V.1.Catégorisation lexicale perturbée
La première expérience réalisée avec le TRN doit rendre compte des difficultés des enfants SLI pour la syntaxe. Nous postulons que les difficultés pour appréhender la syntaxe proviennent d’un échec de la reconnaissance des mots de fonction et de contenu, catégories grammaticales de bases. Nous choisissons donc d’affaiblir les performances de la tâche d’identification lexicale présentée dans le chapitre précédent. Cette section ne tient compte que du corpus LSCP Français et de la segmentation en groupes de mots de fonction ou de contenu.
Maintenant, nous allons décrire les expériences tentées pour réduire cette classification. Pour pouvoir diminuer la résolution temporelle du réseau, nous choisissons d’augmenter les constantes de temps des unités du réseau.
Dans un premier temps, nous perturbons uniquement la couche de contexte (StateD), jusqu’à supprimer les connexions entre ces deux couches. Dans ces conditions, les performances sont très peu altérées. Ceci était prévisible, puisqu’une petite portion de la fin des groupes de mots (<100 ms) suffit pour les identifier (cf. Chap. 6 section IV.2.1). Ainsi, cette information peut être traitée uniquement par les neurones de la première couche cachée (State). Nous avons vu que les réseaux TRN pouvaient utiliser la représentation MOMEL pour distinguer les catégories lexicales. Or, cette représentation ne contient pas d’indice micro-prosodiques. Nous avons donc testé l’influence des constantes de temps de la couche de contexte sur la population de réseau. Là encore, les performances sont peu influencées par cette modification (légère diminution de 68 % à 67 %). Dans ce contexte, la catégorisation effectuée par le réseau requiert un traitement local qui est assuré par la couche State du réseau. La couche StateD est loin d’être inutile, car elle est indispensable lors du traitement des structures globales. En outre, elle ne pertube pas la catégorisation des structures locales.
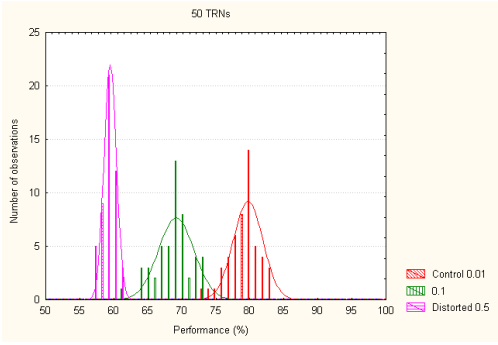
Nous considérons alors la première couche d’activation du réseau (State). Les constantes de temps sont augmentées (de 0.01s pour la population normale à 0.5s pour la population altérée). Nos premiers résultats ont permis de trouver une performance proche du hasard. Une première population de 50 réseaux (contrôle) distingue les catégories lexicales (F/C) avec une moyenne de 75 % correct sur le corpus de LSCP. Pour diminuer la sensibilité à la structure temporelle dans le TRN nous avons augmenté les constantes de temps du réseau pour produire 50 réseaux altérés. Les réseaux perturbés ne pouvaient accomplir correctement la même tâche (moyenne de 50 %, et maximum pour 53 % 118 ; Blanc et Dominey, 2001 et Blanc et coll., 2003 a&b).
La modification des constantes de temps de la couche State entraîne donc la perte des facultés nécessaires à l’identification des catégories grammaticales (Figure 6.2). Ces résultats illustrent donc les difficultés que peuvent éprouver les enfants SLI avec le traitement des mots de fonction. Dorénavant, nous n’utiliserons que l’augmentation des constantes de temps de la couche State. Ainsi, les constantes de temps des réseaux altérés ont une valeur de 0.5, alors que les réseaux contrôles ont une valeur de 0.01.