5-1 Identification perceptive de mots et de pseudomots : Expérience 1
La tâche du participant était d’identifier précisément des mots et des pseudomots présentés brièvement selon le paradigme de la position variable du regard.
5-1-1 Méthode
Participants. Vingt participants droitiers, volontaires et de langue maternelle française ont participé à cette expérience. Tous avaient une vue normale ou corrigée. Les participants n’ont pas été rétribués pour leur participation.
Stimuli. Pour cette expérience, nous avons sélectionné ou construit 100 stimuli de 6 lettres: 50 mots français et 50 pseudomots prononçables et orthographiquement légaux. Les stimuli ont été sélectionnés à partir de la base de données lexicale informatisée “Brulex” (Content, Mousty & Radeau, 1990). Les mots ont une fréquence d’usage moyenne de 54.3 occurrences par million. La fréquence lexicale indiquée dans la base Brulex est reprise des tables publiées par le Centre de recherche pour un Trésor de la Langue Française (Imbs, 1971). Les pseudomots ont été construits en remplaçant, de façon pseudo aléatoire, une seule lettre dans des “mots de base”, différents des « mots tests » utilisés pour l’expérience proprement dite. Les pseudomots respectaient les formes orthographiques légales de la langue française ; ils possédaient une fréquence des bigrammes moyenne similaire à celle des mots de base et des mots test (2.95, 2.92 et 2.97 occurrences par million respectivement pour les pseudomots, les mots de base et les mots test) 10 . Ces fréquences ont été calculées à partir des moyennes des logarithmes décimaux des fréquences textuelles en position initiale, interne et finale (établies sur la base d’un comptage pondéré par les fréquences d’usage des mots de tous les trigrammes constituant le mot (Content & Radeau, 1988). Tous les stimuli de l’expérience 1 sont présentés dans l’Annexe 3.
Dispositif expérimental. L’expérience était pilotée à l’aide d’un Power Macintosh 6500/250. Le script de l’expérience a été réalisé avec le logiciel Psyscope.1.2.2.PPC. Les stimuli étaient présentés à l’écran en lettres minuscules (taille 14, police Courier). À une distance de 57.3 cm, chaque lettre correspondait à 0.25 degrés d’angle visuel.
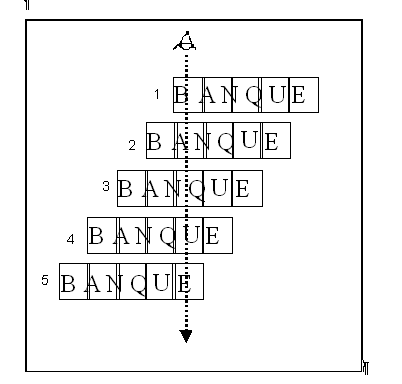
Plan expérimental. Pour le calcul des cinq positions de présentation sur l’écran, la longueur du stimulus a été divisée en cinq parties strictement égales. Le stimulus était présenté au niveau du centre de chacune de ces parties. Selon la technique de la position variable du regard précédemment décrite, le stimulus est déplacé latéralement par rapport au point de fixation (toujours au centre de l’écran) de sorte que chacune des 5 zones du stimulus puisse coïncider avec le point fixé par le participant (voir la Figure 19). Les participants ont été divisés en cinq groupes à raison de 4 participants par groupe, de manière à équilibrer la position du regard dans les stimuli. Ainsi, pour un stimulus donné, 4 participants fixaient la zone 1, 4 autres la zone 2 et ainsi de suite jusqu’à la zone 5 (carré latin). La présentation des stimuli ainsi que la succession des positions d’apparition étaient aléatoires.
Procédure. Le participant était assis face à l’écran de l’ordinateur de façon à ce que ses yeux soient à une distance d’environ 50 cm du centre de l’écran. La consigne était présentée à l’écran. Le participant débutait par une phase d’entraînement comportant 20 essais (10 mots et 10 pseudomots) différents de ceux utilisés au cours de la session expérimentale proprement dite. Chaque essai commençait avec l’apparition d’un point de fixation au centre de l’écran (constitué par le signe “+”) pendant 1500 ms. Il était ensuite remplacé par le stimulus présenté pendant une durée de 34 ms. Cette durée de présentation a été définie au cours d’un pré-test de façon à éviter « un niveau plafond » pour les mots. Un masque, constitué d’une suite de six dièses (#) succédait immédiatement à la présentation du stimulus ; il était présenté à la même position que le stimulus. Il restait à l’écran pendant 1000 ms. Les participants avaient pour consigne de focaliser leur attention au centre de l’écran (en fixant le point de fixation) et ensuite de taper le stimulus perçu à l’aide du clavier de l’ordinateur. La longueur des stimuli n’était pas précisée par l’expérimentateur. Les participants étaient encouragés à taper les quelques lettres perçues lorsqu’ils n’avaient pas identifié le stimulus dans sa totalité et ceci indépendamment de leurs positions dans la séquence. Les erreurs de frappe pouvaient être corrigées. Ils validaient leur réponse et déclenchaient l’essai suivant en appuyant sur la touche “ entrée ”. L’expérience avait lieu en un seul bloc et durait environ 20 minutes. Une pause avait lieu après 50 essais. La variable dépendante mesurée était le pourcentage de réponses correctes. Une réponse était considérée comme correcte lorsque le participant rapportait toutes les lettres dans le bon ordre. Du fait de la difficulté de la tâche, le temps de réaction n’a pas été enregistré.