3.4.1.3 Les distances perceptives
L’objectif de cette analyse est de mieux représenter les rapports de similarité qui peuvent exister entre les langues romanes et d’aboutir à une classification perceptive de ces idiomes. À cette fin, nous avons fait appel à une technique issue du domaine des statistiques descriptives, la MDS. Young (1978) définit la technique de la MDS comme suit :
‘’Multidimensional Scaling (MDS) is a set of data analysis techniques that display the structure of distance-like data as a geometrical picture’30.’Tout d’abord, la MDS permet de représenter dans un espace à plusieurs dimensions les proximités perceptives entre les langues romanes au travers des regroupements opérés entre les stimuli chez les différents groupes de sujets. Ces regroupements sont obtenus à partir des réponses fournies par les sujets pour chaque stimulus. Une matrice est réalisée avec les réponses de type ’même langue’, qu’il s’agisse de réponses correctes (le stimulus catégorisé comme étant de type ’même langue’ était effectivement de type AA) ou de réponses incorrectes (le stimulus catégorisé comme étant de type ’même langue’ était de type AB ’langues différentes’). La tableau ci-dessous fait état de ce résultat.
| Espagnol | Français | Italien | Portugais | Roumain | |
| Espagnol | 37 | 0 | 6 | 1 | 6 |
| Français | 0 | 40 | 0 | 0 | 0 |
| Italien | 5 | 0 | 33 | 2 | 5 |
| Portugais | 10 | 0 | 6 | 25 | 28 |
| Roumain | 7 | 0 | 3 | 23 | 26 |
Par la suite, le regroupement des langues va suggérer lesquels des indices linguistiques ou non-linguistiques sont responsables de ces regroupements et/ou quels sont les indices discriminants robustes qui distingueraient le mieux les différentes langues néo-latines. Notons toutefois que les distances ainsi mesurées par la technique MDS entre les langues romanes garderont un caractère relatif. En effet, les statistiques descriptives ne permettent pas de comparer d’une manière exacte (i.e., du point de vue de la significativité statistique) la magnitude de ces distances.
La distribution spatiale des langues et les distances euclidiennes entre celles-ci permettront de rendre compte d’une proximité sonore entre les langues et d’établir une classification perceptive. Nous espérons que cette comparaison nous permettra de mieux saisir la représentation sonore que ces langues engendrent dans la conscience des auditeurs naïfs. Ensuite, une généralisation sera donnée par une comparaison des classifications perceptives des quatre populations.
La MDS rend possible une interprétation des axes qui déterminent le plan de représentation en termes de critères de nature linguistique ou non-linguistique, suivant lesquels les langues romanes ont été regroupées par les sujets. L’interprétation de ces dimensions fournit a priori les facteurs qui sont à la base de la classification perceptive. Ensuite, la comparaison des critères perceptifs avec les critères segmentaux et/ou supra segmentaux décrits dans le premier chapitre et fournissant le fondement de la principale classification typologique, nous permettra de vérifier s’il existe une correspondance entre la structure des langues romanes et la façon dont les auditeurs naïfs se représentent cette famille linguistique. Plus précisément, nous allons pouvoir estimer le rapport aussi bien entre la classification typologique et la classification perceptive des langues romanes, qu’entre les indices linguistiques qui déterminent les deux classifications. Il faut noter cependant que la comparaison sera d’autant plus fondée que les critères perceptifs seront validés par les quatre populations participantes à cette expérience. Enfin, cette approche nous permettra d’envisager une méthodologie qui privilégie les particularités structurelles des langues dans la recherche d’indices discriminants pour leur identification d’abord perceptive et ensuite automatique.
Cette technique a précédemment été employée dans deux études portant sur l’identification perceptive des langues. En effet, la MDS est choisie par Stockmal, Muljani, & Bond (1996) comme méthode de calcul et de mise en valeur du poids discriminant des traits caractéristiques appartenant à la langue et des traits liés à la voix du locuteur. Ces effets ont été mis en évidence par les réactions d’un groupe de sujets ayant effectué un paradigme expérimental de type identification. Parmi les traits de nature linguistique révélés de cette manière, les auteurs comptent des informations liées aux variations de fréquence fondamentale, aux segments spécifiques et au type syllabique de la langue. Ce sont ces mêmes auteurs qui, plus tard, expérimentent la fiabilité des différents critères de construction d’un corpus dans la perspective d’une évaluation comparative des indices discriminants observés par l’intermédiaire d’une même tâche expérimentale effectuée sur ces corpus (Stockmal & Bond, 1999). Il s’agit de critères géographique et linguistique (i.e., de structure syllabique). Ils arrivent encore une fois à séparer ce qui est de nature non-linguistique (qu’il s’agisse d’informations liées à la zone géographique de la langue ou d’informations liées à la voix des locuteurs), de ce qui est proprement linguistique (dans leur cas, il s’agissait de propriétés phonotactiques de la langue).
Bien qu’encore très généraux, ces indices permettent néanmoins de mieux circonscrire la nature et l’implication du niveau linguistique dans la mise en oeuvre des stratégies perceptives. De ce point de vue, l’utilisation de la technique MDS représente un pas en avant par rapport au simple calcul des pourcentages de réussite des sujets pour les tâches de reconnaissance linguistique. Toutefois, le nombre réduit de travaux y ayant fait appel ne nous permet pas d’effectuer une réelle comparaison pour évaluer l’efficacité de la méthode. Il en est de même en ce qui concerne la variabilité des méthodes expérimentales. Enfin, nous avons également remarqué que la diversité linguistique des corpus et les caractéristiques des auditeurs en termes d’environnement linguistique (dans les études citées, les sujets sont des locuteurs natifs de l’anglais) représentent des données susceptibles d’influencer les résultats.
Nous avons effectué cette analyse avec le logiciel ViSta32 (Young, 1996) en prenant en compte les réponses de toutes les populations qui ont participé à cette expérience.
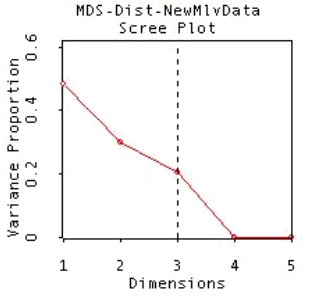
Les données sont représentées en fonction des trois premières dimensions. Ces dimensions sont les plus importantes puisqu’elles expliquent 99,49% de la variance. Ainsi la première dimension permet d’expliquer une proportion de 48,18% de la variance, la seconde permet d’en expliquer uniquement 30,40 % et la troisième – 20,91% de la variance. La quatrième dimension n’intervient que pour seulement 0,22%.
Une décomposition de cette représentation en deux sous-représentations planes a été utilisée afin de mieux visualiser les distances perceptives qui s’établissent entre les langues romanes (figure 18).
La représentation suivante montre la projection des résultats sur deux plans. Le premier (désormais D1/D2) est défini par les deux principales dimensions, tandis que le deuxième plan est défini par la première et la troisième dimension (désormais D1/D3).
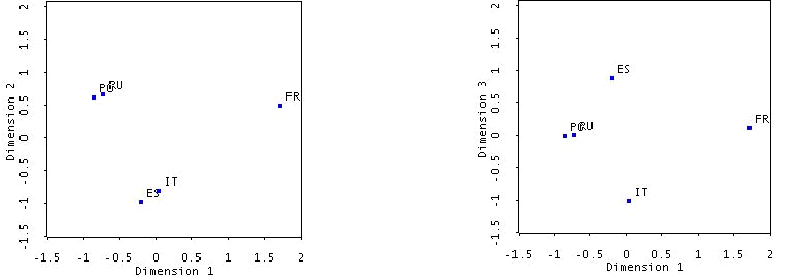
Dans le plan D1/D2, trois groupes de langues apparaissent : la langue maternelle, le français, les langues familières, l’espagnol et l’italien, et les langues très peu connues, le portugais et le roumain.
La première dimension (D1) sépare trois groupes linguistiques : la langue maternelle {français} est isolée des autres idiomes réunis dans le groupe {italien, espagnol, roumain, portugais}. Cette dimension pourrait être caractérisée par le trait [+/-langue maternelle]. Par conséquent, la stratégie principale de la population française, employée dans la discrimination perceptive des langues néo-latines repose sur la présence ou l’absence de la langue maternelle dans le test. En effet, la présence de la langue maternelle rend secondaires les autres stratégies perceptives.
La seconde dimension permet de distinguer entre langues familières et langues moins familières, étant donné que deux groupes linguistiques se forment : {italien, espagnol} vs. {roumain, portugais}. Elle pourrait être caractérisée par le trait [+/-familiarité]. Nous nous trouvons à nouveau devant une stratégie non-linguistique, car elle repose sur les connaissances générales que les sujets ont eu des langues proposées dans ce test. Par ailleurs, ce regroupement rejoint celui obtenu par la classification typologique reposant sur les particularités des systèmes vocaliques des langues romanes. Cette classification séparaient les langues à vocalisme peu nombreux (l’italien et l’espagnol) des langues à vocalisme complexe (voir Chapitre 1). Nous pouvons donc penser à une seconde interprétation pour cette dimension qui serait liée à la structure des systèmes vocaliques des langues romanes. Elle séparerait donc les langues à vocalisme prototypique comme l’italien et l’espagnol, des langues qui possèdent des segments individualisables comme le roumain et le portugais, tandis que le français est neutre par rapport à cette distribution. Toutefois, cette deuxième interprétation reste à être confirmée par des données supplémentaires.
La troisième dimension D3 (dans le plan D1/D3) nous permet de distinguer plus clairement entre les langues familières. Ainsi, l’italien est explicitement opposé à l’espagnol, tandis que le roumain et le portugais occupent une position neutre. Cet axe permet de visualiser le fait que grâce à une exposition préalable à l’espagnol et à l’italien, les sujets français ne confondent pas ces langues (voir paragraphes 3.4.4.2.et 3.4.1.3.). À l’inverse, la confusion entre le roumain et le portugais se maintient dans le plan D1/D3. Par conséquent, il semble que les sujets français soient incapables de distinguer ces deux langues inconnues, quand la période d’apprentissage est très courte.
Ainsi, les trois dimensions dégagées par l’analyse MDS peuvent recevoir ces interprétations principales qui ne sont pas proprement linguistiques (i.e., langue maternelle et familiarité). Cependant, lorsqu’on tient compte des spécificités phonologiques des langues que nous avons décrites dans le premier chapitre de cette thèse, nous pouvons aussi avancer l’hypothèse selon laquelle la seconde dimension sépare les langues en fonction de la complexité de leurs systèmes vocaliques : les langues à trois oppositions vocaliques {portugais, roumain} sont séparées des langues à deux oppositions {espagnol, italien}.