2.3.1.1. L'analyse statistique des réponses "brutes"
Pour ce premier niveau d'étude, deux procédures informatiques ont été utilisées : TALEX (construction des tableaux lexicaux) et VOSPEC, (construction du vocabulaire spécifique).
La procédure TALEX permet d'éditer des tableaux lexicaux, sous forme de tableaux statistiques de distribution de fréquence et tableaux de contingence. Les premiers répertorient la totalité des expressions utilisées et les classent par ordre alphabétique ou selon leur fréquence. Ils présentent de ce fait un nombre de lignes considérables, dont voici un court extrait concernant les réponses Q1b :
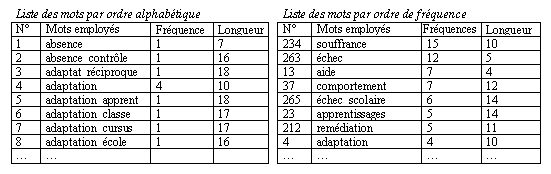
Les tableaux de distribution de fréquence permettent aussi d'évaluer la dispersion des réponses – rapport entre nombre de formes graphiques distinctes et nombre total de réponses. Les tableaux de contingence, pour leur part, confrontent plusieurs partitions de l’échantillon et donnent la possibilité de "travailler sur des variations par catégorie" 96 . Les différentes variables retenues ( variable 1 : spécialisation AIS ; variable 2 : sexe ; variable 3 : fonction professionnelle ; variable 4 : corps de métier) déterminent des catégories dont il est possible de comparer les réponses.
Voici par exemple un extrait du tableau de contingence multiple concernant la question Q1 qui comporte 266 lignes (correspondant à 265 formes graphiques distinctes), 20 colonnes (la variable 3 "fonction professionnelle" a été supprimée ici pour des raisons de mise en page), et occupe en totalité 5 pages :
| Variable 1 Spécialisation AIS |
Variable 2 Sexe |
Variable 4 Corps de métier |
||||||
| oui AIS | non AIS | Homme | Femme | IEN | Form | Ens spé | Ens gén | |
| absence | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| absence_contrôle | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| adaptat_réciproque | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 |
| adaptation | 2 | 2 | 1 | 3 | 1 | 1 | 1 | 1 |
| adaptation_apprent | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 |
| adaptation_classe | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 |
| adaptation_cursus | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 |
| adaptation_école | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 |
| affectivité | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 |
| agir | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 |
| agitation | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 |
| agressivité | 2 | 0 | 0 | 2 | 0 | 0 | 2 | 0 |
| aide | 4 | 3 | 4 | 3 | 3 | 1 | 2 | 1 |
| aide_pédagogique | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 |
| aides | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 |
| aime_pas_ça | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 |
| aller_vers_autre | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
| angoisse | 1 | 1 | 2 | 0 | 2 | 0 | 0 | 0 |
| appel | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| appentissages | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| apprent_difficiles | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 |
| apprent_fondamentaux | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 |
| … | ||||||||
La lecture de ce tableau montre que l'idée d'homogénéité d'emploi des mots selon les lignes est rejetée. Quelles sont alors les cases qui produisent le plus d'hétérogénéité ? Une première analyse par le calcul permet de les identifier. Mais étant donné petitesse du nombre obtenu dans chaque case, due à la dispersion des réponses, les résultats demeurent difficilement interprétables. Un regroupement des formes graphiques, établi en fonction de leur signification respective, va permettre de réduire considérablement le nombre de formes. Par exemple pour la question Q1 il passe de 265 à 13. Cette opération d'agrégation s'appuie non sur une analyse de contenu statistique, le texte explicatif étant difficile à isoler, mais sur une analyse de contenu qualitative, construite à partir des concepts structurant la recherche.
La procédure VOSPEC permet de déterminer et d'éditer les mots caractéristiques de groupes d'individus (professionnels spécialisés en AIS / non spécialisés en AIS ; homme / femme ; IEN / Formateurs / Enseignants spécialisés / Enseignants généralistes etc…) en fonction de leur fréquence d'utilisation. Ces mots peuvent revêtir une spécificité positive (ils sont employés plus fréquemment que ce qu'autorise un usage banal) ou négative (ils sont au contraire évités). La procédure VOSPEC les édite par ordre de valeurs-test 97 décroissantes. Elle édite également les réponses caractéristiques des groupes retenus selon le Khi 2 et la moyenne des valeurs-tests. Par exemple, les tableaux VOSPEC Q1b variable AIS – dont un extrait figure ci-après - présentent les résultats de la recherche de mots bruts significatifs au sein de deux groupes, les spécialisés en AIS et les non spécialisés en AIS, ayant répondu à la question Q1 "Quels sont les cinq mots qu'évoque pour vous l'expression enfants en difficulté ?".
| Groupe d'individus : oui AIS | |||||||||||
| Mots ou segments caractéristiques | Pourcentage interne | Pourcentage global | Fréquence interne |
Fréquence globale |
Valeur-Test | Probabilité | |||||
| remédiation | 2,28 | 1,34 | 5 | 5 | 1,48 | 0,07 | |||||
| souffrance | 5,02 | 4,03 | 11 | 15 | 0,89 | 0,19 | |||||
| Echec | 4,11 | 3,23 | 9 | 12 | 0,85 | 0,2 | |||||
| fragilité | 0,91 | 0,54 | 2 | 2 | 0,40 | 0,35 | |||||
| … | |||||||||||
| handicap | 0,00 | 0,54 | 0 | 2 | -0,96 | 0,17 | |||||
| équipe | 0,00 | 0,54 | 0 | 2 | -0,96 | 0,17 | |||||
| présence | 0,00 | 0,54 | 0 | 2 | -0,96 | 0,17 | |||||
| problèmes | 0,00 | 0,81 | 0 | 3 | -1,49 | 0,07 | |||||
| Groupe d'individus : non AIS | |||||||||||
| Mots ou segments caractéristiques | Pourcentage interne | Pourcentage global | Fréquence interne |
Fréquence globale |
Valeur-Test | Probabilité | |||||
| problèmes | 1,96 | 0,81 | 3,00 | 3,00 | 1,49 | 0,07 | |||||
| handicap | 1,31 | 0,54 | 2,00 | 2,00 | 0,96 | 0,17 | |||||
| présence | 1,31 | 0,54 | 2,00 | 2,00 | 0,96 | 0,17 | |||||
| solutions | 1,31 | 0,54 | 2,00 | 2,00 | 0,96 | 0,17 | |||||
| … | |||||||||||
| tolérance | 0,00 | 0,54 | 0,00 | 2,00 | -0,40 | 0,35 | |||||
| échec | 1,96 | 3,23 | 3,00 | 12,00 | -0,85 | 0,29 | |||||
| souffrance | 2,61 | 4,03 | 4,00 | 15,00 | -0,89 | 0,19 | |||||
| remédiation | 0,00 | 1,34 | 0,00 | 5,00 | -1,48 | 0,07 | |||||
Les mots les plus forts qui tendent à être caractéristiques de chacun des groupes sont "remédiation" et "problèmes". "Remédiation" constitue la spécificité positive pour les spécialisés, "problèmes" la spécificité négative. Les résultats sont strictement inversés pour les non spécialisés. Les valeurs-test de ces expressions - respectivement de 1,48 et de 1,49 - autorisent une interprétation mesurée étant donné que la validité de ce résultat est d'autant plus fiable qu'il s'approche ou dépasse la valeur 2. Elles révèlent une posture particulière et relativement typique de chacun des groupes : le dernier est confronté à des situations problématiques tandis que le premier est chargé d'y apporter remède.
L'éclatement des réponses ne favorise pas de valeur-test élevée, significative d'un groupe considéré, c'est-à-dire supérieure ou égale à deux avec un niveau de risque de 5 % (ici la probabilité est de 0,07 soit 7 %). Il est facile de constater que le regroupement de mots par signification voisine est susceptible de modifier considérablement les résultats, dans le sens d'une plus grande lisibilité des préoccupations.