4.1.1. Principes du codage
Un premier codage a donc dû être opéré sur les corpus qui permet de classer les interventions en différentes catégories, selon le code utilisé. Au premier abord, cette opération peut sembler triviale, nous verrons que ce n’est pas tout à fait le cas.
Nous avons classé les interventions en cinq catégories pour ce qui concerne la langue. Ces catégories ne se justifient que pour les traitements que nous nous étions proposés, et nous en présentons maintenant les principes.
En examinant de façon globale les corpus, nous avons remarqué une présence importante de l’anglais par rapport aux autres langues – hormis le français. Il nous a semblé donc important pour caractériser le corpus de marquer spécifiquement les interventions en anglais. Cette position se justifie aussi par le fait que les locuteurs francophones ont montré dans nos corpus une tendance à communiquer avec les participants qui utilisent l’anglais pour leurs interventions.
Il est aisé de distinguer l’anglais du français mais beaucoup moins de déterminer s’il s’agit d’un anglais langue seconde ou d’un français langue seconde. Les études linguistiques mentionnent des patterns de production typiques de locuteurs de langue seconde pour une langue maternelle particulière aux plans phonologique, morphosyntaxique et sémantico-lexical et pragmatique, des maladresses, des "brutalités", mais ce n'est que sur un faisceau d'indices à occurrences régulières qu'on sera à même de décider si un locuteur utilise une langue qui n'est pas sa langue maternelle 71 . Pour l’anglais, nous n’avons fait la distinction que lorsque le locuteur s’exprime en français tout au long du corpus à l’exception de quelques interventions qui sont, par exemple, des réponses qu’il adresse à des locuteurs utilisant l’anglais. Pour le français 72 , nous avons repéré des locuteurs probablement français langue seconde : en observant toutes les interventions d’un locuteur particulier des indices linguistiques récurrents ont été repérés tels que les erreurs sur le genre des noms, le choix des pronoms, le choix lexical et des structures syntaxiques non conventionnelles.
Du point de vue inverse, aucune utilisation de foreigner talk 73 n'a été repérée dans le corpus de la part des locuteurs utilisant le français.
Les interventions qui sont mixtes du point de vue du code ont été classées dans la catégorie correspondant à la langue dominante pour un locuteur, les éléments du xénolecte étant marqués comme tels à l'intérieur même de l'intervention ainsi que l'illustre l'exemple suivant :
‘Extrait du Corpus F1’ ‘*PAD: t cvontent je vais avoir mlein de prive now@gb lol’Nous avons rangé dans une classe particulière toutes les interventions dans d’autres langues et qui ont été ignorées des utilisateurs francophones ou incomprises. Ainsi se trouvent dans cette classe quelques interventions en grec, en allemand,… et également un certain nombre d’interventions qui se sont présentées comme indécidables du point de vue de la langue (ratés de la communication). Dans d'autres cas les suites de caractères semblaient ne pouvoir appartenir à aucune langue (Cf. exemple ci-dessous).
Le rassemblement d’éléments aussi divers se justifie par le fait qu’ils sont ignorés des locuteurs francophones ou qu'ils ne suggèrent que des commentaires métalinguistiques tels que ceux des exemples ci-dessous.
‘Extrait du Corpus P3’ ‘*PAT: ‘¼ŽÐƒT[ƒrƒX‚Ƃ͈Ⴂ‰f‘œ‚Í‚·‚ׂĖ³C³‚Å‚·‚Ì‚ÅA¶‚Å—‚ÌŽq‚Ì‚·‚×‚Ä‚ðŒ©‚é‚±‚Æ‚ªo—ˆ‚Ü‚·!!‚à‚¿‚ë‚ñ‚ ‚»‚±‚à‚΂Á‚¿‚茩‚¦‚Ü‚·‚æ!!’ ‘%add: INDET’ ‘*PAT: —cŽ™ƒvƒŒƒCA—ŽqZ¶ƒvƒŒƒCA…’…ƒvƒŒƒCAŠÅŒì•wƒvƒŒƒC“™‚¢‚ë‚¢‚ë‚È ƒRƒXƒ`ƒ…[ƒ€‚ð—pˆÓ‚µ‚ÄA‚©‚í‚¢‚¢—‚ÌŽq‚ª–ˆ“ú‚ ‚È‚½‚ð‚¨‘Ò‚¿‚µ‚Ä‚¨‚è‚Ü‚·チB’ ‘%add: INDET’ ‘*PAB: alors qu'es que ca?’ ‘%add: ALL 74 ’ ‘*PAB: un op au primier qui arrive a casser le code !’ ‘%add: ALL’ ‘*PAJ: J'laiEuMonCode PAB .’ ‘%add: PAB’ ‘*PAB: PAJ rien a voir !’ ‘%add: PAJ’ ‘*PAS: c un flood texte ;p’ ‘%add: PAB’ ‘Extrait du Corpus F4 75 ’ ‘*PCF: svara .’ ‘%add: INDET’ ‘*PCF: nu .’ ‘%add: INDET’ ‘*PCF: lite respekt om man få be .’ ‘%add: INDET’ ‘(6)’ ‘*PCA: c'est pas le suedois la langue officielle de ce chan mais le français ’ ‘%add: PCF’Nous avons enfin marqué les interventions strictement spécifiques à l’IRC. En principe, les commandes des utilisateurs n'ont pas de contrepartie dans les lignes messages, toutefois il est possible de paramétrer les logiciels pour qu'ils le permettent ; la commande apparaît alors comme une ligne message et est immédiatement suivie de la ligne système correspondante. Ce fait donne naissance à des comportements ludiques particuliers, ainsi, sont rassemblées dans cette catégorie des interventions qui sont soit des commandes à un robot, soit des imitations de commandes, soit un code particulier utilisé pour s’adresser à l’ensemble des utilisateurs toutes langues confondues.
À l’issue de ce codage, qui nous permettra de nous intéresser spécifiquement au français, il nous est possible de donner un aperçu de la représentation de chaque code dans les corpus. Dans l'histogramme ci-dessous, le groupe 1 représente le nombre d'interventions indécidables du point de vue de la langue et/ou qui ont été ignorées des autres utilisateurs. Les groupes 2 et 3 rassemblent respectivement les interventions en anglais et en français. Le groupe 4 est constitué des interventions dans d'autres langues que le français ou l'anglais qui ont été intégrées à l'interaction. Enfin le groupe 5 rassemble les interventions qui sont des commandes ou pseudo-commandes informatiques.
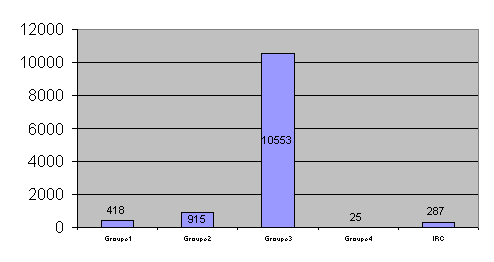
On remarquera sans peine que les interventions autres que francophones sont peu importantes. Pour l'anglais, 20% des interventions proviennent de locuteurs qui utilisent par ailleurs le français, et 12% sont des interventions que nous qualifions de non originales puisqu'il s'agit de moules d'énoncés préconçus, dans lesquels des variables sont remplies automatiquement ou manuellement dont nous donnons ci-après quelques exemples, les lettres majuscules représentant les parties d'énoncé variables :
‘Énoncés préconçus’ ‘X is back. gone N min Y s 76 ’ ‘X slaps Y around a bit with a large trout 77 ’Ces "moules" sont disponibles dans certains logiciels clients et se répètent par endroits tout au long du corpus.
Pour le français, 1% des interventions a été marqué comme du français langue seconde selon les critères évoqués plus haut.
Quant à la forme du codage dont nous venons d'exposer les principes, elle associe à chaque intervention la catégorie qui lui correspond. Le codage des locuteurs et celui de la langue sont donc indépendants.