Le modèle en cascade ou interactif
Défini par Dell et collaborateurs (Dell, 1986, 1988 ; Dell, Schwartz, Martin, Saffran & Gagnon, 1997), ce modèle connexionniste, bien que faisant la même distinction entre les trois niveaux de traitement (i.e. celui de la signification, celui des mots et celui des phonèmes), s'oppose à celui de Levelt par une forme composée de la signification du mot, mais surtout par l’interaction existant entre les trois étapes (figure 3). Il est important de noter qu'il n'y a pas d'inhibition, mais une rétroaction des activations allant du codage de la forme du mot à la préparation conceptuelle. Les différents niveaux vont donc être reliés entre eux par des connections excitatrices bidirectionnelles. Après avoir succinctement tracé les grandes lignes de ce modèle, nous présenterons un résumé des évidences expérimentales ayant conduit à sa création.
Contrairement au modèle de McClelland et Rumelhart (McClelland & Rumelhart, 1981 ; Rumelhart & McClelland, 1982) qui établi un schéma de l’activation interactive lors des mécanismes d’identification visuelle de mots, pour Dell, l'accès aux items stockés dans le lexique mental se fait via un processus en deux étapes : la sélection du lemme suivie d'un encodage phonologique. La vision de l'image d'un chat par exemple (e.g. CAT dans le modèle) va dans un premier temps activer toutes les caractéristiques sémantiques associées à ce mot. Cette activation va se propager à tout le réseau jusqu’à l’étape où les sons entrant dans la composition du mot vont être extraits. La présence de connections excitatrices bidirectionnelles va avoir pour avantage majeur de préactiver les trois niveaux de traitement sous-jacents. Ainsi, lors des premiers stades du processus de sélection lexicale, la rétro-activation ainsi générée va se surajouter à l'activation des items lexicaux compétiteurs, tel que CAT, DOG ou RAT, via les caractéristiques sémantiques sélectionnées (animé, animal, quadrupède, etc.). Sur le même principe, le flux d’activation en provenance du niveau phonologique va entraîner, au stade lexical, l’activation d’items présentant uniquement des caractéristiques phonologiques communes avec le mot cible, tel que MAT. La représentation lexicale appropriée va être sélectionnée au terme d’un processus de compétition et de décision en fonction de certaines contraintes grammaticales, comme la catégorie syntaxique, le genre, ou le nombre. A la sortie du processeur, le lemme va alors servir d’input à la couche de neurones suivante, c'est-à-dire à celle gérant l’encodage phonologique. Les caractéristiques phonémiques (i.e. lettre initiale, nombre de syllabes, voyelles composant le mot) recevant le plus d’activation vont être à leur tour sélectionnées et assemblées entre elles afin de constituer la trame du mot. Cette trame représente l’output de la dernière étape du traitement de la parole.
Ce type de modèle, avec activation des différentes couches de neurones en cascade, implique que chaque information pertinente active la forme phonologique correspondante. Une unité lexicale non sélectionnée peut dans de telles conditions propager son activation à tout le réseau dont la strate encodant les caractéristiques phonologiques des mots.
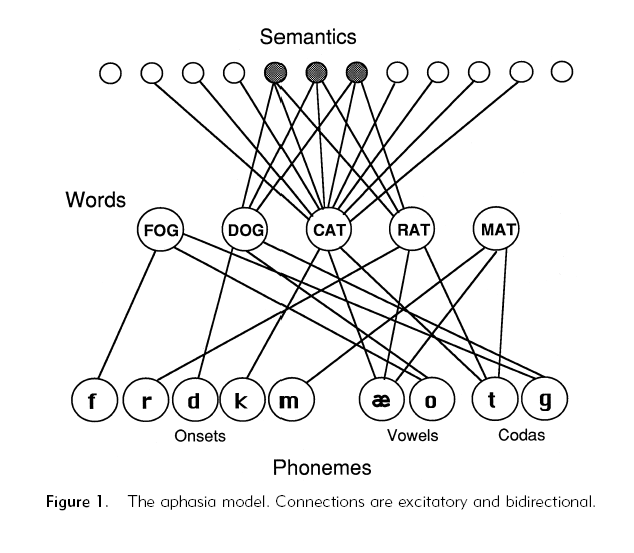
Un des arguments majeurs en faveur de l'interactivité est issu de l’analyse des erreurs spontanées de langage. Nous avons vu précédemment que ces dernières pouvaient être catégorisées en fonction de la qualité des informations substituées : soit les indices échangés étaient de type sémantique (e.g. DOG au lieu de CAT), soit phonologique (e.g. MAT au lieu de CAT). Mais il arrive parfois que les compétiteurs sémantiques présentent également des sonorités identiques, d’où l'existence d'erreurs dites mixes (Dell, 1986). Comme leur nom l’indique, ces dernières mélangent substitutions d'indices sémantiques et phonologiques, par exemple lorsqu'un locuteur prononce le mot RAT au lieu du mot attendu CAT. Dans ce genre de cas, les deux items présentent bien des traits sémantiques communs, mais ils sont également reliés phonologiquement. Si le modèle sériel se trouve dans l’incapacité d’élaborer une explication valide à l’émergence de ce type d’erreurs, le modèle en cascade propose une hypothèse de fonctionnement. En reprenant l’exemple cité plus haut, l’activation du lemme CAT ainsi que de son set de caractéristiques grammaticales, va aboutir à l’activation des différents phonèmes le constituant, /k/, /ae/ et /t/. Mais, certaines informations sémantiques comme ‘animé’, ‘mammifère’ ou ‘animal’ vont aussi co-activer les lemmes compétiteurs RAT et DOG. Cependant, la rétro-activation en provenance du niveau phonologique va suractiver l’item RAT par rapport à DOG puisque les représentations phonologiques de RAT et CAT présentent des traits identiques, à savoir /ae/ et /t/. La probabilité de commettre une erreur mixte devient alors plus élevée que celle de faire une erreur purement sémantique ou phonologique. Cette hypothèse a été corroborée par les données expérimentales obtenues par Dell et Reich (1981) et Martin, Dell, Saffran et Schartz (1994).
Cutting et Ferreira (1999) ont également rapporté des résultats ne pouvant s’expliquer que par la présence d’une interaction entre les différents niveaux de traitement. Ils ont employé pour cela une variante du paradigme d’interférence via l’utilisation d’homophones 7 en remplacement des mots simples. Les images étaient présentées 150ms après un distracteur auditif. Deux types d’images étaient diffusés : soit le nom possédait un homophone (e.g. ball [danse ou balle]), soit il ne possédait pas d’homophone (e.g. frog [grenouille]). Pour les homophones (e.g. ball [balle]), le distracteur auditif pouvait soit être relié au sens de l’objet imagé (e.g. /game/ [jeu]), pour soit au sens de l’homophone (e.g. /dance/ [danse]), soit non relié (e.g. /hammer/ [marteau]). Concernant les noms ne présentant pas d’homophone (e.g. frog [grenouille]) l’amorce était soit phonologiquement reliée (e.g. /frost/ [gel]), soit sémantiquement associée (e.g. /turtle/ [tortue]), soit non reliée (e.g. /piano/ [piano]). L’effet majeur extrait des quatre expériences menées est l’obtention d’une accélération des vitesses de dénomination lorsque le distracteur auditif était associé au sens non dépeint par l’image, dénotant par là même la présence d’un effet phonologique relativement précoce de l’amorce sur l’encodage du mot cible. Une explication donnée par les auteurs pour ce résultat serait la présence d’un feedback provenant du processeur phonologique, c'est-à-dire des informations phonologiques des compétiteurs, sur le mécanisme de sélection lexicale des mots cibles, alors que phonologie du mot cible lui-même n’aurait aucune influence. Ainsi, l’amorce /dance/ va activer les concepts associés, dont BAL. L’activation de ce concept va alors se propager à la sélection lexicale, puis à l’encodage de la forme du mot, et donc va pré-activer le lemme /bal/. Le retour d’activation de /bal/ sur le traitement lexical va avoir pour conséquence la facilitation de la sélection de balle, d’où des temps de réaction plus faibles pour ce type de paires de mots comparé aux non-homophones. Il y aurait mise en place d’un mécanisme de rétro-action entre les différents processeurs, et non pas entre les traitements particuliers localisés au sein des niveaux.
D'autres expériences, impliquant cette fois-ci des locuteurs bilingues, sont venues en appui de la théorie d'une activation en cascade des informations conduisant à la production des mots. Costa, Caramazza et Sebastián-Gallés (2000), ont exploité l'existence de mots particuliers, appelés ‘cognate words’ ou mots apparentés, pour comparer les performances obtenues lors d'une tâche de dénomination d'image, chez des individus bilingues espagnol-catalan. Les mots apparentés sont des noms dont la traduction dans chacune des deux langues donne des items pour lesquels la forme phonologique et orthographique est très proche, contrairement à des mots non apparentés où la traduction donne des codes phonologiques différents (voir exemples 5A et 5B).
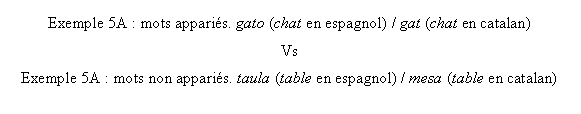
Les résultats obtenus indiquaient que les locuteurs natifs et bilingues espagnols nommaient les images faisant référence à des mots apparentés plus rapidement que celles montrant des mots non apparentés. Cet effet de facilitation a été interprété comme étant du à l'activation de propriétés phonologiques par des lemmes activés mais non sélectionnés lors du processus d'accès au lexique. L'activation de la représentation sémantique de gato va se propager aux items lexicaux des deux langues, c'est-à-dire à la cible gato et au mot non sélectionné gat, avant de diffuser vers leur code phonologique respectif. Puisque les représentations phonologiques correspondant aux mots apparentés reçoivent une activation provenant de deux sources différentes, leur dénomination va prendre moins de temps que celle de mots non apparentés, dont la représentation phonologique n'est activée que par une unique source.
Une étude plus récente, menée par Morsella et Miozzo (2002) a également apporté d'autres données empiriques en faveur d'une influence de l'encodage phonologique par des lemmes activés mais non sélectionnés. Pour cela, ils ont utilisé une extension du paradigme développé par Stroop 8 (1935), c'est-à-dire le paradigme d'interférence image-image. Dans ce type de tâche, il est présenté aux sujets un dessin d'une couleur donnée (i.e. la cible) sur laquelle est surimprimé un autre dessin d'une autre couleur (i.e. le distracteur). Il leur est simplement demandé de dénommer le plus rapidement possible l'image cible tout en ignorant le distracteur. Lors de cette étude les auteurs ont choisi des paires de mots reliés phonologiquement en anglais (e.g. BED et BELL) et d'autres non reliées phonologiquement ou orthographiquement (e.g. DOG et BELL). A noter que les noms traduits en italien composaient des paires de mots non reliés. La présentation du set d'images composites à des locuteurs de langue maternelle anglaise et italienne a donné lieu à l'obtention d'un effet de facilitation pour les paires reliées phonologiquement, mais ce uniquement chez les locuteurs anglais. Il a pu ainsi être montré que les représentations lexicales non sélectionnées n’en activaient pas moins le niveau phonologique.
En conclusion, le modèle en cascade en plus des données expérimentales compilées chez les locuteurs natifs (erreurs mixtes de substitution, paradigmes employant les homophones) est largement supporté par les résultats issus des études menées sur les bilingues, qui ont amené des preuves quant à la possibilité pour un mot non produit, mais néanmoins activé à un moment du traitement lexical, d'influencer le mécanisme d'encodage phonologique et orthographique. Voyons à présent le dernier modèle d’accès au lexique se positionnant comme alternative aux modèles sériel et interactif : le modèle en Réseaux Indépendants.