5.5.2011Rappel indicé
Une ANOVA sur le nombre d'erreurs commises lors de la reconstitution des paires de mots (RI) a été réalisée (annexe 5.9) en prenant le facteur Age et le facteur Phase. L'interaction n'atteint pas le seuil de significativité de .05 (F(2;50)=2,84, p=.07) et seul le facteur consigne joue un rôle (F(2;50)=7,54, p<.01). La tendance à l'interaction se manifeste par un plus grand nombre d'erreurs dans le groupe âgé que dans le groupe jeune au cours du test de la phase de mémorisation intentionnelle, par une diminution des erreurs quand on passe d'un encodage incident à un encodage intentionnel chez les jeunes et quand on passe au travail d'analyse chez les personnes âgées (tableau V.10 pour les moyennes).
| Types de ressemblances | Types de mots | |||||||||
|
|
moyenne par sujet |
sans lien |
phonétique |
sémantique |
nouveau mot |
interférence inter-liste |
fausse association intra-liste |
|||
| JEUNE | ||||||||||
| RI 1 | 5,5 | 8 (7) | 28 (15) | 41 (11) | 54 | - | 23 | 33/77 | ||
| RI 2 | 3,071 | 9 (7) | 15 (9) | 19 (7) | 28 | 4 | 11 | 23/43 | ||
| RI 3 | 3,214 | 5 (4) | 18 (11) | 22 (12) | 36 | 3 | 6 | 27/45 | ||
| AGE | ||||||||||
| RI 1 | 6,462 | 3 (1) | 41 (21) | 40 (19) | 64 | - | 20 | 41/84 | ||
| RI 2 | 6,462 | 7 (6) | 30 (15) | 47 (19) | 67 | 8 | 9 | 40/84 | ||
| RI 3 | 4,462 | 5 (5) | 22 (14) | 31 (13) | 36 | 13 | 9 | 32/58 | ||
Le tableau V.10 présente la distribution des erreurs en fonction de leur relation avec l'indice et de leur nature (intrusions, interférences ou mauvaises associations intra-listes). Les intrusions sont les plus fréquentes dans les deux groupes d'âge. Les interférences sont plus nombreuses chez les personnes âgées mais restent tout de même extrêmement rares. La légère supériorité des interférences chez les personnes âgées pourrait être signe d'un déficit dans la récupération des éléments contextuels spécifiques à chaque présentation. Les fausses associations intra-listes (cible d'une paire donnée face à un autre indice ou indice d'une autre paire donnée comme réponse) se répartissent équitablement dans les deux groupes, sont plus nombreuses que les interférences et moins nombreuses que les intrusions.
En rappel indicé, il est possible de détecter une certaine connaissance du matériel à travers la relation entre l'indice fourni par l'expérimentateur et la réponse erronée du sujet. Si la relation originale est reproduite, on peut supposer que le sujet a accès à une partie de l'information. Etant donné l'existence de trois types de relation, si le sujet répond au hasard (i.e., ignore la nature de la relation originale), 1/3 des réponses erronées devraient générer la relation originale. Par contre, si cette proportion est très supérieure ou très inférieure à 1/3, on pourra conclure :
-
dans le premier cas, à un accès partiel à l'information mémorisée,
-
dans le second cas, à la mise en oeuvre d'une connaissance (ou croyance) inexacte à propos de la relation.
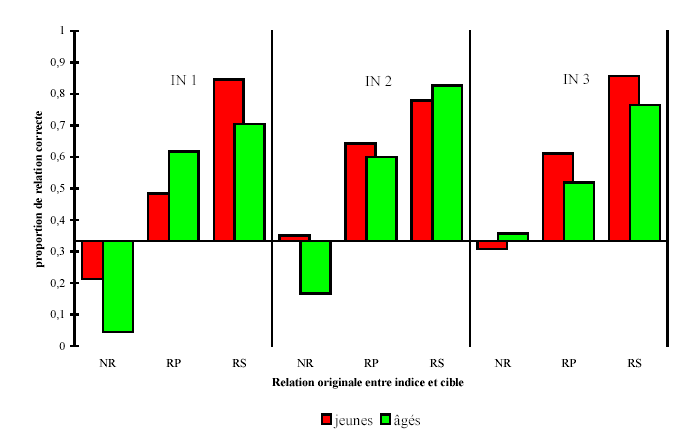
Le test du χ² nous a permis de comparer les fréquences observées avec une répartition théorique des effectifs133, ici de 33%. Pour chaque groupe et chaque type de relation originale entre indice et cible, nous avons comptabilisé le nombres d'erreurs qui reproduisent la relation. L'effectif théorique, représentant une répartition égale des erreurs dans chacune des trois classes de stimuli, s'obtient en divisant par trois le nombre total de réponses pour chaque niveau de relation (annexe 5.10). Le tableau V.11 résume les valeurs du χ² obtenues dans chaque condition et le graphique 5.15 illustre les proportions de reproduction correcte de la relation pour chaque type de matériel, chaque épreuve de rappel indicé et chaque groupe d'âge.
| Relation originale dans la paire | ||||||
| Non-reliés | Phonétique | Sémantique | ||||
| Jeunes | Agés | Jeunes | Agés | Jeunes | Agés | |
| Nombre d'erreurs | ||||||
| Encodage incident | 33 | 23 | 31 | 34 | 13 | 27 |
| Encodage intentionnel | 20 | 36 | 14 | 25 | 9 | 23 |
| Analyse | 13 | 14 | 18 | 27 | 14 | 17 |
| Proportion de reproduction correcte de la relation | ||||||
| Encodage incident | 212 | 044 | 484 | 618 | 846 | 704 |
| Encodage intentionnel | 350 | 167 | 643 | 600 | 778 | 826 |
| Analyse | 308 | 357 | 611 | 519 | 857 | 765 |
| Valeur du χ ² (ddl = 2) | ||||||
| Encodage incident | 2,91 | 9,39*** | 12,65*** | 19,83*** | - | 15,42*** |
| Encodage intentionnel | 0,31 | 6* | - | 12,09*** | - | 22,52*** |
| Analyse | - | - | 6,75* | 11,64*** | - | 13,18*** |
De ces analyses, il ressort que :
-
Les réponses non-reliées ne reflètent la véritable relation que dans 4% à 36% des cas, ce qui est inférieur (personnes âgées / encodages incident et intentionnel) voire égal au hasard (personnes jeunes dans les trois conditions d'encodage et personnes âgées en condition d'analyse) ; chez les sujets âgés, les réponses phonétiques ou sémantiques dominent face à une cible non-reliée. Les erreurs des jeunes se répartissent équitablement entre des réponses non-reliées, reliées phonétiquement ou sémantiquement avec l'indice (réponse au hasard). L'évolution des consignes vers un encodage de plus en plus élaboré de l'information s'accompagne d'une évolution des proportions de relations reproduites à travers les erreurs, seulement pour les paires non-reliées et pour les sujets âgés : on passe d'une proportion correcte de réponse très nettement inférieure au hasard à une proportion correcte proche du hasard. Les erreurs des personnes âgées sur les paires de mots non-reliés nous laissent penser qu'elles n'ont même pas accès partiellement à l'information en mémoire, à savoir, la nature de la relation intra-paire (contexte). Quand elles ignorent l'absence de relation, elles sont sujettes à un biais de réponse vers des items reliés alors qu'elles devraient répondre au hasard (du fait de leur ignorance et après avoir constaté l'existence de trois types de stimuli).
-
Pour les paires phonétiques, environ la moitié des réponses reflète la relation réelle (proportions correctes entre .48 à .64) alors que l'autre moitié reflète une relation sémantique (il y a très peu de réponses fausses non-reliées). En mémorisation incidente, les sujets jeunes produisent autant de réponses fausses évoquant un lien sémantique que phonétique. La même chose se produit pour les personnes âgées dans la phase d'analyse approfondie du matériel lors de l'encodage. Dans cette catégorie, la relation entre réponses erronées et indices n'est pas le fruit du hasard : les erreurs produites indiquent que les sujets savent que le mot à retrouver a une relation avec l'indice ; par contre, le type de relation n'est pas découvert.
-
Pour les deux groupes et les trois consignes de mémorisation, les erreurs de réponse sur les paires sémantiques reflètent le plus souvent cette relation (proportions de relations reproduites comprises entre .70 et .86). Les χ² sont très significatifs. Face à un indice sémantique, les erreurs sont le plus souvent des associés sémantiques.
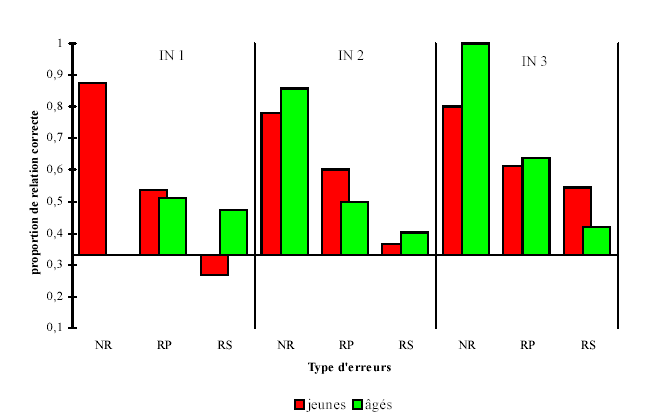
Après l'étude de la répartition des trois types d'erreurs sur chaque type de relations réelles dans la liste originale de stimuli (données présentées en colonnes dans l'annexe 5.10), nous pouvons également analyser la répartition de chaque type d'erreurs sur les trois types de stimuli originaux (données présentées en lignes dans l'annexe 5.10) et calculer de la même façon un χ² (tableau V.12 et figure 5.16). Cela nous permettra de déterminer si chaque type d'erreurs se répartit équitablement sur les trois niveaux de relation intra-paire134.
| Type de réponses erronées | ||||||
| Non-reliés | Phonétique | Sémantique | ||||
| Jeunes | Agés | Jeunes | Agés | Jeunes | Agés | |
| Nombre d'erreurs total | ||||||
| Encodage incident | 8 | 3 | 28 | 41 | 41 | 40 |
| Encodage intentionnel | 9 | 7 | 15 | 30 | 19 | 47 |
| Analyse | 5 | 5 | 18 | 22 | 22 | 31 |
| Proportion de reproduction correcte de la relation | ||||||
| Encodage incident | 875 | 333 | 536 | 512 | 268 | 475 |
| Encodage intentionnel | 778 | 857 | 600 | 500 | 368 | 404 |
| Analyse | 800 | 1.00 | 611 | 636 | 545 | 419 |
| Valeur du χ ² (ddl = 2) | ||||||
| Encodage incident | - | - | 8,01* | 8,24* | 0,78 | 4,55 |
| Encodage intentionnel | - | - | - | 6,48* | 0,75 | 3,11 |
| Analyse | - | - | 5,46 | 7,38* | 3,56 | 4,13 |
La plupart des réponses fausses sans lien apparent avec l'indice fourni (toutefois rarissimes) répètent la relation originale (entre 78% et 100% des cas), sauf en mémorisation incidente chez les personnes âgées qui répondent au hasard (33%). Ainsi, il semblerait que les sujets donnent plus volontiers une réponse totalement indépendante de la cible présentée lorsqu'ils sont sûrs de l'absence de relation originale. Il n'a pas été possible de calculer les χ² sur ce type d'erreurs car les effectifs sont trop faibles.
Les réponses de type phonétique reproduisent correctement la relation de départ dans 50% à 64% des cas, ce qui est significativement supérieur au hasard (tableau V.12 et annexe 5.10). Cette proportion n'évolue pas énormément avec les différentes consignes d'encodage chez les sujets jeunes (54%, 60% et 61%). Par contre, les personnes âgées manifestent une meilleure détection de ce type de relation (à travers leurs erreurs de rappel) quand l'encodage est accompagné d'une analyse systématique du matériel (51%, 50% et 64%). Les sujets ont globalement tendance à répondre par un associé phonétique lorsque la paire originale était effectivement associée phonétiquement, mais aussi lorsque la paire contenait des mots non-reliés. Par contre, très peu d'associations phonétiques sont faites sur les indices des paires sémantiques.
Lorsque les sujets commettent une erreur de type sémantique (i.e., donnent une réponse sémantiquement liée à l'indice), la véritable relation sémantique n'est reproduite correctement que dans 27% à 55% des cas. Leurs réponses sémantiques se répartissent donc de façon aléatoire sur les trois types de stimuli (tableau V.12 et annexe 5.10). Les sujets jeunes améliorent cette proportion au fur et à mesure des consignes (27%, 37% et 55%) alors que les personnes âgées la maintiennent, mais à un niveau plus élevé que les jeunes dans la première consigne (48%, 40% et 42%). Ces dernières semblent plus aptes que les jeunes à reproduire, dans leurs réponses fausses, la relation sémantique originale entre les deux mots dans la condition d'encodage incident. Ce résultat peut néanmoins signifier une plus grande prudence de leur part (tendance à ne répondre que lorsqu'elles sont sûres), alors que les jeunes prennent plus de risques.
La nature des erreurs en rappel indicé donne une indication sur la façon dont les sujets ont traité l'information lors de l'encodage et sur la perception qu'ils ont de la relation qui unissait un indice et une cible donnés.
Nous avons pu constater que, face à l'indice d'une paire de mots non-reliés, les sujets âgés produisent plus fréquemment une réponse associée alors que les jeunes répondent au hasard. Avec un encodage intentionnel dirigé vers les relations intra-paires, les personnes âgées parviennent à fournir des réponses aléatoires face aux indices non-reliés. Face à un indice phonétique, les sujets ont tendance à donner autant de réponses sémantiques que phonétiques, malgré la légère supériorité de ces dernières. Face à un indice sémantique, ce sont des réponses sémantiques qui sont principalement énoncées quel que soit l'âge et la condition d'encodage. Il découle de ces données que les réponses erronées non-reliées à l'indice sont principalement fournies dans le contexte adéquat (paire de mots originalement non-reliés), alors que les réponses sémantiques s'adressent indifféremment aux trois types d'indices. Quant aux réponses phonétiques, elles sont utilisées dans le contexte adéquat mais se répartissent aussi sur les indices non-reliés.
En résumé, les erreurs de réponses nous indiquent une tendance à produire des réponses de type sémantique lorsque le souvenir épisodique n'est pas atteint, même pour le matériel non-relié ou relié phonétiquement. Les réponses non-reliées, assez rares, sont exclusivement produites dans le contexte adéquat, ce qui suggère qu'elles sont émises lorsque le sujet accède à une partie de son souvenir : il sait pertinemment qu'un indice présenté par l'expérimentateur n'était pas associé à la cible qu'il recherche en mémoire.