a) Accéder à l’information
Que l’on soit veilleur, animateur de réseau, professionnel de l’information ou même décideur, on a besoin d’avoir un accès rapide à l’information pour surveiller l’environnement, prendre des décisions, compléter un dossier, être au courant de ce que fait le laboratoire voisin, etc. Cette fonction correspond donc à une information à la fois externe et interne, brute ou analysée, formelle le plus souvent mais aussi informelle.
Accéder à l’information nécessite au préalable de savoir où on peut la trouver, donc une démarche active de recherche, mais aussi peut concerner la réception plus ou moins automatique par le biais d’un système géré en amont par des spécialistes, et parfois personnalisable. On retrouve ici les notions de traqueurs (qui vont au-devant de l’information) et de capteurs (qui sont au contact de l’information).
Les veilleurs par exemple mettent en oeuvre des méthodes actives de collecte d’information externe et surveillent l’évolution de thèmes et d’acteurs grâce à certains outils performants, mais aussi parfois profitent d’un contact naturel avec l’information informelle parce que c’est leur métier.
La recherche active d’information :
Pour des besoins ponctuels, précis, on va activer des outils et/ou un réseau. Les différents logiciels disponibles permettent de collecter des informations structurées ou plein texte :
- sur des bases de données : généralement chacune possède le logiciel de recherche qui lui est propre. Mais comme désormais la plupart sont accessibles via le web, nous ne nous attarderons pas sur ces technologies. Nous noterons cependant que le contenu de ces bases n’est généralement pas indexé par les moteurs de recherche classiques et sont inclus dans le web invisible (voir définition plus loin). D’autre part, les bases de données internes reposent sur des logiciels documentaires sophistiqués, des moteurs qui cumulent des fonctionnalités de filtrage, de tri, et traitent des formats hétérogènes ainsi parfois que plusieurs langues41. Les moteurs qui reposent sur le traitement de la langue naturelle permette à l’utilisateur de ne pas s’inquiéter de l’élaboration d’une requête en langage booléen.
On peut distinguer trois niveaux d’analyse effectuées par ces outils :
-
l’indexation par occurrences, c’est-à-dire que le nombre de fois où le terme de la requête apparaît dans le document détermine son positionnement dans la liste des résultats ; mais il s’agit d’une opération purement statistique ;
-
l’analyse de la relation sémantique entre les mots, nécessitant un dictionnaire gérant les synonymies ;
-
l’analyse morpho-syntaxique des documents et de la requête, qui donne des résultats plus fins [SESA00].
Suivant la technologie appliquée, on n’arrivera pas aux mêmes résultats. L’utilisation couplée des techniques statistiques et linguistiques est recommandée sur des corpus volumineux.
- recherche sur le web : c’est évidemment là que se situe tout l’enjeu des outils de recherche et de collecte de l’information. Nous décrivons plus en détails dans la seconde partie de ce chapitre toutes les fonctionnalités de l’Internet, et donc toutes les possibilités qu’offre ce média à part entière dans le cadre de la veille et de l’intelligence stratégique.
Certes, on ne compte plus aujourd’hui le nombre de moteurs gratuits disponibles sur le web. Ils permettent de trouver l’information par indexation des termes dans les pages web, par classement (annuaires thématiques de sites), par visualisation cartographique, etc42. Certains sont spécialisés dans un type de source, par exemple les forums et les listes de discussion. Il faut cependant être bien conscient du fait que ces techniques d’indexation ne peuvent répertorier qu’un pourcentage finalement assez faible du contenu réel du web. L’usage de métamoteurs peut s’avérer plus intéressant pour arriver à couvrir plus d’informations.
Certains métamoteurs sont des logiciels installables en local43 (gratuits en version limitée) qui proposent des fonctionnalités intéressantes pour la veille : enregistrement des requêtes pour pouvoir les relancer à terme ou de façon régulière, choix de moteurs à interroger, voire même paramétrage de sources spécifiques, classement des résultats par calcul de pertinence, etc.
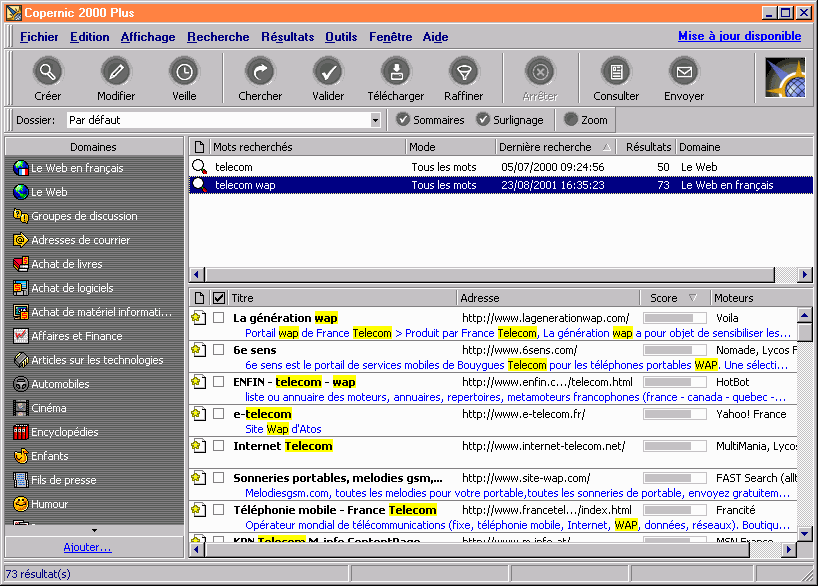
Nous avons également évoqué les moteurs spécialisés dans la recherche sur le web invisible, donc paramétrés pour aller interroger des bases de données spécifiques qui fonctionnent avec leurs propres moteurs. Il en existe en ligne (http://www.invisibleweb.com par exemple) ou à installer (Strategic Finder de Digimind, qui travaille avec des ’pluggins’ de sources thématiques).
Faisons une petite parenthèse sur les agents intelligents [BILL01]. Ces outils, accessibles en ligne ou non, ajoutent aux fonctionnalités listées ci-dessus des caractéristiques telles que l’autonomie, la collaboration, la capacité d’apprentissage, la mobilité, caractéristiques qui les différencient des moteurs et autres robots plus classiques. En simplifiant, on peut dire que l’agent intelligent effectue les tâches qu’on lui confie sur la base des connaissances qu’il possède a priori et qu’il peut compléter, et communique non seulement avec l’utilisateur mais aussi avec d’autres agents [REVE00]. Le nombre de sources que ces agents interroge est également plus important, et ils ont la capacité de rapatrier les résultats (les pages sélectionnées) sur le disque dur de l’utilisateur [SESA00].
Dans le cadre de la veille, donc d’une surveillance continue, ils sont très utiles pour collecter finement les données à fréquence régulière. Certains effectuent même des opérations de traitement linguistiques de l’équation et ensuite des corpus recueillis. Cependant ces logiciels ont aussi leurs limites, parmi lesquelles on citera une certaine lenteur ou encore le rapatriement d’une quantité importante de ’bruit’. Il faut également dire qu’aucun d’entre eux ne possède vraiment toutes les caractéristiques citées ci-dessus (autonomie, communication, apprentissage), mais seulement quelques-unes. Dans tous les cas, le résultat de l’utilisation d’agents intelligents nécessite d’être travaillé, validé et analysé par des spécialistes44.
D’autres outils et méthodes permettent d’effectuer une recherche active :
-
les aspirateurs de sites : ce sont des logiciels qui enregistrent une copie d’une partie ou de l’intégralité d’un site, à partir d’une url donnée par l’utilisateur, afin de faciliter la navigation hors ligne.
-
les outils de surveillance : souvent accessibles en ligne, ces outils vous avertissent par un message des modifications d’une url donnée. Certains moteurs hors ligne cités plus haut dans les agents intelligents ou spécifiques au web invisible possèdent cette caractéristique (Strategic Finder, DigOut4U d’Arisem, etc.)
-
la lecture des forums et la navigation sur le web : passer du temps à rechercher de manière intuitive et informelle peut permettre de repérer des sources nouvelles. La surveillance des forums de discussion, si elle ne se fait pas de façon organisée et formelle via des outils spécifiques (par exemple le module ’Groups’ du moteur Google), est également possible par une participation d’un veilleur qui peut lancer des questions et observer les débats qui se créent autour du sujet.
-
l’accès à l’information recouvre également les outils de visualisation et de navigation dans un corpus : cartographie, webgraphie, les technologies récentes permettant un repérage et une exploration beaucoup plus facile et rapide de l’information. Les logiciels en question mettent ’en scène cartographique’ les mots-clés, les concepts et liens de parenté entre eux [JACQ01 ; MEMH01a]. Ils sont soit intégrés à des outils de recherche, soit à des outils de traitement. Dans la première catégorie, on citera par exemple les arbres hyperboliques qui permettent d’avoir une représentation graphique d’un site web.

Quel que soit l’outil utilisé pour cette phase de recherche et de collecte, il est important, on ne le répètera jamais assez, de passer du temps à choisir les termes et à élaborer la requête. La pertinence du résultat en dépend largement. D’autre part, vu les différences techniques de ces outils et leurs limites respectives, il est utile de considérer l’opportunité d’en utiliser plusieurs en parallèle, notamment lorsque l’on veut obtenir une information exhaustive ou un état de l’art sur un sujet. Certains se prêtent mieux à la surveillance de l’évolution d’un domaine, d’autres à la possibilité d’avoir un ’coup d’oeil’ rapide sur un sujet.
La réception passive : les méthodes de ’push’
Les méthodes de ’push’, une des techniques de diffusion sélective, poussent l’information vers l’utilisateur soit par des chaînes thématiques auxquelles il peut s’abonner, soit par des méthodes de profils individuels ou de groupes [ADIT99]. Le premier cas concerne des sources qui émettent à fréquence régulière, le second cas est lié à la personnalisation de l’envoi : l’utilisateur défini par des paramètres ce qui l’intéresse, dans une liste de sources ou par la définition de mots clés qu’il souhaite voir apparaître. Le résultat se matérialise soit par l’adaptation d’un portail informationnel aux caractéristiques de l’utilisateur (par exemple la page d’accueil d’un intranet), soit par l’envoi d’un message contenant uniquement l’information correspondant à son profil (des communiqués de presse, des brèves d’actualité, etc.). Il existe de nombreux prestataires de services d’accès à des informations répertoriées et triées, qui proposent l’envoi à fréquence régulière (quotidienne, hebdomadaire...) d’une sélection d’actualités. L’utilisateur définit une première fois les caractéristiques de son abonnement, et il reçoit par messagerie soit les informations complètes (par exemple sous forme de brèves45), soit les titres sous forme de liens qui le mèneront à l’article sur le web46.
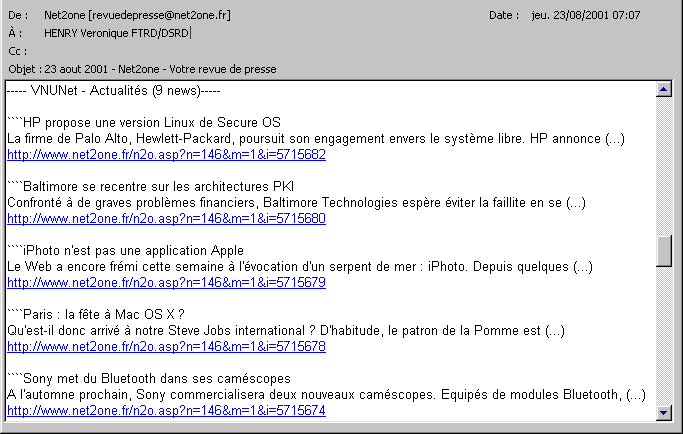
Les méthodes de push nécessitent quasiment toutes une démarche initiale de l’utilisateur pour s’abonner et/ou décrire un minimum son profil et ses centres d’intérêt (utilisation de ’cookies’47). Par la suite il n’intervient que pour modifier ou supprimer son abonnement. Il est donc nécessaire de passer du temps pour bien paramétrer celui-ci, pour repérer les sources les plus en amont et les plus complètes, au lieu de s’abonner à trop de choses et de risquer d’être envahi, submergé.
L’intérêt de cette méthode est évident pour plusieurs types de besoins :
-
l’abonnement à des sources thématiques pour le veilleur par exemple, ce qui lui évite la démarche quotidienne de connexion, recherche, tri, etc. pour surveiller son environnement ;
-
l’abonnement à des informations sélectionnées et/ou analysées pour des utilisateurs internes (décideurs ou autres membres de l’entreprise). L’équipe de pilotage de l’intelligence stratégique peut également se servir d’une telle fonctionnalité pour diffuser sans ’inonder’ ses interlocuteurs et clients.
L’utilité des méthodes de push se mesure donc plutôt dans la durée, et est double : recevoir automatiquement de l’information externe et en diffuser en interne. Cependant il sera intéressant de les faire fonctionner en parallèle avec les méthodes de recherche active (’pull’).
Nous avons précisé que nous employons le terme ’outils’ au sens logiciel ou fonctionnalité informatique. Qu’en est-il de l’accès aux informations informelles et orales ? Certes leur traitement ne passe pas forcément par une formalisation (mise par écrit). Cependant certains échanges font l’objet de comptes rendus (de réunion, de mission, etc.) qui peuvent être insérés aux documents collectés par ailleurs. La participation à des forums de discussion peut également donner lieu à une remontée d’information par la personne qui les surveille. Dans tous ces cas, c’est la messagerie qui permettra le mieux la communication de l’information sélectionnée. Ensuite des dossiers partagés ou des bases de données pourront la stocker.