4-4 Le modèle CLIP
Kajii (2000) suppose que lorsqu’un stimulus mot est présenté brièvement dans un contexte d’identification perceptive, deux événements peuvent prédire l’identité du mot.
Événement 1. Le participant identifie toutes les lettres du mot (CLIP total) et la probabilité de prédire le mot à partir de ce CLIP est de 100% , on parle d ’identification perceptive totale .
Événement 2. Le participant identifie un CLIP partiel, dans ce cas, il doit faire appel à ses connaissances lexicales afin de prédire le mot, on parle alors d’ inférence lexicale .
De manière logique, le mot ne peut pas être prédit à partir du CLIP nul. Par ailleurs, il est hautement improbable de prédire un mot à partir du codage d’une seule lettre.
Ainsi, la probabilité de reconnaître un mot, P(W) peut être estimée par l’équation (2) suivante:
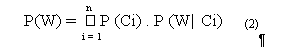
où P(Ci) est la probabilité d’occurrence du CLIP Ci, (parmi l’ensemble des n CLIPs possibles, un seul CLIP peut avoir lieu à la fois), P( W|Ci) est la probabilité conditionnelle 9 de prédire le mot complet lorsque le CLIP Ci a été codé.
L’équation (2) possède deux composantes: une composante visuelle, P(Ci), i.e., la probabilité d’occurrence d’un CLIP Ci, et une composante lexicale, P(W|Ci), i.e., la probabilité de prédire le mot à partir du CLIP Ci.