IV.3. Résultats et discussion
Nous avons réalisé des analyses de variance42 à mesures répétées (Anova) pour les bonnes réponses, sur le nombre d’erreurs et sur les temps de réponse obtenus dans la deuxième phase. Ces analyses comportent trois facteurs intra-individuels : Condition (MEME, DIFFERENT et BASE), Niveau de la cible (niveau de récupération de l’attribut en phase 2 : Entrée ou Supra-ordonné) et Nature (l’attribut est fonctionnel ou structural). Ces analyses ont été effectuées pour les sujets (F1) et pour les items (F2).
La variable Niveau a un effet significatif. Les informations récupérables au niveau d’entrée sont plus rapidement vérifiées que celles qui le sont à partir du niveau supra-ordonné, F1(1, 35) = 26.283, p <.01, F2(1, 420) = 27.971, p <.01. Ces informations de niveau d’entrée sont également vérifiées avec plus d’exactitude que celles du niveau supra-ordonné (F1(1, 35) = 38.077, p < .01, F2(1, 420) = 25.632, p <.01). Ces premiers résultats, conformes à ceux obtenus dans les expériences précédentes, confortent l’idée d’un stockage hiérarchique des connaissances sémantiques en mémoire pour les attributs d’un même objet. Ces connaissances seraient stockées à deux niveaux distincts, selon leur degré de généralisation : le niveau d’entrée et le niveau supra-ordonné.
Concernant l’effet de la Nature de l’information, les informations structurales sont mieux jugées que les informations fonctionnelles pour les sujets F1(1, 35) = 4.375, p < .05. Les informations structurales sont également plus vite vérifiées F1(1, 35) = 10.077, p < .01, F2(1, 420) = 8.848, p <.01.
Cet effet de la Nature interagit avec le Niveau de la cible pour les taux d’erreurs F1(1, 35) = 27.235, p < .01, F2(1, 420) = 8.37, p <.01, et pour les temps de réponse pour les sujets F1(1, 35) = 4.545, p < .05. L’analyse des contrastes met en évidence que les sujets produisent moins d’erreurs pour les informations structurales que fonctionnelles au niveau supra-ordonné, F1(1, 35) = 31.302, p < .01, F2(1, 420) = 9.416, p <.01. Ils mettent également significativement moins de temps pour vérifier les informations structurales plutôt que fonctionnelles à ce niveau, F1(1, 35) = 17.536, p <.01, F2(1, 420) = 9.801, p <.01. On peut noter une tendance inverse de l’effet de la nature de l’information pour le niveau d’entrée : le nombre d’erreurs tend en effet à être plus important pour les propriétés structurales que pour les propriétés fonctionnelles au niveau d’entrée, F1(1, 23) = 3.188, p = .08). Rappelons que ce traitement privilégié des informations structurales au niveau supra-ordonné ainsi que le privilège du traitement des informations fonctionnelles au niveau d’entrée avait déjà été relevé dans les expériences précédentes avec une méthode légèrement différente. Il semble donc que les deux niveaux de récupération, dont nous avons mis en évidence l’existence pour les attributs des objets, ne soient pas identiquement sensibles à la nature du contenu sémantique de l’information. Cette différence constitue un argument supplémentaire en faveur de l’indépendance des niveaux de stockage des attributs selon leur pertinence dans la hiérarchie.
La variable Condition a un effet global sur les erreurs F1(2, 70) = 11.30, p < .01, F2(1, 420) = 5.028, p <.01, et sur les temps de réponse F1(2, 70) = 1.01E2, p <.01, F2(1, 420) = 53.431, p <.01. La Figure 25 présente ces effets.
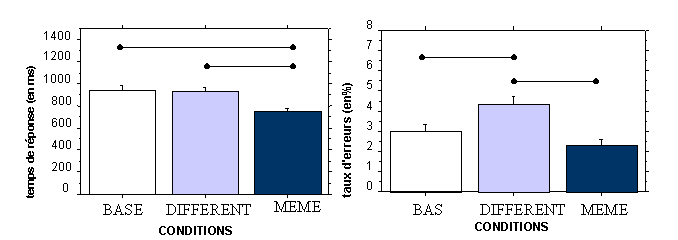
La comparaison entre la condition MEME et la condition DIFFERENT, est significative pour les taux d’erreurs, F1(2, 70) = 21.851, p < .01, F2(1, 420) = 10.008, p < .01 et les temps de réponse, F1(2, 70) = 136.35, p < .01, F2(1, 420) = 72.797, p <.01. Les sujets répondent mieux et plus rapidement aux propriétés dans la condition MEME que dans la condition DIFFERENT. Ce résultat, attendu en raison des effets d’amorçage de répétition, permet de nous assurer que l’épreuve a été réalisé correctement et que le principe d’expérience est assez sensible.
La comparaison des temps de réponses entre la condition MEME et la condition BASE confirme l’effet d’amorçage facilitateur. Conformément à nos attentes, les sujets répondent en effet plus rapidement dans la condition MEME (répétition de l’item dans les phases 1 et 2) que dans la condition BASE (traitement de l’item pour la première fois dans la phase 2, F1(2, 70) = 166.256, p <.01, F2(1, 420) = 86.874, p <.01). Bien que cet effet d’amorçage ne soit pas significatif sur les erreurs F1(2, 70) = .1169, p >.05, F2(1, 420) = 1.938, p >.05 la configuration des résultats nous permet de dire qu’il n’y a pas eu d’échange entre rapidité et exactitude.
Le contraste entre la condition BASE et la condition DIFFERENT est significatif pour les taux d’erreurs (F1(2, 70) = 9.529 p <.01, F2(1, 420) = 3.139, p = .07). Mais, alors que la répétition de l’item (nom et propriété) conduisait à un amorçage facilitateur, la répétition du seul nom entre les deux phases n’aide pas les sujets. Ces derniers produisent même plus d’erreurs dans la condition DIFFERENT que dans la condition BASE. En d’autres termes, la seule répétition du nom entre la phase 1 et la phase 2 ne facilite pas la vérification dans la deuxième phase et souligne même une certaine difficulté à effectuer un traitement successif à propos du même objet, si ce traitement implique des niveaux de catégories taxonomiques différents. Il ne suffit pas d’avoir déjà traité le nom de l’objet dans la première phase pour obtenir un effet d’amorçage. Le fait de devoir traiter cet objet à un niveau différent rend même le processus de jugement plus difficile comparé à la situation où celui-ci n’a jamais été traité auparavant. Nous devons néanmoins noter que cet effet inhibiteur n’est apparu que sur les erreurs. Ces dernières observations permettent de rapprocher nos résultats de ceux obtenus par Thompson-Schill et Gabrieli (1999). L’objectif de ces derniers était de mettre en évidence l’indépendance des lieux de stockage des traits fonctionnels et des traits visuels, à travers quatre expériences utilisant chacune un design expérimental très proche du nôtre. La première expérience consistait en une tâche de classification. Dans la première phase de cette épreuve, 48 noms d’objets étaient présentés au sujet. Pour la moitié de ces objets, les sujets devaient opérer une classification fonctionnelle (en décidant si l’objet était ou non comestible) et pour l’autre moitié, une classification visuelle (en répondant à la question : “est-ce que cet objet est rond ?”). Dans la deuxième phase de cette expérience, 72 mots étaient présentés. Un tiers de ces mots était à classifier d’après la même dimension que dans la première phase, un autre tiers était à classifier sur l’autre dimension et pour le dernier tiers, les mots étaient nouveaux (ils étaient alors traités dans la deuxième phase, pour la première fois, selon l’une ou l’autre des deux dimensions). Dans cette expérience, les auteurs observaient, comme nous-mêmes, un amorçage facilitateur en cas de répétition (condition MEME) ainsi qu’un effet d’inhibition dans la condition DIFFERENT et ceci uniquement sur les taux d’erreurs. Toutefois, cet effet inhibiteur n’était pas significatif dans leur étude. Dans leur deuxième expérience, les sujets devaient répondre à une question visuelle (“ces deux objets ont-ils la même forme ?”) ou fonctionnelle (“ces deux objets ont-ils la même fonction ?”) à propos d’un couple d’objets. Là encore, le design expérimental proposait deux phases ; lors de la seconde phase, les couples étaient traités soit sur la même dimension que dans la première phase, soit sur l’autre dimension, ou bien ils étaient totalement nouveaux et étaient traités sur l’une ou l’autre dimension. Dans cette deuxième expérience, les auteurs observaient l’apparition d’une facilitation dans la condition DIFFERENT, mais elle restait plus réduite que celle produite par la condition MEME. Cette réduction de l’effet d’amorçage dans la condition DIFFERENT avait conduit les auteurs à conclure à des lieux de stockage indépendants des deux types d’attributs qu’ils manipulaient. La configuration de nos résultats suggère elle aussi des lieux de stockage indépendants pour les connaissances, mais cette fois pour les attributs pertinents au niveau d’entrée et pour ceux pertinents au niveau supra-ordonné.
L’interaction entre les variables Condition et Niveau de la cible est significative sur les erreurs, F1(2, 70) = 9.977, p <.01, F2(1, 420) = 4.142, p <.05. Les analyses de contrastes issus de cette interaction, présentée sur la Figure 26, révèlent des résultats très intéressants et pertinents par rapport à notre dernière hypothèse.
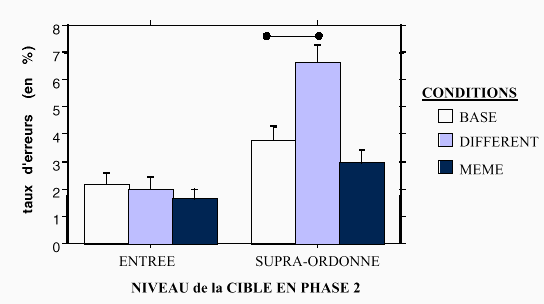
Les sujets font plus d’erreurs pour juger l’association entre le nom et la propriété de niveau supra-ordonné dans la sous-condition DIFFERENT E-S que lorsqu’ils doivent juger cette association pour la première fois (BASE S), F1(2, 70) = 24.204, p < .01, F2(1, 420) = 7.206, p <.01. Autrement dit, il est plus facile de juger l’association entre un objet et un attribut supra-ordonné lorsque cet objet n’a pas été traité auparavant que s’il a été traité à un niveau plus fin auparavant. Cependant, nous n’observons pas d’effet semblable dans la condition inverse (sous-condition DIFFERENT S-E comparée à la condition BASE E), F1(2, 70) = .071, p >.05, F2(1, 420) = 0.032, p >.05. Le fait d’avoir traité quelques minutes auparavant un objet au niveau supra-ordonné n’entrave pas la récupération ultérieure de connaissances de niveau d’entrée sur ce même objet.
Une première interprétation peut être proposée pour expliquer ce phénomène. Le fait d’avoir traité un concept au niveau supra-ordonné dans une première phase implique qu’il y ait tout de même eu des activations automatiques et spontanées des informations stockées au niveau d’entrée, ce qui permet d’attendre une certaine facilitation dans la sous-condition S-E. Par contre pour la condition E-S, dans la première phase, le traitement d’informations appartenant au niveau d’entrée en phase 1 n’impliquerait pas forcément l’activation de connaissances au niveau supérieur, ce qui aurait pu se traduire par une absence de facilitation. Cependant, cette interprétation n’explique pas entièrement le résultat obtenu puisqu’une inhibition apparaît dans cette condition E-S. Tout se passe plutôt comme si le fait d’avoir traité une association entre un concept et un attribut au niveau d’entrée s’accompagnait d’une inhibition du traitement d’autres associations entre ce même concept et d’autres attributs de niveaux plus élevés. Il se peut que ce phénomène repose sur l’existence de relations d’inhibitions latérales entre les connaissances à propos d’un même objet mais stockées à des niveaux différents. Ceci refléterait en tout cas une certaine modularité de l’organisation selon les niveaux de la hiérarchie. Toutefois, les relations entre les unités sémantiques sont généralement décrites comme strictement facilitatrices, contrairement à des relations d’inhibition souvent rapportées à propos de liens entre représentations orthographiques et phonologiques d’unité lexicales (Bijeljac-Babic, Biardeau & Grainger, 1995) voire infra-lexicales (Chavand & Bedoin, 1998 ; Bedoin, 1998 ; Bedoin, soumis).
Les résultats obtenus dans cette Expérience 7 s’accordent donc avec les conclusions des expériences précédentes. Les attributs d’un même objet sont organisés de façon taxonomique. Deux niveaux sont identifiables au sein de cette hiérarchie : niveau d’entrée et niveau supra-ordonné. Cette expérience permet également de confirmer l’indépendance de ces deux niveaux.
Le but de l’expérience suivante (Expérience 8) est de montrer que, conformément aux théories issues de la folkbiology, plusieurs niveaux supra-ordonnés sont identifiables au sein de cette organisation. Et, en accord avec notre précédente expérience, nous pensons pouvoir démontrer que ces niveaux sont également indépendants l’un de l’autre.