432. Des outils pour juger de la qualité des modèles de choix discrets
Ségonne (1998) distingue les tests formels et les tests informels.
4321. Les tests formels
-
La plupart des logiciels qui permettent de calibrer des modèles logit fournissent des indicateurs pour estimer la précision de ces estimations. Le contrôle direct de la précision de l’estimation est réalisé grâce au calcul de l’écart-type de chaque paramètre estimé. Celui-ci est utilisé pour construire l’intervalle de confiance dans lequel la vraie valeur du coefficient doit se trouver (on utilise le fait que la distribution de la valeur estimée est approximativement normale dans le voisinage de l’optimum). En effet, il est particulièrement intéressant de savoir si la valeur nulle appartient à l’intervalle de confiance. Cela aide à déterminer si une variable doit être incluse dans le modèle. Si zéro n’appartient pas à l’intervalle de confiance, alors l’hypothèse que la vraie valeur du coefficient est nulle (c’est-à-dire que la variable peut être omise) peut être rejetée.
-
L’écart-type permet également de construire les t-ratios (ou t de Student) : les t de Student permettent de décider de la crédibilité (pour un niveau de risque fixé variant en général de 1 à 10%) de la variable testée, dans l’explication de l’utilité globale. Plus la valeur t est grande, plus grande est la contribution de la variable au modèle4. Les t-ratios sont associés à chaque coefficient. Ils sont calculés comme le rapport entre la valeur du coefficient et son écart-type, c’est-à-dire le nombre d’écart-type qu’il y a entre la meilleure valeur estimée et zéro. La qualité de l’estimation des paramètres croît quand le t-ratio croît. Ainsi, en théorie, une variable ne devrait être retenue seulement si son poids est statistiquement différent de zéro. Cependant, il peut arriver que le modélisateur conserve dans le modèle des variables « non significatives » si elles semblent intéressantes.
-
Le troisième critère pour juger de la qualité du modèle sont les rapports de vraisemblance. Plusieurs cas se présentent selon la définition des hypothèses testées.
-
1er cas :
-
H0 : tous les coefficients sont nuls,
-
H1 : il y a au moins un coefficient non nul.
où L( θ ) est la valeur de la fonction de la vraisemblance évaluée avec les coefficients estimés, et L(0) est la valeur de la fonction de la vraisemblance avec tous les coefficients nuls. Cette statistique est distribuée asymptotiquement suivant une loi du χ² avec n degrés de liberté (n étant le nombre de coefficients estimés). -
-
2ème cas :
-
H0 : Tous les coefficients sont nuls, sauf les constantes spécifiques aux alternatives,
-
H1 : Il y a au moins un coefficient différent des constantes qui soit non nul.
où L( θ ) est la valeur de la fonction de la vraisemblance du modèle estimé, et L(c) est la valeur de la fonction de la vraisemblance du modèle composé uniquement des constantes spécifiques aux alternatives. Cette statistique est distribuée asymptotiquement suivant une loi du χ² avec n-m+1 degrés de liberté (n étant le nombre de coefficients, m étant le nombre d’options dans l’ensemble de choix possibles). -
-
3ème cas : comparaison de modèles emboîtés
-
H0 : modèle restreint
-
H1 : modèle non restreint.
où L( θ R ) est la valeur de la fonction de la vraisemblance du modèle restreint, et L( θ NR ) est la valeur de la fonction de la vraisemblance du modèle non restreint. Cette statistique est distribuée asymptotiquement suivant une loi du χ² avec n-m degrés de liberté (n étant le nombre de coefficients du modèle non restreints, et m le nombre de coefficients du modèle restreint). -
Si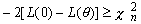 alors on rejette H0, on conserve le modèle non restreint, sinon on accepte H0. χ
2
n est la valeur critique lue dans la table χ² à n degrés de liberté, pour un niveau de risque α. Dans tous les cas, une forte valeur du test indique une amélioration significative de l’information reprise par le modèle.
alors on rejette H0, on conserve le modèle non restreint, sinon on accepte H0. χ
2
n est la valeur critique lue dans la table χ² à n degrés de liberté, pour un niveau de risque α. Dans tous les cas, une forte valeur du test indique une amélioration significative de l’information reprise par le modèle. -
-
Un autre indicateur, le Rhô carré, permet de mesurer la qualité de reconstitution du modèle, c’est-à-dire la qualité de l’ajustement. C’est un indicateur du gain d’information apporté par un modèle par rapport à zéro ou aux constantes. Il est défini comme suit :
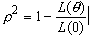
où L( θ ) est la valeur de la fonction de la vraisemblance évaluée avec les coefficients estimés, et L(0) est la valeur de la fonction de la vraisemblance évaluée avec tous les coefficients nuls. Si la valeur de la vraisemblance du modèle composé uniquement des constantes spécifiques aux alternatives est disponible, on peut utiliser l’expression suivante :
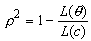
où L( θ ) est la fonction de la vraisemblance du modèle estimé, et L(c) est la fonction de la vraisemblance du modèle composé uniquement des constantes spécifiques aux alternatives.
Dans ce cas, le ρ ² nous informe sur l’amélioration obtenue par rapport à un modèle ne contenant que les constantes. Dans tous les cas, la valeur du ρ² est comprise entre zéro et un, et meilleur est le modèle (c’est-à-dire plus L(θ) croît) plus ρ² est proche de 1. En pratique, une valeur de ρ² comprise entre 0,3 et 0,4 correspond à un ajustement de bonne qualité (Ségonne, 1998).
Pour les deux cas, un autre indicateur est également disponible, le Rhô carré redressé qui diffère du Rhô carré par une correction du nombre de coefficients estimés (n), il prend la forme suivante :
-
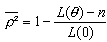 , pour le premier,
, pour le premier, -
et
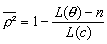 , pour le second.
, pour le second.
Ce redressement permet de corriger le fait que la vraisemblance augmente automatiquement quand le nombre de variables explicatives dans le modèle croît. Cette statistique est voisine de la statistique R² des régressions linéaires.
Outre ces tests formels, un certain nombre de points peuvent être vérifiés de façon plus qualitative. Ce sont des tests informels qui reposent sur le « bon sens ».