IV.2.3.Représentation spectrographique de la F0
Nous voulons maintenant estimer si le réseau TRN peut traiter une information traduite directement de manière analogique, sans passer par l’artifice de la courbe de Gauss, pour transmettre des valeurs analogiques, à partir des valeurs numériques d’autocorrélation.
La première partie consacrée à l’Identification Automatique des Langues a nécessité une représentation acoustique du signal de parole. Une répercussion de ce travail est l’utilisation d’un spectrogramme (basé sur une échelle de perception ou non) pour représenter la partie prosodique dédiée à la fréquence fondamentale. Cette nouvelle représentation n’a pas été choisie pour améliorer les performances, mais pour procurer une représentation du signal, plus proche de l’analyse de la cochlée. Ainsi, la première couche d’entrée du réseau est constituée par une représentation spatio-temporelle du signal.
Nous avons envisagé d’étudier trois représentations des fréquences entre 0 et 400Hz :
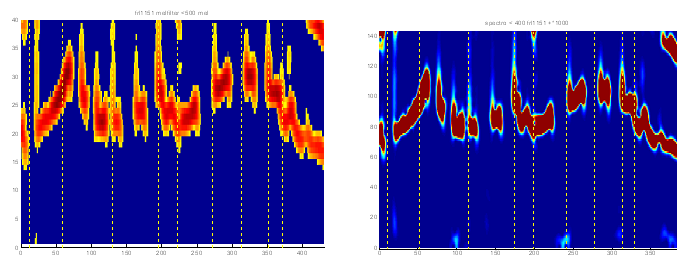
- un spectrogramme à bande étroite (Figure 5.14 droite) ;
- un cochléogramme ;
- un spectrogramme fondé sur une échelle Mel (PRAAT : Melfilter, Figure 5.14 gauche).
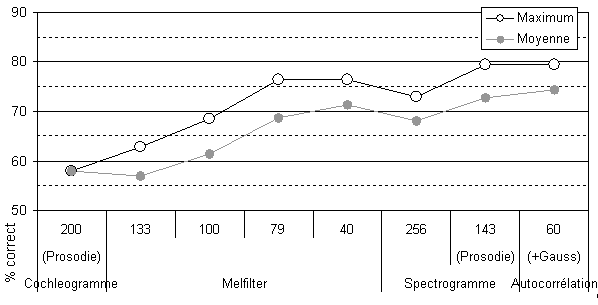
Dans un premier temps, chacune de ces représentations a été évaluée sur la tâche d’identification lexicale avec le corpus LSCP (Figure 5.15). Le cochléogramme donne un résultat plutôt décevant 104 . L’utilisation de la totalité du spectrogramme à bande étroite donne des résultats honorables, ce qui confirme qu’il est possible d’utiliser la totalité du spectre pour avoir une estimation de la fréquence fondamentale. La restriction de ce spectre aux bandes de fréquences inférieures à 400 Hz donne les meilleurs résultats, proches de ceux observés avec la F0 obtenue par autocorrélation. L’utilisation des filtres basés sur une échelle Mel nécessite 40 neurones pour donner les meilleurs résultats, qui reste tout de même inférieur à la présentation de la prosodie par le spectrogramme.
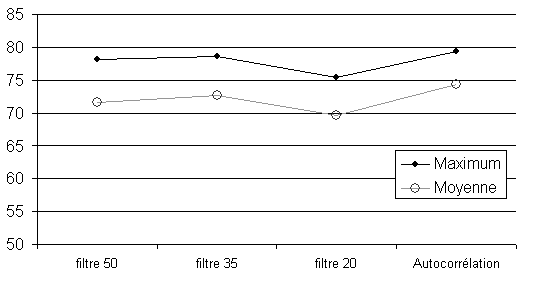
La différence entre la représentation Melfilter et le spectrogramme provient sans doute d’un niveau de bruit plus élevé. Effectivement la représentation par spectrogramme est beaucoup moins bruitée. Nous proposons d’ajouter un filtre qui mettra à zéro les unités dont l’intensité est faible (i.e. inférieure à seuil donné Figure 5.16).
Lors de l’étude de cette représentation par spectrogramme, deux problèmes s’opposent : 1) le réseau TRN a besoin d’un nombre important de neurones activés pour coder la F0 ; 2) plus le nombre de neurones activés est grand, plus le signal sera bruité.
L’ajout d’un filtre pour éliminer le bruit permet d’améliorer les performances (Figure 5.17). Cependant, il serait plus satisfaisant d’avoir un filtre adaptatif à l’environnement ambiant.