IV.2.4.Application du TRN à d’autres langues
Nous allons maintenant examiner nos méthodes avec un corpus plus important (MULTEXT). Il est constitué de courts passages au lieu de phrases, et contient plusieurs locuteurs. En outre, le discours est plus proche d’un discours non contraint que le corpus LSCP. Il s’agit maintenant de passages et non plus de phrases isolées. En outre, nous ne présentons pas les résultats obtenus pour F0, mais ceux fournis pour une combinaison de la F0 et de l’intensité 105 . Le passage d’une représentation à l’autre ne provoque pas une différence significative.
Nous retrouvons des performances inférieures avec le corpus MULTEXT pour le Français, par rapport au corpus LSCP. Le taux d’identification de l’Anglais reste inférieur à celui du Français (Tableau 5.11 et 5.12). Comme pour les travaux précédents, nous retrouvons que le contour de la fréquence fondamentale a moins d’impact sur l’identification des mots de fonction et de contenu en Anglais qu’en Français. En outre, les performances sont indiquées pour la population de 50 réseaux. L’écart type des performances de la population est très faible, et une sélection effectuée pendant la phase d’apprentissage ne permet pas d’améliorer les performances. Il s’en suit que tous les réseaux TRN exhibent des performances voisines, et sont en mesure de distinguer les mots de contenu des mots de fonction.

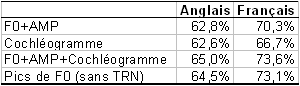
En outre, nous avons étudié les résultats du cochléogramme. Les indices prosodiques peuvent être utilisés pour marquer une distinction entre les mots de contenu et les mots de fonction. L’adjonction d’une représentation spectrale permet d’améliorer les performances. Le taux d’identification est inférieur pour l’Anglais (cf. Tableau 5.12).
La section précédente (IV.2.1) a montré une différence de comportement suivant la segmentation (soit les groupes de mots de même catégorie lexicale, soit les mots). Effectivement, les performances sont améliorées pour les mots avec la durée, mais diminuent lorsqu’il s’agit de prototype prosodique. Le TRN utilisant la prosodie, les taux d’identification devraient donc être inférieurs dans le cas des mots.
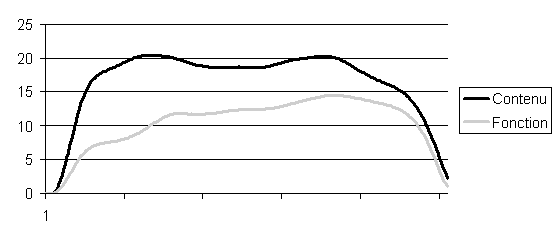
Pour obtenir l’avant-dernière ligne du tableau 5.12, toutes les combinaisons des réseaux TRN ont été étudiées (50 x 50 essais). A titre de comparaison, nous avons effectué la même opération avec seulement les réseaux qui ont encodé la F0. Les performances sont alors de 71,5 % pour le Français, ce qui reste inférieur au mélange obtenu avec la cochlée (73,6 %). Le cochléogramme a donc une influence sur les performances d’identification. La figure 5.18 représente l’activation moyenne au cours du temps des neurones d’entrées en fonction des bandes de fréquences, pour les catégories fonction et contenu. L’intensité apparaît comme étant plus faible pour les mots de fonction pour toutes les bandes de fréquences, notamment pour celles les plus basses, correspondant à la prosodie. L’influence de cet indice devrait être étudiée de manière isolée pour l’identification lexicale.
Le TRN exécute la distinction Contenu/Fonction avec un taux proche de la détection explicite des pics F0. Ces deux taux sont supérieurs à une estimation aléatoire. Les corpora Français LSCP et MULTEXT donnent des performances différentes, mais leur contenu syntaxique diffère également. Le corpus LSCP contient seulement des phrases entre 15 et 21 syllabes, alors que le corpus MULTEXT est constitué de courts passages, ayant une structure syntaxique plus proche du discours spontané. Néanmoins ces distinctions ne rendent pas impossible la catégorisation lexicale.
L’intérêt de ce travail est également d’observer le comportement du TRN pour d’autres langues. Le tableau 5.13 indique que le contour intonatif peut également être employé pour identifier les catégories lexicales pour l’Anglais. En conclusion, le TRN peut exectuer une catégorisation lexicale des mots isolés comme les nouveau-nés ont pu l’accomplir dans la tâche perceptuelle décrite dans Shi et coll. (1999).
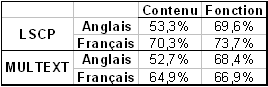
Le tableau 5.13 donne les performances d’identification de chaque catégorie fonction et contenu. La majorité des mots de contenu sont identifiés en Français, alors que ceux-ci sont moins correctement identifiés en Anglais. Pour les deux langues, plus de la moité des mots de contenu peuvent être identifiés. Les mots de fonction sont identifiés de façon identiques dans les deux langues.