II.1.2.Les architectures d’un modèle d’IAL
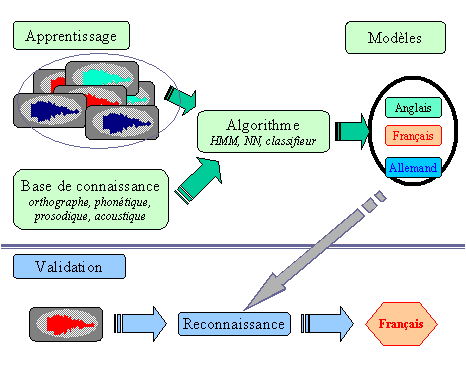
Un système d’IAL se construit toujours en deux étapes : apprentissage et validation. Ainsi, l’étape d’apprentissage établit un modèle de chaque langue à reconnaître, à partir d’un ensemble de données, constituées du signal de parole de plusieurs locuteurs, de segmentation phonémique, de motifs articulatoires. En phase de test (validation ou développement 62 ), le signal de parole à identifier est comparé aux modèles de langues construits, afin de déterminer la langue de l’extrait (Figure 3.1). L’une des difficultés majeures de l’IAL est de bien justifier que c’est la langue parlée elle-même qui est reconnue, et non le locuteur (ou d’autres indices présents dans le signal enregistré). Ainsi, pour éviter que le système identifie le locuteur, les bases d’apprentissage et de test contiennent toujours des locuteurs distincts (Dutat, 2000).
Avant d’effectuer l’identification, les signaux de paroles sont le plus souvent traduits sous la forme d’unités symboliques. Deux solutions sont possibles pour assigner une valeur discrète à un motif acoustique (par exemple, lors de la reconnaissance des phonèmes) :
- Un modèle est établi pour l’ensemble des langues (Zissman et Berkling, 2001). Chaque signal de parole est traduit dans une représentation unique indépendante des langues à identifier.
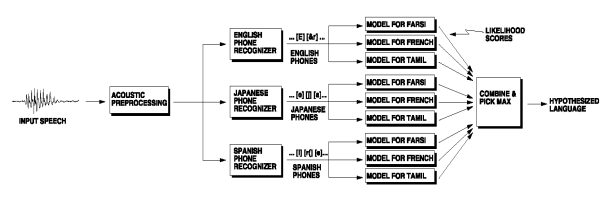
- L’encodage en unité discrète est dépendant des langues à reconnaître. Dans ce cas, le passage à identifier est encodé dans chaque langue. Concrètement, le nombre d’encodeurs est limité au nombre de langues ayant les données nécessaires à la fabrication d’un système de reconnaissance de phonèmes. Cette technique est beaucoup plus coûteuse que la précédente, tant d’un point de vue informatique qu’humain, lors de la segmentation en unité linguistique (Figure 3.2).
Ainsi, les applications d’IAL se subdivisent en deux types: les systèmes non supervisés où les motifs acoustiques permettant la distinction des langues doivent être trouvés de manière automatique et les systèmes supervisés pour lesquels les motifs acoustiques sont appris. Les systèmes non supervisés sont généralement plus efficaces pour les courtes durées et les systèmes supervisés donnent les performances les plus élevées en IAL 63 (Zissman et Berkling, 2001).