5-2-3 Simulation 1 : Nombre de « voisins CLIP » de même longueur que le stimulus
Dans la simulation présentée au paragraphe 4-5 des données empiriques de Brysbaert et al., (1996), la contrainte lexicale, représentée par le nombre de mots « voisins CLIP » a été calculée à partir de probabilités empiriques d’inférence des mots, obtenues dans une tâche de complétion de trigrammes. Nous allons tester, dans un premier temps, si le nombre de voisins CLIP compté à partir d’une base de données lexicale peut rendre compte de l’EPR dans les mots. La nouvelle base de données « Lexique » (New, Pallier, Ferrand & Matos, 2001) a été utilisée pour estimer ces paramètres lexicaux.
Nous avons déterminé, pour chacun des CLIPs sélectionnés (cf., Table 3) et pour chaque stimulus mot de l’expérience 1, le nombre de « voisins CLIP » de 6 lettres N(Ci), partageant strictement les mêmes lettres que le mot cible, aux mêmes positions, d’après la base « Lexique » (New et al., 2001). Par exemple, le CLIP partiel « BAN**E » identifié à partir du stimulus « BANQUE » active tous les mots de 6 lettres contenant ces 4 lettres aux mêmes positions comme « BANQUE », « BANALE », « BANANE », etc.
La probabilité de prédire un mot à partir d’un CLIP donné P(W|Ci), a été estimée d’après l’équation (5) :
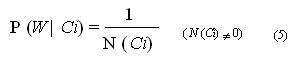
Enfin, la probabilité de reconnaître un mot a été calculée selon l’équation (2) :

Les résultats de ces calculs sont présentés dans la Figure 22 avec les données des pseudomots de la Figure 20 pour une comparaison.
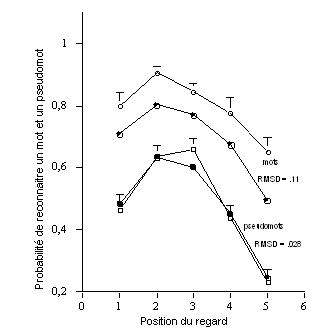
Comme on peut le voir sur la figure, la courbe théorique de l’EPR dans les mots possède une forme classique en « J » inversé comme la courbe empirique ; cependant, la hauteur de la courbe est « sous-estimée », comme l’indique la valeur relativement élevée du RMSD (.11).
Les résultats, obtenus à l’issue des présentes simulations, indiquent que l’estimation des candidats lexicaux activés par le nombre de « voisins CLIP » de même longueur que le stimulus ne rend pas compte de l’effet exercé par la contrainte lexicale sur la reconnaissance des mots.
Dans ce qui suit, nous allons tenter d’améliorer l’ajustement de la courbe théorique aux données empiriques, en modifiant un certain nombre de paramètres.
(1) Le modèle CLIP repose sur un postulat en désaccord avec les données de la littérature (e.g., Humphreys et al., 1990 ; Peressoti & Grainger, 1995 ; 1999 ; Whitney, 2001). Dans ce modèle, l’unité de codage est la lettre à une position spécifique donnée ; autrement dit lorsqu’une lettre est identifiée, sa position dans la séquence est automatiquement codée (voir aussi McClelland & Rumelhart, 1981 ; Paap et al., 1982, pour une proposition similaire). Un codage de la position absolue des lettres dans les mots est cependant contestable étant donné que la perception de l’ordre des lettres dans une séquence sans signification est très instable, en particulier lorsque la durée de présentation est brève (Huey, 1908 ; Coltheart, 1984). Afin de tester davantage la relation entre l’identification des lettres et le codage de la position sérielle des lettres dans la séquence 11 , nous allons, dans le paragraphe qui suit, ré-analyser les données de l’expérience 1 au niveau de la lettre. Ainsi, au lieu de déterminer la proportion de stimuli complets correctement identifiés (cf. Figure 20), nous allons mesurer le nombre de lettres correctement identifiées pour chaque position du regard, indépendamment de leur position sérielle dans la séquence. Si, comme le postule le modèle CLIP, le codage de l’identité et de la position des lettres est automatique, le nombre de lettres correctement identifiées devrait être significativement plus élevé dans les mots que dans les pseudomots.
(2) De plus, au cours de la simulation précédente, tous les candidats lexicaux compatibles avec un CLIP donné étaient inclus dans l’estimation de la contrainte lexicale des mots. Néanmoins, comme le soulignent, par exemple, Grainger et collaborateurs (1989), ce n’est pas tant le nombre, mais plutôt, la fréquence des voisins qui interfère avec la reconnaissance du mot cible. La présence d’au moins un voisin de plus haute fréquence que le stimulus mot entraîne une interférence du traitement du stimulus (voir aussi Carreiras et al., 1997 ; Grainger & Jacobs, 1996 ; Grainger & Segui, 1990 ; Paap et al., 1982). Afin de fournir une meilleure estimation de la nature des candidats lexicaux impliqués dans la reconnaissance des mots, nous allons conduire une analyse qualitative des erreurs commises par les participants au cours de l’expérience 1, lorsque ceux-ci n’avaient pas identifié le stimulus.