3.5 Conclusions
Dans ce chapitre nous avons étudié les facteurs qui sont à la base des stratégies perceptives de quatre populations de sujets adultes effectuant un test de discrimination linguistique. Plusieurs conditions ont été prises en compte lors de la constitution du paradigme expérimental et pour le choix des groupes de sujets.
Tout d’abord, nous nous sommes intéressés à la discrimination des langues appartenant à une même famille linguistique. Ce choix a été déterminé par l’objectif de trouver les indices discriminants les plus robustes qui restent efficaces même lorsque la ressemblance sonore des langues apparentées est susceptible de complexifier la tâche de discrimination. Ensuite, nous avons choisi quatre groupes de sujets différents, en fonction de leur langue maternelle de façon à ce que ceux-ci occupent différentes positions dans un continuum qui va du plus familier au moins familier avec les langues étudiées. Les expériences ont été complétées par des tâches d’évaluation sur les stratégies que les sujets des trois populations (française, roumaine et japonaise) ont utilisées pendant le test, ainsi que par le calcul des RT pour la quatrième population (américaine).
De cette façon nous avons établi une hiérarchie potentielle des critères de discrimination des langues qui interviennent dans ce type de tâche expérimentale. La stratégie perceptive principale est étroitement liée à la fois à la présence de la langue maternelle parmi les langues testées et à la familiarité des sujets avec ces dernières.
La démarche perceptive générale peut comporter trois phases.
D’abord, avant de faire appel à des stratégies de nature plus complexe, l’auditeur repère sa langue maternelle parmi les langues du test et évalue par la suite la distance entre cette dernière et les autres idiomes qui lui sont présentés38. Ensuite, il essaie de repérer les idiomes qu’il a eu l’opportunité d’entendre auparavant. Finalement, lorsqu’il manque de l’information, il fait appel à des indices linguistiques. En revanche, l’auditeur qui n’a pas bénéficié de ces acquis antérieurs ne peut effectuer la tâche qu’en s’appuyant sur des indices acoustiques appartenant aux niveaux segmental et supra-segmental. Même lorsque le sujet a des connaissances antérieures, si ces dernières ne sont pas acquises de façon solide, les nouvelles stratégies reposant sur les traits linguistiques l’emportent sur les effets de familiarité (voir le cas des sujets américains). Enfin, nous pouvons également considérer une dernière stratégie à caractère intermédiaire se trouvant à la frontière des stratégies linguistiques et non-linguistiques. Cette stratégie consiste en le rapprochement entre la langue inconnue d’un échantillon et une ou plusieurs langue(s) familière(s) qui sont plus faciles à traiter par le sujet en termes de traits linguistiques spécifiques. Ensuite, le modèle intermédiaire entre la langue d’extraction de l’échantillon et celle(s) connue(s) serait comparé avec celui suggéré par le second échantillon de la paires de langues.
Afin de valider statistiquement ces observations, nous avons effectué une analyse de variance ANOVAF1, qui permet de mettre en évidence le rôle du profil linguistique des auditeurs. L’analyse du facteur ’population’ effectuée pour la totalité des paires linguistiques révèle un effet de groupe. Les tableaux ci-dessous montrent que la discrimination des langues représente une tâche perceptive dont les résultats sont fortement influencés par la langue maternelle et les acquis linguistiques antérieurs des auditeurs. Cette observation concerne aussi bien les items de type ’même langue’, que ceux de type ’langues différentes’.
| ES/ES | FR/FR | IT/IT | RU/RU | PO/PO | |
| Valeur de F | 8.739 | 16.487 | 8.108 | 7.749 | 4.812 |
| Valeur de p | < ;0.0001 | < ;0.0001 | < ;0.0001 | 0.0001 | 0.0040 |
| PO/FR | PO/IT | RU/FR | ES/IT | ES/RU | |
| Valeur de F | 16.620 | 5.685 | 11.985 | 3.467 | 22.594 |
| Valeur de p | < ;0.0001 | 0.0014 | 0.0001 | 0.0202 NS | 0.0040 |
| ES/FR | PO/ES | PO/RU | IT/FR | RU/IT | |
| Valeur de F | 40.784 | 5.626 | 14.408 | 34.428 | 12.320 |
| Valeur de p | < ;0.0001 | 0.0015 | < ;0.0001 | < ;0.0001 | < ;0.0001 |
Les résultats obtenus montrent que les différences entre les populations sont statistiquement significatives pour la totalité des items de test. Par la suite, l’analyse post hoc (PLSD de Fisher) montre des écarts significatifs d’une population à l’autre. L’observation principale concerne le fait que les Japonais s’opposent à toutes les autres populations, à savoir aux Américains, aux Français et aux Roumains. Cela est montré dans les figures 36 et 37.
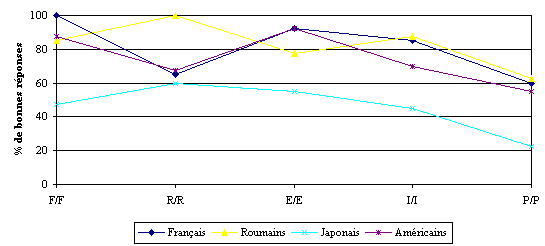
La comparaison des comportements des quatre populations par rapport aux paires linguistiques de type AA montre bien des différences liées à l’appartenance des sujets à l’une des deux classes de population principales, à savoir de type [+/- langue maternelle romane]. On observe une manifestation de ces différences dans le traitement des stimuli Français/Français et Roumain/Roumain. En effet, les Roumains sont différents des autres populations du point de vue du traitement du stimulus Roumain/Roumain. Les valeurs de p sont statistiquement significatives lors des comparaisons : Roumains vs. Français (p=0.0003), Roumains vs. Japonais (p<0.0001) et Roumains vs. Américains (p=0.0007). Cet effet n’est pas surprenant, compte tenu du fait qu’il s’agit de la langue maternelle du groupe de sujets (i.e., les Roumains) en question. Pour les trois autres populations (française, japonaise, américaine), étant donné qu’elles sont toutes non-familières avec la langue roumaine, il n’y a pas de différence statistiquement significative en ce qui concerne les scores de discrimination du stimulus Roumain/Roumain.
En revanche, le stimulus Français/Français n’est pas sujet à une discrimination significativement meilleure de la part de la population française. En effet, compte tenu de la connaissance de cette langue par toutes les populations, exception faite des Japonais, les différences statistiquement significatives concernent les résultats des Français (p<0.0001), des Roumains (p<0.0001) et des Américains (p<0.0001) par rapport aux résultats des Japonais.
Les scores obtenus pour les paires de langues de type AB par les quatre populations de sujets mettent en évidence les mêmes différences statistiquement significatives entre ceux des populations française, roumaine et américaine et ceux de la population japonaise.
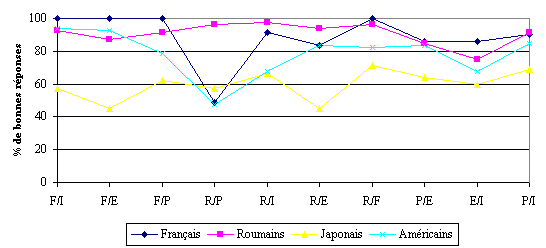
Dans le cas des paires de type ’langues différentes’ (AB), les Japonais sont également différents des autres sujets, à l’exception des quatre stimuli suivants : Roumain/Français, Espagnol/Italien, Portugais/Roumain et Portugais /Français qui montrent des différences de scores plus nuancées. Nous commenterons toutefois ci-dessous chacun des dix stimuli de type AB.
La paire Français/Italien oppose les Français (p<0.0001), les Roumains (p<0.0001) et les Américains (p<0.0001) aux Japonais. Il en est de même des paires Portugais/Espagnol, Espagnol/Roumain et Portugais/Italien. Ces résultats sont dus à la connaissance plus approfondie que les trois populations, française, roumaine et américaine, ont eu des langues romanes en comparaison avec celle de la population japonaise, bien que pour la population américaine cette connaissance reste également limitée.
La paire Portugais/Français oppose les Français (p<0.0001), les Roumains (p<0.0001) et les Américains (p=0.0086) aux Japonais. De plus, elle oppose les Français (p=0.0007) et les Roumains (p=0.0413) aux Américains. Les premiers trois résultats sont la conséquence de l’absence de familiarité des Japonais avec les langues de la paire. En revanche, le comportement différent des Américains par rapport aux Français et aux Roumains peut être associé aux traits linguistiques partagés par les deux langues et qui ont été plus marquants pour les Américains que pour les deux autres populations. Nous pouvons à nouveau observer que la présence de la langue familière parmi les langues de l’expérience et la familiarité occultent des stratégies perceptives liées aux indices proprement linguistiques chez les Français et chez les Roumains. En revanche, chez les Américains ce type de stratégies est beaucoup plus présent.
Le stimulus Espagnol/Français oppose les Français (p<0.0001), les Roumains (p<0.0001) et les Américains (p<0.0001) aux Japonais, mais il oppose aussi les Français aux Roumains (p=0.0251). Cette dernière différence montre que la présence de la langue maternelle dans le stimulus a aidé les Français à obtenir un score supérieur à celui obtenu par les Roumains. Cependant, cette différence n’est pas observable entre les Français et les Américains, ce qui prouve que le degré de connaissance de l’espagnol et du français de ces derniers leur a permis d’avoir un score de discrimination plus important que celui obtenu par les Roumains, et comparable à celui des Français.
La stimulus Roumain/Français oppose, comme dans la majorité des cas les Japonais aux autres populations, à savoir aux Français (p<0.0001), aux Roumains (p<0.0001) et aux Américains (p=0.0401). Mais les Américains sont, eux aussi, différents des Français (p=0.0017) et des Roumains (p=0.0127). La différence qui existe entre les trois populations ci-dessus et les Japonais confirme la tendance générale qui est la conséquence des connaissances peu robustes que les Japonais ont des langues romanes. En revanche, les différences observées entre les Américains et les deux populations de langue maternelle romane sont le résultat de la présence de ces dernières dans l’expérience. Ainsi, même si les Américains ont bien discriminé le stimulus Roumain/Français, car ils connaissaient le français, leur score est inférieur à ceux des sujets qui ont l’une des deux langues romanes comme langue maternelle.
Les résultats obtenus pour la paire Espagnol/Italien montrent que les Français sont différents des Américains (p=0.0305) et des Japonais (p=0.0028). Ce résultat peut être expliqué par le fait que les Français ont le taux de discrimination correcte le plus important et que les deux populations, américaine et japonaise, ont eu des difficultés à discriminer ces deux langues (le taux de discrimination correcte les situe entre la population japonaise et roumaine). Les scores du stimulus Espagnol/Italien mettent en évidence le fait qu’il a été difficile à les discriminer par toutes les populations, malgré la familiarité de certains groupes de sujets avec l’espagnol. Ce résultat va dans le sens d’un partage de traits linguistiques que nous avons mentionné auparavant et qui ’masque’ les effets de familiarité avec l’une des langues de la paire.
Le stimulus Roumain/Italien oppose les Roumains aux Japonais (p<0.0001) et aux Américains (p=0.0002). Ce résultat s’explique par la présence dans le stimulus de la langue maternelle des sujets roumains. Les Français sont, eux aussi, différents des Américains (p=0.0002) et des Japonais (p=0.0005), en raison d’une familiarité plus importante avec l’italien.
Le stimulus Portugais/Roumain, oppose naturellement les Roumains aux autres sujets, à savoir aux Français (p<0.0001), aux Américains (p<0.0001) et aux Japonais (p<0.0001). Ceci n’est pas surprenant, car exception faite de la population roumaine qui a reconnu sa langue maternelle, toutes les autres populations participantes à l’expérience connaissent mal les deux langues.
À présent, nous pouvons conclure au sujet de cette première partie expérimentale nous a montré que la discrimination d’une famille de langues repose sur plusieurs critères. Ces critères dépendent du vécu linguistique des sujets d’origines différentes. Au travers de l’analyse des réponses, nous sommes arrivés à plusieurs conclusions :
-
La réussite en discrimination et le choix des principales stratégies discriminantes dépend de la familiarité avec les langues comparées. Ainsi, nos résultats confirment les observations antérieures concernant la discrimination des langues par les sujets humains (voir Chapitre2).
-
Les stratégies mises en oeuvre sont de deux types : non-linguistiques et linguistiques. Les stratégies non-linguistiques sont prépondérantes et elles dépendent des caractéristiques de la population choisie. Les stratégies linguistiques sont mises en oeuvre notamment par les sujets dont la familiarité avec les langues à discriminer est limitée.
-
Les stratégies linguistiques divisent les langues romanes en deux groupes : italien, espagnol vs. roumain, portugais, français. En comparant ce résultat avec les particularités structurelles segmentales et supra-segmentales des langues romanes, nous avançons l’hypothèse que le trait le plus pertinent pour cette répartition est celui de la complexité vocalique des langues romanes.
Par ailleurs, nous estimons que les résultats des expériences présentées dans ce chapitre soulèvent deux questions :
-
L’expérience en discrimination effectuée avec quatre populations différentes permet d’aboutir à une macro-discrimination qui divise les langues romanes en deux groupes d’idiomes. Il nous semble donc important de découvrir si le regroupement obtenu est dû aux proximités sonores des langues romanes.
-
Le regroupement cité est attesté par trois populations (française, roumaine et américaine). Nous estimons donc qu’une recherche supplémentaire devrait être consacrée à l’étude de la généralité de la macro-discrimination des cinq langues romanes.
Par conséquent, dans la section suivante de cette thèse nous décrirons un paradigme expérimental qui tente de répondre aux questions suivantes :
-
Est-ce que le regroupement implicite des langues romanes peut devenir explicite au travers un jugement explicite (i.e., conscient) sur leurs proximités sonores ?
-
S’agit-il d’une classification générale/universelle ou uniquement spécifique à certains types de populations ?