V.3.3.À partir du cochléogramme
Nous choisissons de reprendre le codage du son par cochléogramme 120 étudié dans les chapitres IAL et de catégorisation lexicale. Cette représentation est fondée sur des données issues de la psychoacoustique.
La première difficulté est de fixer l’intensité du bruit. Nous faisons en sorte de rester au même niveau que précédemment. Ainsi, l’activation maximale des unités du réseau est 40 pour le bruit. Mais chaque unité possède une activation différente. En outre, le ton pur peut être détecté même lorsque son intensité est très faible, quand les deux stimuli sont comparés. Comme pour l’expérience précédente (section IV.3), un seuil sera appliqué pour simuler un apprentissage. Ainsi, les vecteurs générés pour les stimuli incluant le ton pur seront différents de celui ne contenant pas le ton pur, mais ils pourront être confondus en dessous d’un seuil d’apprentissage fixé. Le seuil est fixé à 10. Cette valeur a été obtenue après sélection, de façon à ce que le profil des réponses reproduit le profil observé chez les enfants SLI, avec un seuil d’apprentissage commun aux réseaux altérés et contrôles.
L’utilisation de cette nouvelle représentation permet qu’un plus grand nombre de réseaux puisse répondre aux cinq conditions de la tâche. Sans le seuil d’apprentissage, les seuils d’intensité restent identiques entre les réseaux contrôles et les réseaux altérés. Cependant, l’application du seuil fait que certains réseaux ne répondent plus aux cinq conditions. Dans ce cas, la valeur d’intensité nécessaire est considérée comme étant supérieure à 110 dB.
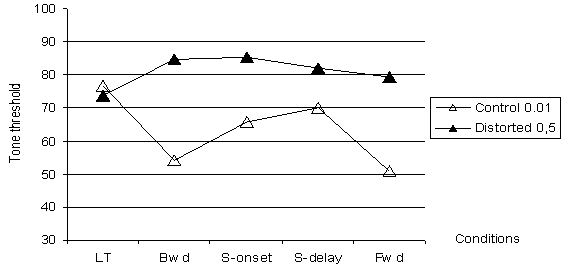
Lorsque les 50 réseaux sont pris en compte, les réseaux altérés et contrôles ne différent jamais sur la tâche contrôle avec le ton long, quel que soit le seuil d’intensité. Mais les deux populations se distinguent sur toutes les conditions, où le ton pur dure seulement 20 ms. Ainsi, les réseaux sont donc bien sensibles aux durées des stimuli. Lorsqu’ils sont altérés, ils ne perçoivent plus le ton pur lorsque celui est bref. Cependant, si les quatre conditions où est présent le ton bref (20 ms) sont comparées, la plus grande différence entre les réseaux contrôles et altérés apparaît pour la tâche Forward, et non pas pour la pour la tâche Backward Masking. Comparés aux êtres humains, les réseaux ont un seuil d’intensité assez élevé pour discerner le ton pur bref dans la tâche Backward (5 dB de différence entre la condition Long-tone et la condition Backward pour les réseaux contrôles contre 20 dB pour les enfants contrôles, Figure 6.12).
Nous suggérons alors de ne garder que les réseaux contrôles effectuant la tâche Backward avec un seuil inférieur à la condition contrôle, et de les comparer aux mêmes réseaux altérés (Figure 6.13). Malgré ces dispositions l’écart entre les réseaux contrôles et altérés reste important pour la condition Forward. Il est possible que la représentation du cochléogramme ne tienne pas assez compte du phénomène de double masquage. Ce phénomène de double masque ne peut se produire uniquement que dans la condition Bandpass. Ainsi, bien que les données fournies au réseau soient issues de la condition Bandpass, le profil des performances ressemble plus à celui de la condition Notched, qui supprime cet effet de double masquage.
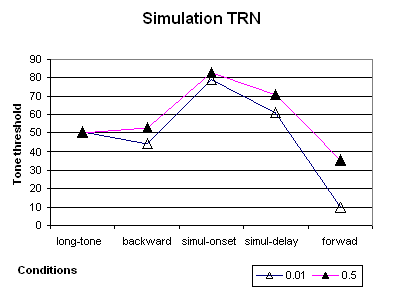
Comme pour la tâche précédente de discrimination auditive rapide, nous suggérons d’étudier l’influence d’un seuil de discrimination élevé, pour simuler le facteur d’apprentissage. Dans ce contexte, les constantes de temps du réseau restent inchangées (Figure 6.14).
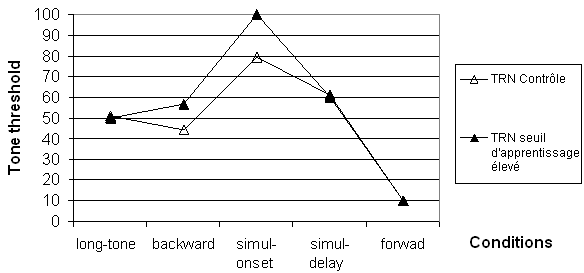
Cette fois-ci, les conditions Forward et Simul-delay ne permettent pas de distinguer les réseaux contrôles des réseaux altérés, alors que les conditions Backward et Simul-onset les distinguent. En conclusion, il semble que pour pouvoir répliquer les résultats de Wright et coll. (1997) les constantes de temps, (i.e. diminuer les capacités de traitement temporel rapide) et le seuil de discrimination (i.e. diminuer l’entraînement pour la tâche) doivent être augmentées.
Finalement notre modèle semble rejoindre les principales critiques effectuées pour la tâche de Wright (1997). Seul un manque d’apprentissage semble pouvoir expliquer la différence entre les modèles contrôles et altérés pour la condition Backward Masking, alors que des constantes de temps élevées différencient les populations dans toutes les conditions où intervient le ton pur bref.