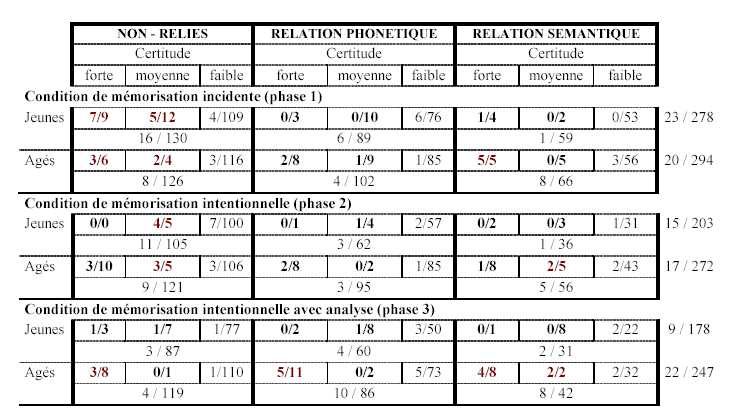
5.4.2.3011Données sur le coefficient de discrimination « forcé»
En rappel indicé, il est possible d'obtenir une mesure de la discrimination reposant sur l'ensemble des éléments de la liste au lieu des seuls éléments effectivement rappelés (Izaute, 1989). L'intérêt de ce nouvel indice est la référence à une seule et même base pour tous les sujets ; ainsi, la valeur du coefficient de discrimination est moins dépendante du nombre de mots rappelés. Il suffit de considérer une absence de réponse comme la production d'une réponse erronée assortie d'un niveau de certitude subjective faible. En effet, si le sujet ne répond pas à un indice, on imagine bien qu'il n'est « pas sûr du tout» que sa réponse est bonne (puisqu'elle est absente).
Avec cette nouvelle mesure, il est possible d'effectuer une analyse de variance incluant le facteur « Niveau de relation entre les mots» car tous les sujets peuvent recevoir une valeur pour chaque croisement des variables manipulées (Age / Phase / Niveau), même quand aucun mot d'une certaine catégorie n'a été rappelé128. La figure 5.11 résume les résultats obtenus. La triple interaction est significative (F(4;100)=3,8, p<.01) alors que les facteurs n'ont pas d'effets indépendants au seuil de significativité .05 (annexe 5.5).
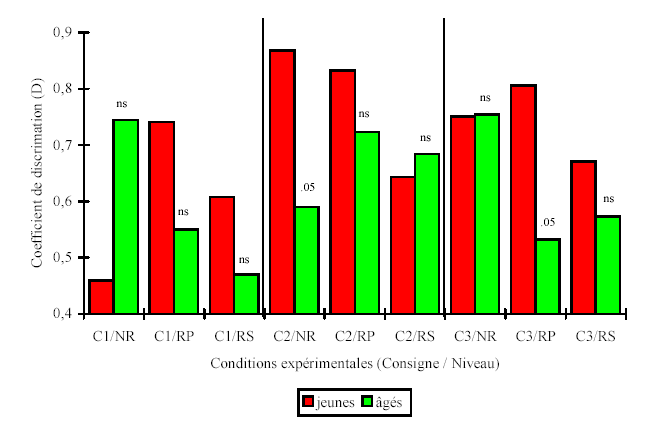
Les jeunes n'obtiennent pas de meilleure discrimination lors de la première phase de l'expérience (incident ; t(25) de 1,52, 1,61 et 1,02, tous les p<.10). Lorsque l'encodage a été intentionnel, la discrimination entre bonnes et mauvaises réponses est meilleure chez les jeunes pour les paires de mots non-reliés seulement (t(25)=2,14, p<.05). Dans cette phase de l'expérience, les deux groupes de sujets se distinguent surtout au niveau de la dispersion des coefficients de discrimination autour de leur moyennes respectives : les écart-types du groupe de personnes âgées sont deux fois plus grands que ceux du groupe des jeunes, sauf pour les paires de mots reliés sémantiquement. Il existe donc plus de variabilité comportementale parmi les personnes âgées en ce qui concerne la capacité à discriminer entre les bonnes et les mauvaises réponses fournies face aux deux types d'indices les moins fortement liés à la cible. Concernant la dernière phase de l'expérience, la seule différence de discrimination entre les deux groupes se retrouve pour les paires de mots reliées phonétiquement (t(25)=2,11, p<.05). Là encore, la plus grande variété des comportements chez les personnes âgées est responsable de ce résultat129.
Dans certains cas de figure, les sujets âgés semblent avoir plus de difficultés que les jeunes à estimer la pertinence des réponses fournies face aux indices. Cela se produit lorsque le lien entre indice et cible ne préexiste pas à l'expérimentation en situation d'encodage intentionnel, et pour les items reliés phonétiquement en condition d'analyse systématique des relations intra-paires.
Si l'on considère les deux groupes de sujets indépendamment (annexe 5.5), on observe des effets des variables manipulées chez les sujets jeunes seulement. Alors que les interactions entre consignes et matériel sont à la marge de la significativité dans les deux groupes (respectivement de F(4;52)=2,22, p=.08 et de F(4;48)=2,07, p=.10), les deux effets principaux sont significatifs seulement pour les sujets jeunes (Fphase(2;26)=5,06, p=.01 et Fniveau(2;26)=3,92, p=.03)130. Leur capacité de discrimination entre bonnes et mauvaises réponses s'améliore entre les deux premières phases de l'expérience, avec le déploiement d'un encodage intentionnel (0,603 versus 0,781 et 0,743), et elle est optimale pour les paires de mots phonétiquement reliés relativement aux sémantiquement reliés (0,693 versus 0,794 versus 0,64).
On peut imaginer que les bonnes réponses de type sémantique sont plus difficiles à juger à cause de leur forte plausibilité, compte tenu de l'organisation des connaissances en mémoire. Au contraire, les éléments reliés phonétiquement laisse une trace plus profonde et sont aisés à reconnaître comme associés dans cette expérience précise du fait de leur faible cooccurrence préalable. Les mots non-reliés, extrêmement difficiles à retenir à cause de leur incohérence sémantique devraient par contre être plus faciles à juger en terme de certitude lorsqu'ils sont retrouvés ou lorsqu'une mauvaise réponse est donnée face à un indice non-relié. Nous n'obtenons pas exactement cet ordre croissant de l'adéquation du jugement de certitude en fonction des niveaux de traitement décroissants : les mots non-reliés ne donnent lieu à la meilleure discrimination.
L'analyse des erreurs de réponses nous dévoile en partie pourquoi ce dernier résultat n'est pas plus marqué. Il se trouve que les mauvaises réponses données face à un indice d'une paire de mots non-reliés et jugées comme « sûres» ou « moyennement sûres» , sont souvent des mots réellement présentés dans la liste originale, mais au côté d'un autre indice ou en tant qu'indice d'une autre paire (confusions intra-listes) ; ou bien encore, ils appartiennent à une autre liste (interférences). Le sujet a donc raison d'accorder une certaine confiance dans sa réponse dans ces différentes situations (tableau V.8), car il a effectivement rencontré ce stimulus au cours de l'expérience. Le problème réside dans la réactualisation des éléments liés à un certain contexte de présentation et dans l'analyse subjective de l'appariement entre des réponses probables et leur contexte original. Bien que basé sur un petit nombre de réponses, ce phénomène explique surtout le faible coefficient de discrimination obtenu pour les paires de mots non-reliés lors de la phase d'encodage incident131.