1.3.1. Sélection sur les observables
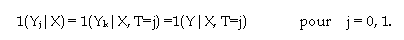
Comme la distribution des variables observables X est identifiable, il en résulte que les distributions marginales 1(Y 0 ), 1(Y 1 ) et les distributions conditionnelles 1(Y 0 |T=0), 1(Y 1 |T=1) des variables de résultat sont elles-mêmes identifiables. On peut en particulier identifier leur espérance et donc l’effet moyen du traitement (ATE), de même que l’effet moyen du traitement pour le groupe des individus traités (TT). La distribution des variables latentes est identifiée, mais leur loi jointe ne l’est pas.
Le principe de l’estimation consiste alors à utiliser les informations dont on dispose sur les non-participants afin de construire pour chaque individu traité un contre factuel, c’est-à-dire une estimation de ce qu’aurait été sa situation s’il n’avait pas été traité. Le problème est donc d’estimer pour chaque individu i 0 traité et de caractéristique xi 0 , la quantité suivante : E(Y|X= xi,T=0) =g(xi). L’estimateur final est alors obtenu comme la moyenne des écarts de la situation des individus traités et du contre factuel construit. Il s’écrit :
où I 1 = {i|T i =1} est l’ensemble des individus non traités et N 1 le nombre d’individus traités.
Il s’agit ici d’associer pour chaque individu traité un ou plusieurs individus dotés des mêmes caractéristiques. Il est alors nécessaire d’apparier les individus sur un grand nombre de caractéristiques. Dans la pratique, cet appariement est complexe à réaliser dans la mesure où il est difficile de trouver systématiquement pour chaque individu traité un individu non traité ayant exactement les mêmes caractéristiques 73 . La méthode des scores de propension permet de réduire la dimension de l’appariement du nombre de variables retenues dans la liste des variables de conditionnement à la dimension du score (propriété de Rosenbaum et Rubin, 1983), qui s’écrit : P(X) = P(T=1|X) (probabilité de traitement), c’est-à-dire à 1. Ainsi, il n’est pas nécessaire d’apparier les individus sur chacune des variables de conditionnement.
A partir de ce type d’estimation par appariement d’échantillons (méthode du matching), plusieurs extensions ont été proposées telles que la méthode du kernel matching qui propose notamment des estimateurs non-paramétriques à noyau (Heckman et al., 1998). Elle consiste à calculer une moyenne pondérée des observations de l’échantillon de contrôle (population des individus non traités). Dans ce cas, chaque individu non traité participe à la construction du contre factuel de l’individu i avec une importance qui varie en fonction de la distance entre son score et celui de l’individu considéré. L’intérêt principal des estimateurs non-paramétriques est qu’ils permettent de ne pas imposer de restrictions fonctionnelles.
Cependant, il est possible d’opposer une limite à ce type de méthode qui impose que l’on dispose pour chaque individu traité, d’individus non traités dont les scores ont des valeurs proches du score de l’individu traité que l’on considère. On ne peut donc construire le contre factuel que pour les individus dont le score appartient à l’intersection des supports des distributions des scores des individus traités et des non traités. L’estimateur obtenu in fine constitue alors un estimateur local (Brodaty, Crépon et Fougère, 2002b).