III.2. Développement des connaissances orthographiques et installation des effets d’AdAortho : apports de l’approche psychophysique
III.2.1. Introduction
Abordée suivant un angle plus large, la reconnaissance visuelle des mots, dont nous cherchons à cerner le développement au travers des manifestations de l’AdAortho, doit être considérée comme une activité complexe qui mobilise, outre les facteurs lexicaux, un ensemble d’habiletés visuelles spécifiques dont la description s’est trouvée à l’origine d’un important courant de recherche dans le domaine de la psychophysique. Ainsi que le mentionnent Rayner et collaborateurs (2001) dans leur large revue des apports de la psychologie cognitive, la possibilité que la lecture procède essentiellement d’une succession d’inférences basées sur le seul environnement linguistique a été considérée dans les années 70 puis rejetée suite à la démonstration de la faible participation du contexte textuel à l’identification pure des mots chez les adultes experts (voir par exemple Perfetti, Goldman & Hogaboam, 1979 ; cité par Rayner et al., 2001).
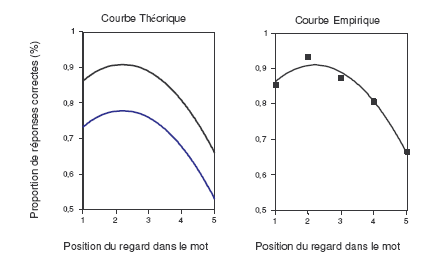
Parallèlement, les études psychophysiques conduites par Nazir et collègues dans les années 90 (Jacobs, Nazir, & Heller, 1989; Nazir, 1991; Nazir, Heller, & Sussmann; 1992 ; Nazir, O’Regan & Jacobs, 1991) ont abouti à la conclusion que la lecture ne pouvait pas être mieux décrite suivant une perspective strictement visuelle. Considérant en effet que la visibilité des lettres connaît une impressionnante diminution dès lors que ces dernières tombent dans une portion du champ visuel distante de la position de fixation courante du regard, les limites de l’acuité visuelle et la vitesse à laquelle les yeux parcourent habituellement un texte devraient rendre la lecture impraticable. Nonobstant cette apparente incompatibilité, l’exploration attentive des capacités d’identification des mots isolés a toutefois permis d’établir que les performances des adultes experts variaient subtilement suivant la position occupée par le mot sur la rétine, dans le sens prédit par les fonctions décrivant l’évolution de la visibilité des lettres (voir par exemple McConkie, Kerr, Reddix, Zola & Jacobs, 1989 pour des résultats obtenus dans des conditions de lecture naturelles, et Brysbaert, Vitu & Schroyens, 1996, Nazir, 1993 ; Nazir et al., 1991 ; Nazir, Jacobs & O’Regan, 1998 pour des données établies à partir de l’induction expérimentale de variations de la position du regard dans le mot). Les mots sont ainsi reconnus avec une précision maximale lorsque le regard se pose légèrement à gauche de leur centre et les performances diminuent ensuite régulièrement à mesure que les yeux dérivent de cette position optimale. La proportion d’identification correcte connaît en outre une diminution plus marquée lorsque les lettres situées à gauche de la fixation sont concernées. Ce phénomène est illustré par les graphiques de la Figure 33 empruntés à Nazir et al. (1991). La distribution des pourcentages d’identifications correctes de mots de 5 lettres a été représentée suivant la position de la lettre tombant directement sous le regard (évoluant entre 1 et 5), telle qu’elle pu être observée dans des conditions expérimentales (graphique de droite) et théoriquement prédite en tenant compte des limites de l’acuité visuelle (graphique de gauche et tableau du bas).
| Position de la lettre fixée | Probabilité d’identification des lettres individuelles | Probabilité d’identification du mot | ||||
| 1 | 2 | 3 | 4 | 5 | ||
| 1 | 1 | .97 | .94 | .91 | .88 | .73 |
| 2 | .95 | 1 | .97 | .94 | .91 | .78 |
| 3 | .89 | .95 | 1 | .97 | .94 | .77 |
| 4 | .84 | .89 | .95 | 1 | .97 | .69 |
| 5 | .78 | .84 | .89 | .95 | 1 | .55 |
Admettant que la probabilité d’identifier la lettre située immédiatement sous la fixation est de 1, la probabilité d’identifier la lettre voisine sur la droite est de (1-.03 = .94), tandis que la probabilité de reconnaître la lettre correspondante sur la gauche est de (1-.03 x 1.8 =.89). La probabilité d’identifier un mot fixé sur la première lettre correspond donc à : (1 x .97 x .94 x .91 x .88 = .73). Le détail des calculs sur les 5 positions de fixations potentielles est donné dans le tableau ci-dessus. Le graphique de gauche présente les prédictions du modèle quant à la variation des proportions de réponses correctes suivant la position du regard dans le mot. La courbe bleue reprend les résultats présentés dans le tableau et la courbe noire présente les mêmes données modifiées par une valeur constante pour atteindre la hauteur de la courbe empirique rapportée dans le graphique de droite. Dans les deux conditions, la probabilité d’identification du mot se trouve à son maximum pour les fixations légèrement à gauche de son centre, et décroît progressivement à mesure que le regard dérive de cette position optimale, suivant une pente plus marquée dans les conditions où la partie droite du mot est fixée, laissant la majorité des informations tomber dans le champ visuel gauche.
Le calcul des courbes théoriques rapportées ci-dessus, dont la forme s’accorde remarquablement avec les données expérimentales, satisfait aux principes du modèle mathématique élémentaire développé par Nazir et collaborateurs (1991) à partir des trois présupposés suivants : 1) l’identification des mots est basée sur les lettres (Massaro &Klitzke, 1977, cité par Nazir et al., 1991), 2) les lettres d’un mot sont identifiées indépendamment les unes des autres et 3) la contribution d’une lettre donnée à l’identification d’un mot est proportionnelle à son degré de lisibilité, soit à la quantité d’informations visuelles récupérables à partir de la lettre concernée, suivant la position du regard dans la séquence. Dans les détails, la probabilité d’identifier la lettre située sous la fixation est considérée comme maximale, étant donné la haute résolution de la vision centrale, et a donc conventionnellement été fixée à 1. Compte tenu de l’augmentation linéaire de l’angle de résolution minimum à l’intérieur des 10° centraux du champ visuel (ex : Olzak & Thomas, 1986 ; cité par Nazir et al., 1991), la probabilité d’identifier les lettres voisines est en revanche supposée diminuer par pas constants pour chaque lettre située en vision périphérique. La valeur du taux de diminution est imposée par les conditions expérimentales de présentation des stimuli et s’élève à .03 dans l’exemple proposé. Enfin, considérant que certaines données expérimentales attestent d’un taux de reconnaissance plus élevé pour les lettres présentées dans le champ visuel droit plutôt que gauche(ex : Bouma, 1973 ; Bouma & Legein, 1977 ; cité par Nazir et al, 1991), le modèle prévoit que le taux de diminution de la lisibilité des lettres tombant à gauche de la région fixée soit accentué par introduction d’un ratio d’asymétrie évalué empiriquement à 1.8 par Nazir et al. (1991). La probabilité d’identifier une séquence de 5 lettres fixée à une position donnée correspond alors à la multiplication des probabilités d’identification de ses lettres individuelles, en application de l’équation suivante :
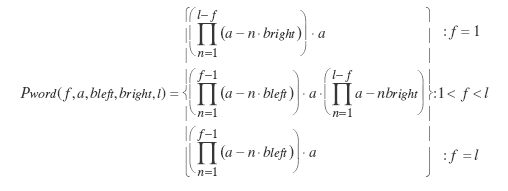
où Pword(f, a, b left/b right,l) représente la probabilité d’identifier un mot en fonction de la position f de la lettre fixée dans la séquence (en unités de lettres), de la probabilité a d’identifier la lettre directement fixée, des taux de diminution b left et b right de la probabilité d’identifier les autres lettres de la séquence suivant leur excentricité à gauche (left) ou à droite de la fixation (right), et de la longueur l de ce mot.
Les récentes révisions du modèle initial de Nazir et collaborateurs (1991) engagées par Kajii et Osaka (2000) et poursuivies par Benboutayab (2004) sont d’un intérêt particulier pour la question qui nous préoccupe dans la mesure où elles conceptualisent avec précision l’intervention des connaissances lexicales en cas de codage parcellaire des informations visuelles soumises à l’entrée du système. Il est en effet envisagé que l’identification visuelle des mots procède des étapes suivantes. En première instance, chaque mot écrit rencontré permet la création d’un pattern visuel codant l’identité et la position abstraite des lettres perçues. Ce pattern, labellisé « CLIP » (Code for Letter Identity and Position in Word), est susceptible, suivant les cas, de comprendre la totalité ou une partie seulement des lettres de l’input, on parlera alors respectivement de CLIP total ou de CLIP partiel. A l’extrême, le CLIP nul peut être rencontré dans les conditions où aucune des lettres de la séquence présentée n’a pu être identifiée. A titre illustratif, la Figure 34 détaille les 32 CLIPs susceptibles d’être encodés par le système visuel en réponse à la présentation du mot TABLE. De manière plus générale, un mot de i lettre peut être à l’origine de la création de 2i CLIPs distincts.
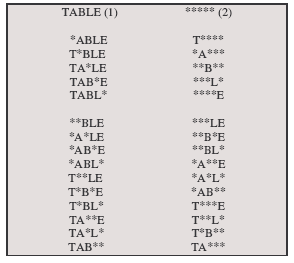
Les étoiles représentent la ou les lettre(s) non identifiée(s) dans le mot. La condition (1), celle du CLIP total, où toutes les lettres de l’input ont été encodées à la bonne position représente l’unique circonstance dans laquelle la probabilité de reconnaissance d’un mot dépend entièrement de celle de ses lettres individuelles. La condition (2) est le cas du CLIP nul où aucune lettre n’a été reconnue. Toutes les autres conditions (entre 1 et 4 lettres non reconnues) représentent les CLIPs partiels. (d’après Kajii, 2000, repris par Benboutayab, 2004).
La survenue d’un CLIP total (condition 1 dans la Figure 34) représente l’unique circonstance dans laquelle la récupération d’un mot repose sur une identification perceptive pure, et où sa probabilité de reconnaissance peut être calculée suivant les modalités prévues par le modèle de Nazir et collègues (1991). Tout CLIP partiel autorise quant à lui la survenue potentielle d’inférences lexicales, dont la contribution à l’identification d’un mot est dépendante du nombre de mots voisins activés par chaque CLIP dérivé de l’input visuel. En effet, plus un mot va entrer en compétition avec un nombre élevé de voisins et plus son identification va devenir incertaine. En accord avec les améliorations apportées par Benboutayab (2004) au fonctionnement du modèle CLIP original (Kajii et Osaka, 2000), les simulations tiennent également compte du fait que la position des lettres identifiées n’est vraisemblablement pas encodée de manière absolue dans les CLIPs. Il est donc admis que les inférences lexicales puissent concerner des mots de taille légèrement différente de celle des stimuli cibles (Benboutayab, 2004). Le modèle est ainsi autorisé à considérer les mots de 4 et 6 lettres comme voisins potentiels des CLIPs dérivés des inputs de 5 lettres présentés. Cette manipulation permet par exemple que le candidat lexical CHAMBRE soit activé par le CLIP partiel CHA**E encodé à partir du mot CHAISE (exemple emprunté à Benboutayab, 2004).
La contribution des facteurs lexicaux à l’identification globale du mot est enfin déterminée par la probabilité d’occurrence de chaque CLIP construit, laquelle dépend directement de la lisibilité des lettres constitutives de la séquence suivant la position du regard dans le mot, calculée d’après le modèle de Nazir et al (1991). Les nombreux voisins éventuellement activés par un CLIP dont la probabilité d’occurrence est faible influenceront de manière négligeable la probabilité d’identification du mot, au contraire des quelques voisins associés à un CLIP de probabilité d’occurrence plus élevée. Signalons également que, par principe, la contribution des CLIPs contenant moins de la moitié des lettres du mot original est considérée comme négligeable pour le processus d’identification (Benboutayab, 2004). Ainsi, si l’on considère à nouveau l’exemple présenté dans la Figure 34, ce postulat implique que seuls les 15 CLIPs intégrant entre 3 et la totalité des lettres constitutives du mot TABLE soient intégrés dans le calcul de la probabilité d’identification de ce mot.
La probabilité d’identifier un mot P(W) suivant les principes du modèle CLIP (Kajii & Osaka, 2000 ; Benboutayab, 2004) est ainsi estimée par l’équation :
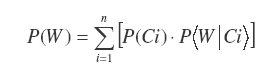
où P(Ci) représente la probabilité d’occurrence du CLIP Ci (parmi les n CLIPs possibles un seul CLIP peut avoir lieu à la fois), P(W|Ci) est la probabilité conditionnelle 22 de prédire le mot complet à partir du CLIP Ci.
La probabilité d’occurrence d’un CLIP correspond à la probabilité d’identifier certaineslettres contenues dans la séquence et de ne pas identifier leslettres restantes. Si l’on appelle Di l’ensemble des indices des lettres reconnues, cette probabilité peut s’écrire :

où L représente l’une des lettres constitutives d’un mot.
Si l’on se réfère aux probabilités de reconnaissance des lettres calculées plus haut (d’après Nazir et al., 1991, voir Tableau 30), la probabilité d’occurrence du CLIP T*B*E (choisi au hasard parmi les 32 CLIPS de la Figure 34) lorsque TABLE est fixé sur la première lettre s’élèvera donc à :

Enfin, la probabilité conditionnelle de prédire le mot complet à partir du CLIP Ci dépend du nombre de mots partageant les mêmes lettres que le CLIP de telle manière que l’augmentation du nombre de ces candidats lexicaux complexifie l’identification du mot cible. Cette probabilité est estimée suivant l’équation :
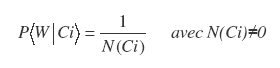
où N(Ci) représente le nombre de mots partageant les mêmes lettres que le CLIP Ci. Attendu que tout CLIP dérivé d’un mot connu est au minimum censé activer la représentation du mot cible en mémoire, le terme N(Ci) ne peut se voir attribuer de valeur nulle. Dans les conditions particulières où le mot présenté ne possède aucun voisin parmi les connaissances du participant, N(Ci) prend la valeur de 1, de manière à rendre compte que la probabilité d’identifier un mot même perçu de manière incomplète se trouve à son maximum lorsque ce mot ne peut s’apparier qu’à lui-même en mémoire.
En résumé, le modèle CLIP laisse dépendre le succès de l’identification des mots écrits de l’intervention conjointe de stratégies efficaces d’extraction « on-line » des informations visuelles portées par le percept considéré et de procédures de réinvestissement des connaissances lexicales préalablement encodées. Plus précisément, lorsque les conditions de présentation d’un stimulus ne permettent pas l’identification précise de ses lettres constitutives, les chances d’identifier le mot sont déterminées par le nombre de mots de structure orthographique compatible avec l’item cible connus du participant. La valeur prédictive du modèle CLIP a précédemment été établie avec succès auprès des participants adultes dans le cadre des travaux menés par Benboutayab (2004). Ce point est illustré par les graphiques de la Figure 35 qui démontrent la remarquable corrélation alors obtenue entre les courbes d’effet de position du regard théoriques et empiriques, dans le contexte d’une tâche d’identification (graphique de gauche) comme de décision lexicale (graphique de droite).
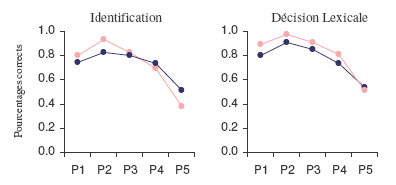
Les données reportées concernent la tâche d’identification (graphique de gauche) et le paradigme de décision lexicale (graphique de droite). Dans les deux cas, une remarquable corrélation a été obtenue entre les courbes empiriques et théoriques, tant sur leur forme générale que sur leur hauteur.
En autorisant une intervention sélective au niveau de son paramètre lexical, le modèle CLIP apparaît particulièrement adapté à l’exploration objective du degré d’implication des caractéristiques du stock lexical intégré par les enfants au cours des premières étapes de leur apprentissage de la lecture sur l’installation durable de l’influence de l’AdAortho. Possibilité est en effet offerte ici d’imposer au modèle de travailler en référence avec vocabulaire défini suivant des critères pleinement maîtrisés et de mesurer avec exactitude l’adéquation des prédictions établies d’après cette base avec les observations empiriques correspondantes.
Le modèle CLIP sera donc exploité dans ce sens suite à la description empirique de l’influence de l’AdAortho sur les capacités des enfants à reconnaître des mots brièvement présentés en différents endroits de la rétine, au moyen de la technique de la position variable du regard précédemment utilisée par Aghababian et Nazir (2000).