5.3 L’identification perceptive des langues : comprendre le processus
Les travaux en neuropsychologie ou en psychologie expérimentale s’intéressent souvent à la représentation des processus cognitifs sous forme de modèles hiérarchiques où les différentes étapes de traitement des informations sont représentées par des niveaux interdépendants. Cette idée est exprimée par la phrase de Caramazza & Micelli (1990) que nous citons ci-dessous (pp.1) :
‘’One of the basic assumptions in cognitive neuropsychology is that we can characterize a cognitive process as a set of representations that are computed in the course of cognitive performance, i.e., in the course of object recognition, sentence understanding, and the like [...] For any interesting cognitive process there are a series of representations that are assumed to intervene between the inputs and outputs of the process [...].’42 ’Ces deux auteurs s’intéressent ici aux représentations lexicales en particulier, mais leur démarche a une portée plus large et concerne tout processus cognitif. Ce type de représentation se retrouve également dans les travaux consacrés à la linguistique computationnelle. Les représentations sont destinées à mettre en évidence les étapes de traitement des stimuli en parole naturelle qui sont pertinentes pour la reconnaissance automatique des langues (Carré, Dégremont, Gross, Pierrel & Sabah, 1991)43.
Pour donner une interprétation adéquate au processus d’identification linguistique, nous devons disposer d’un modèle qui soit pertinent pour cette activité cognitive. Nous disposons des modèles de traitement automatique (voir, par exemple, Pellegrino, 1998), mais à notre connaissance, il n’existe pas de modèle qui prenne en considération les étapes de l’identification perceptive des langues. Par conséquent, avant de proposer notre modèle, nous faisons appel à un modèle général de perception de la parole (Liénard, 1995, 1998 et 1999). Nous tenons à mentionner que notre choix n’a comme ambition que de faciliter l’appréhension du processus de type identification. Nous avons opté pour ce modèle, car il s’agit d’une représentation faite avec le souci de l’appliquer aux traitements automatiques. Bien que correspondant à une activité cognitive différente de celle que nos sujets ont effectuée, ce modèle permet de dégager les principaux niveaux de traitement perceptif de la parole naturelle. Le modèle de Liénard propose une structuration hiérarchique binaire, comme nous pouvons le voir dans le schéma suivant.
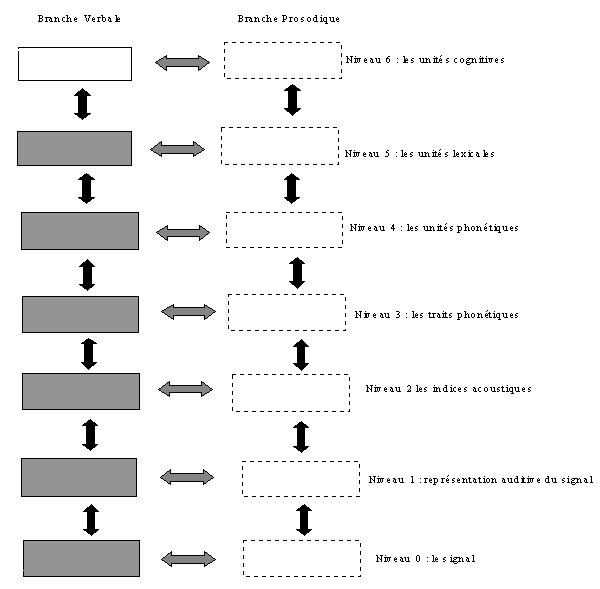
Le modèle de Liénard a six étapes qui vont du niveau le plus bas (Niveau 0, celui du signal) au niveau le plus haut (Niveau 6, celui des unités cognitives). Il traverse quatre étapes intermédiaires qui correspondent à des traitements de plus en plus complexes. Ainsi, le signal subit tout d’abord un codage auditif que l’oreille effectue à partir d’un ensemble de stimulations complexes pour aboutir à sa décomposition fréquentielle (Niveau 1). Par la suite, cette information fréquentielle devient une série d’entités auditives, telles la fréquence fondamentale ou l’enveloppe spectrale qui représentent des unités caractéristiques du Niveau 2 de traitement. Enfin, c’est au Niveau 3 qu’apparaissent les traits phonétiques tels que les formants pour les voyelles, et l’on ne peut parler d’unités phonémiques qu’au Niveau 4. Par la suite les représentations deviennent de plus en plus complexes : au Niveau 5 les phonèmes forment des mots. Finalement, le dernier niveau (Niveau 6) permet l’association des informations précédentes aux concepts.
Il faut noter que le sens du traitement de la parole n’est pas unidirectionnel, car le décodage est progressif et va dans les deux sens, c’est-à-dire d’une unité inférieure vers une unité supérieure et vice-versa. Enfin, la prosodie aussi est traitée à tous les six niveaux et elle accompagne le traitement segmental. Selon l’auteur cité, la branche prosodique fournit à la fois une information linguistique (par exemple, liée aux modulations de fréquence fondamentale ou à l’accent...) et non-linguistique (liée à l’état psychique et physique du locuteur). La branche prosodique ne pourrait donc pas être dissociée de la branche verbale, et la distinction entre les deux branches est un artifice de présentation.
L’identification perceptive des langues représente une démarche différente de celle de la perception de la parole. La perception de la parole, selon le modèle que nous avons exposé, convient en fait à l’identification et au traitement de la langue maternelle et/ou des langues familières, car nous avons pu le voir dans les Chapitres 3 et 4 de ce travail que ce type de langues permettent l’accès à des niveaux supérieurs au niveau phonémique. La perception de la parole représente en plus une démarche naturelle, voire inconsciente, alors que l’identification des langues est une activité volontaire ou stimulée par l’expérimentateur, comme est le cas dans les expériences que nous avons proposées. En outre, mis à part l’identification de la langue maternelle et/ou des langues familières, les auditeurs n’ont pas accès à tous les niveaux de traitement du schéma de Liénard. En effet, il nous semble qu’ils peuvent accéder tout au plus au Niveau 4. Cependant, même s’ils arrivent au niveau des unités phonémiques, certains auteurs comme Strange (1999) montrent que les classes phonémiques déterminées sont celles de leurs langues maternelles ou dans le meilleur des cas, une classe de phonèmes qui sont des moyennes pondérées entre celles de la langue maternelle et les phonèmes caractéristiques des langues à identifier. Cela signifierait que les auditeurs pourraient s’arrêter même plus tôt, au niveau des traits phonétiques (Niveau 3) où ils tenteraient de déterminer les traits spécifiques de la langue à identifier à travers les classes phonémiques de leur langue maternelle.
Enfin, nous pensons que le rapport entre la prosodie et l’identification linguistique peut être entièrement différent dans la tâche d’identification. Les travaux consacrés à l’identification perceptive des langues grâce à leur prosodie montrent que le niveau verbal et le niveau prosodique ne sont pas liés (voir paragraphe 2.3.4 du deuxième chapitre). Bien évidemment, le niveau prosodique se manifeste par l’intermédiaire de la branche verbale, mais il peut permettre, à lui seul, l’identification d’une langue étrangère. Ces travaux prouvent que le rôle de l’information supra-segmentale est primordial et que l’identification grâce à des informations supra-segmentales est possible même si l’auditeur ne bénéficie pas de données segmentales. Dans notre bilan (Chapitre 2), nous avons pu voir que les auditeurs de différents environnements linguistiques sont capables de discriminer des langues inconnues grâce à leur amplitude et/ou à leur rythme.
Les expériences en parole naturelle que nous avons menées montrent que le niveau segmental est susceptible aussi de fournir des indices discriminants robustes. Nous avons tenté de mettre en évidence le traitement effectué par les auditeurs pour aboutir à une macro-discrimination des langues romanes liée au poids des informations vocaliques caractéristiques des cinq idiomes testées. Nous nous contentons d’un schéma qui a un caractère réducteur mais qui, à ce stade de nos recherches, nous semble correspondre à la démarche entreprise par les quatre populations de sujets.
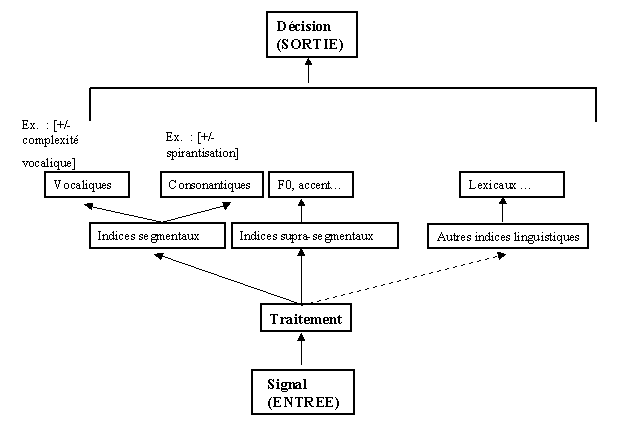
Nous avons opté pour un schéma qui détaille plus particulièrement le traitement du signal aux Niveaux 2 et 3 de la figure 50.
Ainsi, ce modèle possède une Entrée qui correspond au signal et une Sortie qui correspond à la décision. Cependant les niveaux intermédiaires étant encore peu individualisés, nous nous contentons de représenter les niveaux que nous estimons être les plus importants. La boîte appelée Traitement et qui suit l’Entrée ne signifie pas qu’entre ces deux étapes rien ne se produit. En effet, les traitements de bas niveau du signal qui aboutissent aux représentations auditives doivent caractériser la perception de tout signal de parole. Nous pouvons donc envisager un niveau correspondant au Niveau 1 des représentations auditives (figure 50) après l’Entrée. Enfin, le troisième étage de notre modèle représente l’aboutissement du Traitement. Par la suite, la boîte Traitement et les boîtes du troisième étage du modèle correspondraient aux Niveaux 2 et 3 du modèle du Liénard.
Au troisième étage de notre modèle, les boîtes intitulées Indices segmentaux et Indices supra-segmentaux représentent les éléments a priori traités par les auditeurs qui font une tâche d’identification, comme le montrent les expériences en identification perceptive des langues discutées dans le Chapitre 2.
Comme nous pouvons le voir, notre modèle ne prend pas en compte les indices non-linguistiques. En effet, il nous semble que ce qu’on pourrait appeler des indices non-linguistiques représentent plus particulièrement des indices linguistiques associés aux niveaux de traitement supérieurs à celui phonémique. Ces indices sont accessibles aux auditeurs dont les langues maternelles ou des langues familières se trouvent parmi les langues testées. Plus précisément, il s’agit d’indices linguistiques de haut niveau qui sont mis à profit par l’intermédiaire des stratégies d’identification non-linguistiques (i.e., langue maternelle et familiarité). Nous avons pu signaler la présence de ce type d’indices dans nos expériences. Ainsi, l’évaluation des stratégies de discrimination par les sujets a montré que, par exemple, les sujets français reconnaissent des mots ou des terminaisons en italien (langue familière), mais ils ne captent que des segments spécifiques ou des particularités prosodiques en roumain et en portugais (langues peu connues). Par ailleurs, l’expérimentateur tente d’éviter ce type d’indices dans les expériences d’identification perceptive. En effet, nous n’apprendrions rien sur les indices discriminants de l’italien si dans les échantillons nous gardions des mots qui définissent la vie ou la culture italienne tels que ’pizza’ ou ’Giuseppe Verdi’. Les auditeurs devraient a priori se servir des deux niveaux segmental et supra-segmental, car ce sont ces niveaux qui sont préférentiellement modélisés dans l’identification automatique des langues.
Enfin, le quatrième étage du modèle détaille les unités appartenant à l’étage inférieur qui pourraient être utilisées pour l’identification, tandis que le dernier étage, le cinquième, correspond à la sortie, et donc à la décision sur la langue (ou les langues, dans le cas de l’expérience de discrimination que nous avons menée) d’origine du stimulus.
Dans le modèle que nous proposons l’étape de traitement la plus importante correspond à la détermination des traits phonétiques qui, par la suite, aboutissent à la constitution de classes d’unités phonémiques. Le repérage de traits phonétiques peut permettre aux sujets de faire la part des traits caractéristiques de leur langue maternelle et des autres traits que nous pourrions appeler - afin de simplifier ce problème - des traits de type [- connu]. En revanche, des traits de type [+ connu] pourraient leur permettre de repérer la langue maternelle et les langues familières. Le traitement des traits de type [- connu] nous semble le plus intéressant du point de vue de l’identification perceptive des langues. À notre avis, c’est plus précisément ce type de éléments que les auditeurs traitent pour pouvoir les caractériser en termes de [+/- spécifiques] à une certaine langue. Dans une étape ultérieure, les auditeurs procèdent à une pondération de ces traits avant de prendre une décision. Les traits soumis à la pondération sont caractéristiques des niveaux segmental et supra-segmental. Nous avons mentionné dans notre modèle des exemples de traits qui caractérisent les langues romanes testées correspondant aux deux niveaux ci-dessus cités.
Deux questions nous semblent se poser quant à la nature de la pondération.
Un premier problème concerne la généralité de l’opération de pondération, étant donné l’origine linguistique des sujets. Nous nous demandons si le même poids est attribué à une certaine particularité structurelle d’une langue par toutes les populations. Les résultats de nos expériences montrent que la réponse n’est pas facile à trouver. En effet, il semble y avoir des éléments communs dans les évaluations respectives des quatre populations qui ont effectué l’expérience de discrimination décrite dans le Chapitre 3 de cette thèse. Les résultats quasi-analogues des Français, des Roumains et des Américains en termes de regroupements linguistiques laissent penser que les mêmes indices ont permis de diviser les langues romanes en deux groupes linguistiques : d’une part, espagnol et italien et de l’autre, roumain, français et portugais. De plus, ce découpage est validé par la tâche de jugement de similarité. En revanche, le regroupement obtenu chez les Japonais est différent. Ainsi, nous pouvons nous demander si cette population a associé le poids le plus important au même type d’indices discriminants. Les résultats de ce groupe de sujets ne nous permettent pas d’en savoir plus, mais compte tenu du fait qu’il s’agissait d’une population possédant un vécu linguistique très différent de celui des trois autres populations, nous estimons qu’ils ont dû établir une autre hiérarchie d’importance parmi les indices discriminants.
Le second problème concerne la robustesse de l’indice. Ainsi, Hombert & Maddieson (1998) ont souligné qu’un segment rare n’est pas obligatoirement un segment potentiellement robuste pour l’identification d’une langue. Ainsi, la présence d’un indice dans une langue doit être accompagnée d’une manifestation acoustique suffisamment importante pour permettre son repérage par les auditeurs. Enfin, l’intégration de la totalité des éléments issus de cette démarche de pondération des traits devrait aboutir à une prise de décision.
Quant au modèle de tâche expérimentale de discrimination développé notamment dans la première partie expérimentale (Chapitre 3), les résultats des sujets des quatre populations conduisent vers l’hypothèse que trois types de traitements par rapport aux stimuli ont été possibles. La figure ci-dessous détaille les processus correspondant à chaque type de traitement44.
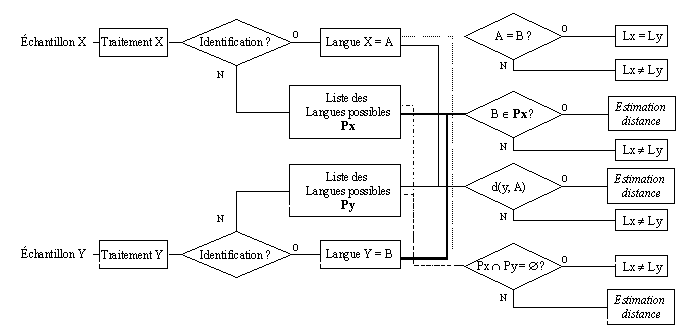
Ainsi, étant donné les échantillons X, Y qui forment une paire de langues, le schéma met en évidence le fait que chacun a dû être évalué du point de vue de son caractère [+/- connu] en termes de langue d’origine. Le premier cas suppose que les deux langues d’origine des échantillons ont été identifiées et il ne reste à l’auditeur qu’à les comparer (A=B ?) pour voir s’il doit fournir une réponse de type ’même langue’ (Lx=Ly) ou ’langues différentes’ (Lx≠Ly). Ce cas correspond à des stimuli ou les échantillons étaient issus de la langue maternelle des sujets et d’une langue familière ou bien de deux langues familières, et à des réponses significativement différentes du hasard.
Le deuxième cas peut en effet être divisé en deux sous-cas potentiels. Le premier sous-cas suppose que la langue A (i.e., la première langue du stimulus) a été identifiée et que la langue paire (i.e., la deuxième langue du stimulus) soit une langue inconnue. Dans ces circonstances, nous pouvons supposer que le sujet essaye d’associer à cette langue inconnue une liste de langues possibles Py à laquelle la langue en question pourrait appartenir. La comparaison en vue d’une prise de décision doit se faire entre la langue A reconnue et l’ensemble Py. Deux possibilités peuvent être envisagées ici. Ainsi, après une évaluation de l’appartenance potentielle de la langue A à l’ensemble Py, le sujet peut effectuer l’un des deux traitements suivants : soit il constate qu’il est possible que cette langue connue A soit proche ou parmi les éléments de l’ensemble Py et il estime la distance entre la langue connue et les langues de l’ensemble afin de prendre une décision de type ’même langue’ ou ’langues différentes’ (boîte Estimation distance) ; soit il est sûr de la non-appartenance de la langue A à l’ensemble Py et il prend la décision de type ’langues différentes’ (Lx≠Ly). Notons également que dans le cas où le sujet a à estimer la distance d(y, A), l’ensemble Py comprend les quatre autres langues romanes restantes. Par ailleurs, ces quatre langues de la liste peuvent posséder des modèles linguistiques que le sujet s’est forgés pour chacune d’entre elles, dans la mesure où il a une relative bonne connaissance de ces langues ou, au contraire, des modèles intermédiaires entre ces langues et des langues qui leur ressemblent et que le sujet connaît mieux. Cette dernière possibilité nous est suggérée par les remarques faites par certains sujets lors de la phase d’évaluation de leurs stratégies de discrimination (Chapitre 3) de type ’cette langue ressemble à la (aux) langue(s) x’ (voir, par exemple, la réflexion d’un sujet français concernant la ressemblance entre le roumain et les langues slaves ou asiatiques).
Le deuxième sous-cas suppose que la langue inconnue est la langue d’origine du premier échantillon. Ainsi, le sujet commence le traitement du stimulus par la construction de la liste de langues possibles Px. La différence par rapport au sous-cas précédent est que, étant donné que la langue inconnue arrive en premier, le sujet est obligé de prendre plus rapidement une décision pour ce qui est des candidats les plus probables de l’ensemble Px, car il ne sait pas encore si le second échantillon du stimulus est issu d’une langue familière ou non-familière. Par ailleurs, garder tout l’ensemble potentiel de langues serait trop coûteux en termes de mémoire. Par conséquent, nous pouvons supposer qu’il prend une décision qui élimine les candidats improbables en faveur d’un (ou plusieurs) candidat(s) qui a (ont) le plus de chances d’être le(s) bon(s). Par la suite, le second échantillon du stimulus le met devant une langue connue, la langue B. À nouveau, deux possibilités peuvent être envisagées. L’une des deux amène à un jugement certain lorsque Lx≠Ly, comme dans le sous-cas précédent. La seconde revient à une estimation des distances entre le(s) candidat(s) choisi(s) de Px et B et le sujet devra à nouveau prendre une décision de type ’même langue’ ou ’langues différentes’. Notons que dans les deux sous-cas ci-dessus, les langues A et B respectivement sont des langues de type [+ langue familière]. En revanche, s’il s’agit des langues maternelles des sujets, la décision par rapport à la seconde partie du stimulus est plus facile à prendre et elle ne nécessite pas la construction des ensembles Px et Py.
Le dernier cas suppose que le sujet ne connaît ni la langue A, ni la langue B. Par conséquent, il construit les deux listes de langues possibles, Px et Py respectivement, pour chacun des échantillons du stimulus. La comparaison qu’il pourrait effectuer par la suite revient à un jugement sur le recouvrement des deux ensembles (Px ∩ Py = ?). Si aucun recouvrement n’est constaté la décision est sans appel ’langues différentes’. En revanche, si un recouvrement potentiel est envisagé par le sujet, il pourra recourir à nouveau à une estimation de la distance entre les candidats les plus possibles issus des ensembles Px et Py respectivement, afin de prendre une décision de type ’même langue’ ou ’langues différentes’.