsqu’il est présenté avec l’item i est déterminé conjointement par la force de l’exemplaire en mémoire et par sa similarité avec l’item i (Nosofsky, 1988, 1991). L’activation par l’item i de l’exemplaire j, notée aij, est :
aij = Mj sij
et la tendance EJ,i à classer l’exemplaire i dans la catégorie J est la somme des activations de tous les exemplaires stockés appartenant à la catégorie J. Finalement le calcul de la probabilité de classer l’exemplaire i dans la catégorie J est similaire au calcul proposé par Medin et Schaffer (1978). Il correspond à la somme des activations de tous les exemplaires j stockés, divisée par la somme des activations de tous les exemplaires de toutes les catégories considérées.
Nosofsky soutient l’idée qu’un même système mnésique sous-tend les processus de classification (catégoriser un exemplaire donné dans une catégorie particulière plutôt que dans une autre) et de reconnaissance (identifier un exemplaire donné parmi un ensemble d’autres exemplaires), mais que ceux-ci sont régis par des lois différentes :
-
En catégorisation, les décisions reposent sur les activations relatives des catégories respectives, c’est-à-dire sur l’importance de EJ,i par rapport à EK,i. La décision de classer l’exemplaire i en J est prise si la tendance à répondre J dépasse la tendance à répondre K d’une certaine quantité b prise comme valeur seuil :
EJ,i - EK,i > b -
En reconnaissance, ce qui importe est la somme globale des activations des deux catégories, et non pas leur activation l’une par rapport à l’autre. La règle de décision est de répondre “ancien” si l’activation sommée des catégories dépasse un seuil a :
EJ,i + EK,i > a
Pour résumer, Nosofsky, comme Medin et Schaffer (1978), considère que la mémoire contient des exemplaires, c’est-à-dire des informations contextualisées et spécifiques. L’intérêt de sa conception, par rapport à celle de Medin et Schaffer (1978) est qu’il insiste davantage sur l’aspect multidimensionnel de l’information (les exemplaires sont représentés dans un espace à n dimensions). Les différentes dimensions d’un exemplaire sont indépendantes, mais plus intégrées que dans le modèle de Medin et Schaffer. De plus, Nosofsky (1988, 1991) s’intéresse à l’influence de la fréquence des informations ce qui le conduit à postuler qu’il peut exister plusieurs traces en mémoire du même exemplaire, comme le supposent les modèles de mémoire à traces multiples.