1.3.3.1. Le modèle TODAM (Murdock, 1982, 1983)
TODAM (Theory of Distributed Associative Memory) simule des phénomènes de stockage et de récupération dans des situations de mémoire associative, c’est-à-dire des situations dans lesquelles deux idées sont “mises ensemble” et font que quelque temps plus tard, une des deux idées (celle qui est disponible) est utilisée pour recréer ou retrouver l’autre. C’est le cas, par exemple lorsque l’on identifie quelqu’un (association nom-visage), lorsqu’on lit (association graphème-phonème). Cette mémoire simulée stocke l’information relative à chacun des items associés et l’information relative à l’association entre les items, ceux-ci étant représentés par un ensemble de traits.
Dans la théorie, chaque information est représentée par des vecteurs dont les éléments ou attributs prennent des valeurs indépendantes et non-corrélées. Un item donné, au moins dans le même contexte, a toujours les mêmes valeurs sur chaque dimension. Les différents vecteurs (ceux qui codent l’information relative à chacun des items et ceux codant l’information relative à l’association inter-items) sont également indépendants et sont stockés dans un vecteur mnésique commun, noté M. Ainsi, le modèle fait l’hypothèse d’une mémoire distribuée : les informations ne sont pas encodées dans des systèmes de stockage séparés, individuels, mais dans un vecteur unique composite.
Lors de la présentation de nouveaux items, l’information est stockée dans M de façon additive. Pour encoder l’information relative à chacun des items, le vecteur d’attributs correspondant à chacun d’entre eux est ajouté au vecteur mnésique commun M. Pour encoder l’information relative à l’association inter-items, c’est-à-dire pour représenter une relation entre les deux items, leurs vecteurs spécifiques sont d’abord multipliés (opération appelée convolution 5) puis le produit obtenu est aussi ajouté au vecteur M. Pour illustrer, considérons trois paires d’items successives A-B, C-D et E-F (Figure 8).
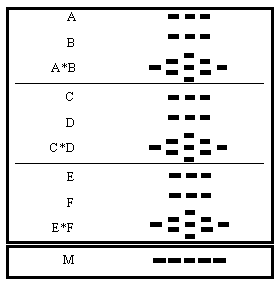
Supposons que deux items d’une paire soient représentés par deux vecteurs contenant trois attributs. Chaque attribut peut être visualisé sur la Figure 8 par des tirets. La convolution de deux vecteurs est un vecteur à cinq éléments, contenant neuf attributs. L’élément du milieu est en fait la somme de trois attributs, les deux éléments à coté sont chacun la somme de deux attributs, tandis que les éléments extérieurs sont constitués chacun d’un seul attribut. A la fin de la présentation de la liste, le vecteur mémoire M consiste en un unique vecteur à cinq items dont le contenu est la somme des six items (A, B,... F) et des trois convolutions de paires (A*B, C*D, E*F). Il s’agit donc partiellement d’une somme d’items et partiellement d’une somme de sommes. Il n’y a rien en mémoire qui corresponde à un des items initialement présentés. Il y a seulement une unique trace composite dans laquelle tout a été ajouté.
Murdock propose que l’encodage est une opération de convolution et que la récupération est une opération de corrélation 6 : les performances observées dans des épreuves de rappel indicé et de reconnaissance résultent de la corrélation entre le vecteur g de l’item test et le vecteur mnésique composite M. Un vecteur g’ plus ou moins similaire au vecteur g de l’item test est ainsi produit. La valeur de similarité, calculée par le produit scalaire (g g’), détermine la probabilité de rappel et sert de base à la prise de décision en reconnaissance.
Dans le cas d’un rappel indicé, le vecteur de l’indice (associé à l’item test) est multiplié par le vecteur mnésique. Une valeur P, reflétant la puissance du vecteur, c’est-à-dire la similarité entre les deux vecteurs, est ainsi obtenue. Si l’item associé à l’indice lors de l’apprentissage (“item A”) conduit à une valeur de similarité proche ou égale à P, alors l’item A est rappelé ; le rappel est correct. Si un autre item (“item B”) conduit à une valeur de similarité plus proche de P que ne l’est la valeur de similarité provoquée par l’item A, alors l’item B est rappelé à la place de l’item A et le rappel est incorrect.
Dans le cas d’une tâche de reconnaissance, un mécanisme de décision supplémentaire, fondé sur la théorie de la détection du signal doit être pris en compte. La performance est prédite à partir des distributions des valeurs de similarité et par rapport à deux critères de réponse (un critère bas et un critère élevé) que le sujet fixe à partir du bruit émergeant de l’ensemble du vecteur mnésique. La position de la valeur de similarité par rapport à ces deux critères détermine la nature de la réponse “ancien” ou “nouveau”, ainsi que le temps de réponse. Si la valeur de similarité est inférieure au critère bas, alors la réponse est “nouveau”. Si elle est supérieure au critère élevée, alors la réponse est “ancien”. Dans ces deux cas également, si la valeur de similarité est extrême, très faible ou très élevée, alors les temps de réponse sont courts. Si la valeur de similarité se situe entre les deux critères, alors le sujet doit attendre qu’une variation de la distribution du bruit permette de situer plus précisément la valeur de similarité par rapport à l’une des deux bornes et les temps de réponse sont plus longs que dans les deux cas précédents.
Ce système de décision, appelé MIM (Memory Integration Model) a été développé en détail par Hockley et Murdock (1987) et a été appliqué au jugement de fréquence (Hockley, 1988). Pour juger la fréquence d’une information, plusieurs critères de décision sont fixés et délimitent des catégories de fréquence. Un compteur est associé à chaque catégorie. Le signal issu de la comparaison en mémoire (comparaison de la similarité entre le vecteur d’un item test avec le vecteur mnésique) et du bruit environnant est évalué par rapport aux catégories de fréquence, et le compteur approprié est incrémenté. Si le compteur mis à jour atteint le seuil de décision, une réponse concernant la fréquence peut être produite ; sinon, le processus de décision est répété jusqu’à ce que le compteur atteigne la valeur seuil. Le temps d’un jugement de fréquence dépend du nombre de cycles nécessaires à la production d’une réponse.