I.2.2.2. Interprétation connexionniste des effets d’AdA dans l’apprentissage de la lecture.
Le véritable obstacle à la reconnaissance de l’AdA par la communauté scientifique comme une variable influente a longtemps résidé dans son apparente incompatibilité avec les principes de fonctionnement des réseaux connexionnistes utilisés par ailleurs avec succès pour la modélisation des effets de fréquence. Tandis que l’efficacité du traitement de ces derniers modèles est favorisée par les présentations répétées de leurs exemples d’entraînement, les effets d’AdA laissent envisager que les premiers acquis puissent pénaliser dans une certaine mesure l’assimilation des informations ultérieures. Saturés par un entraînement trop intensif, les réseaux entraînés au moyen de l’algorithme classique de rétropropagation de l’erreur présentent en outre le phénomène d’interférence catastrophique, par lequel les données initiales se trouvent « écrasées » par les dernières connaissances acquises, suivant une tendance diamétralement opposée à celle prédite par les effets d’AdA.
En ouvrant la voie d’une possible réconciliation des capacités mimétiques des réseaux de neurones artificiels avec l’influence de l’AdA, les modélisations conduites par Ellis et Lambon-Ralph (2000) ont apporté la première réponse significative à cette opposition. Ces auteurs sont en effet parvenus à démontrer que le comportement d’un modèle connexionniste entraîné par rétropropagation se trouvait naturellement régi par l’AdA pour peu que les bases d'exemples présentées soient introduites en différents points de l'apprentissage, sur un mode cumulatif et intercalé. Suivant ce principe, l'entraînement du modèle est initié sur une base d’exemples "précoces", qui s'enrichissent dans un second temps d’exemples plus "tardifs", introduits lors d'une étape ultérieure de l’apprentissage. L'originalité de ce type d'entraînement consiste à permettre à l’apprentissage engagé sur les items déjà familiers de se poursuivre au moment de la présentation des nouveaux exemples. À l'issue de ces simulations, et de manière cohérente avec les précédentes observations empiriques, les taux d'erreur les plus faibles ont été relevés pour les exemples présentés au réseau dès le début de son apprentissage, y compris dans les conditions où la fréquence de présentation était équivalente sur l'ensemble des exemples "précoces" et "tardifs".
Ellis et Lambon-Ralph (2000) ont également cherché à simuler le décours naturel de l'acquisition du vocabulaire en tenant compte du fait que cet apprentissage prenait graduellement place au travers d'une accumulation constante et régulière de connaissances nouvelles. Les 200 exemples constituant la base ont ainsi été divisés en 4 sous-groupes de 50 items, et présentés toutes les 200 époques (i.e. nombre de passages de la base d'exemples), durant les 600 premières époques de l'apprentissage du réseau. L'entraînement se poursuivait ensuite sur les items "précoces" et "tardifs" jusqu'à stabilisation du réseau (au bout d'environ 5000 passes de la base d'exemples). Le graphique de la Figure 1 présente les taux d'erreurs obtenus pour chacune des bases d'exemples à partir du calcul de la distance entre la réponse attendue et la réponse fournie par le modèle après convergence. Les résultats obtenus mettent ainsi en évidence une diminution progressive des performances du réseau suivant le moment de l'apprentissage où les items ont été présentés. En outre, l'avantage observé pour les items "précoces" sur les items "tardifs" restait globalement constant sur l'ensemble des époques considérées.
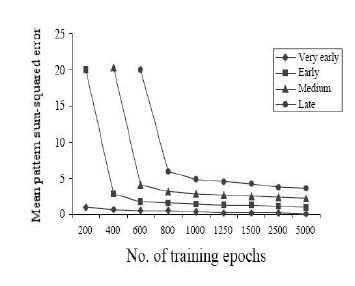
Les performances sur les bases d'exemples utilisées pour l'entraînement de réseau sont exprimées en terme de taux d'erreur, calculé en fonction de la différence entre la sortie du réseau et la réponse idéale. Plus les valeurs s'approchent de 0, meilleure est la performance du modèle. La figure montre que lorsqu'un ensemble d'exemples est introduit dans le réseau, la performance initiale est faible. Toutefois, après quelques époques d'entraînement, l'erreur moyenne diminue, la performance se stabilise et reste plus ou moins constante à travers toutes les époques d'entraînement suivantes. Les meilleures performances sont enregistrées pour les exemples introduits dès le début de l'apprentissage (losanges noirs), et les moins bonnes performances sont obtenues pour le dernier groupe d'exemples présenté au modèle (cercles noirs).
Dans les années suivantes, Zevin et Seidenberg (2002 ; 2004) sont parvenus à asseoir la problématique de l’AdA sur un cadre théorique robuste en rapprochant de manière plus élaborée et réaliste les effets de cette variable des concepts implémentés dans les modèles connexionnistes du traitement du langage écrit inspirés de celui proposé par Seidenberg et McClelland en 1989. La principale critique adressée par Zevin et Seidenberg aux travaux princeps de Ellis et Lambon-Ralph (2002) concernait les caractéristiques de la base d’exemple sur laquelle le réseau était entraîné, qui apparaissait peu conforme aux caractéristiques des langues naturelles. Les stimuli présentés étaient en effet des patterns de bits aléatoires crées en activant au hasard 20% des 100 unités composant la couche d’entrée, ce qui rendait les probabilités d’activation de ces unités entièrement indépendantes les unes des autres. Au contraire des lexiques réels décrits au précédent chapitre, la base d’exemple ainsi constituée présentait une structure interne très appauvrie puisque non organisée en fonction des contraintes régulières d’ordonnancement des lettres et des phonèmes et des variations de fréquence dans les occurrences et co-occurrences de ses différents éléments. La suppression artificielle de toute redondance entre les clusters composant les items interdisait au modèle le réinvestissement habituel des connaissances préalablement assimilées au moment de l’acquisition des nouveaux concepts. Plutôt que d’exploiter les exemples présentés pour déduire et représenter dans le poids de ses connexions les propriétés d’un système linguistique donné, le réseau était donc forcé de mémoriser successivement les patterns qui lui étaient présentés.
La possibilité que l’émergence des effets d’AdA dans le comportement des réseaux connexionnistes soit entièrement tributaire des caractéristiques des exemples utilisés pour leur entraînement a directement été investiguée par Zevin et Seidenberg (2002, simulations 3 et 4) à partir du modèle précédemment développé par Harm et Seidenberg (1999). L’entraînement a ainsi respectivement été réalisé sur deux ensembles de 34 mots monosyllabiques répartis de manière à ce que la structure des patterns orthographiques se recouvre ou non d’un groupe à l’autre. Dans les deux conditions, la fréquence de présentation des items appartenant au groupe précoce décroissait entre les premières et les dernières étapes de l’apprentissage tandis que celle des items du groupe tardif suivait une tendance exactement inverse. Au terme de l’entraînement, tous les mots de la base d’exemple avaient été soumis un nombre identique de fois au modèle. Les graphiques de la Figure 2 illustrent la manière dont se comportait le réseau sur les différents mots proposés, suivant leurs propriétés lexicales (structure infra-lexicale similaire ou non) et la phase de l’apprentissage (précoce ou tardive) au cours de laquelle ils étaient présentés avec une fréquence plus soutenue.
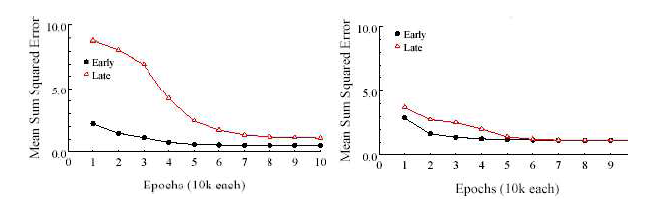
Ces données correspondent au taux d’erreur commis par le réseau à différentes époques de son apprentissage, sur des mots monosyllabiques présentés avec une fréquence élevée au début (early) ou à la fin (late) de son apprentissage. Le graphique de gauche retrace les profils de réponses obtenus lorsque les deux groupes d’items contenaient des patterns orthographiques et phonologiques non recouvrants et le graphique de droite présente les résultats correspondants lorsque les deux groupes contenaient des patterns recouvrants.
Le graphique de gauche montre que dans les conditions inhabituelles où les régularités repérées parmi les premiers mots appris par le réseau ne pouvaient être transférées aux mots appris ultérieurement, un avantage faible mais persistant était effectivement obtenu pour le traitement des mots précoces en regard des mots tardifs. Lorsque les mêmes items étaient organisés de manière à autoriser certaines ressemblances orthographiques et phonologiques entre les groupes précoce et tardif, l’influence de l’AdA disparaissait en revanche totalement du profil de réponse du réseau (Figure 2, graphique de droite). Les données recueillies par Zevin et Seidenberg (2002) prouvent donc que la manière dont le réseau apprend les items qui lui sont soumis représente sans conteste un facteur déterminant pour l’installation des effets d’AdA.
Appuyés sur ces résultats fondamentaux, Zevin et Seidenberg (2002) ont proposé d’appréhender les effets d’AdA suivant une perspective radicalement différente des conceptions antérieures. Les auteurs insistent en particulier sur la nécessité d’aborder l’acte d’assimiler certains mots à une certaine époque non comme un simple artéfact de l’enseignement de la lecture mais comme la conséquence de l’intervention des variables lexicales déterminantes pour cette acquisition, parmi lesquelles la fréquence occuperait une place privilégiée.
Zevin et Seidenberg (2002) admettent en effet que la vitesse d’assimilation et le niveau d’expertise associés au mot sont adéquatement décrits par une fonction exponentielle de la pratique7, prévoyant que chaque rencontre avec un mot améliore le traitement de cet item particulier. Si cette théorie est exacte, l’AdA ne serait donc rien de plus qu’une mesure de la fréquence d’occurrence des mots en langue dans la période de leur assimilation. Dans le contexte des modélisations, entraîner intensément un réseau de neurones sur une portion de sa base d’exemples a pour effet d’amener plus rapidement les unités impliquées vers leur niveau d’activité optimal, assurant leur assimilation rapide. A ce stade, la contribution de ces unités à l’erreur globale du réseau devient alors négligeable et les modifications appliquées aux poids des connexions s’amenuisent. De ce point de vue, l’assimilation des premiers items introduit donc bien une certaine inertie dans la dynamique du réseau, susceptible de freiner l’intégration de nouvelles données, en accord avec la proposition de Ellis et Lambon-Ralph (2000) et avec les résultats de la Simulation 3 de Zevin et Seidenberg (2002). Les données de la Simulation 4 démontrent néanmoins que cette rigidité est rapidement contrebalancée par les algorithmes favorisant le réinvestissement des connaissances relatives au traitement d’un mot particulier dans l’apprentissage des mots nouveaux de structure similaire (ex : CAPE et CAGE), pour autant que la base d’exemple présentée au modèle autorise l’application de ce principe.
Zevin et Seidenberg (2002) concluent donc de leurs modélisations que des effets durables d’AdA ne sont susceptibles d’émerger que dans des circonstances très particulières où le réinvestissement des connaissances acquises sur la base des premiers items présentés est empêché par la nature des stimuli ou les exigences de la tâche à apprendre. Ces conditions sont loin de caractériser le traitement des systèmes d’écrit alphabétiques, organisés de manière à promouvoir la détection des régularités sous jacentes aux mots présentés et permettant aux enfants d’apprendre à lire autrement qu’en mémorisant les items successivement rencontrés. En conséquence, l’impact de l’AdA sur les tâches mobilisant les capacités de conversions de graphèmes à phonèmes devrait être négligeable dans les langues alphabétiques, une fois le réseau responsable de la lecture devenu pleinement fonctionnel. La survivance de cet effet dans les langues idéographiques caractérisées par le caractère arbitraire unissant les formes écrites des mots à leur prononciation et à leur sens reste néanmoins une question ouverte. Zevin et Seidenberg (2002) insistent par ailleurs sur le fait que les performances de leur réseau tombent davantage sous la dépendance du nombre de présentations des items que sous celle du décours particulier de l’entraînement de ces items. De fait, les effets d’AdA résiduels observés empiriquement sur les performances des adultes lecteurs experts, si toutefois leur existence était bien réelle et non attribuable à une variable lexicale confondue (voir Zevin et Seidenberg, 2002 pour une discussion sur ce point), seraient entièrement attribuables à la fréquence cumulée des items, correspondant au produit de la fréquence d’occurrence d’un item par une estimation de l’intervalle de temps depuis lequel l’item en question est connu (voir aussi Lewis, 1999ab ; Lewis, Gerhand & H.D. Ellis, 2001). Les données actuellement disponibles dans la littérature permettent d’évaluer liminairement la plausibilité de ces propositions.