2.4.2.2. Présentation des résultats
Une analyse fine et exhaustive de l’ensemble des résultats du sondage se trouve présentée en annexe (annexe B), suivant les conseils de Tremblay (1991 : 298) 314 . Pour chaque question, le lecteur y trouvera :
- les résultats de l’analyse univariée, comprenant :
-
- le relevé des réponses manquantes, encore appelées valeurs manquantes (qui correspondent au cas où les personnes n’ont pas répondu à la question alors qu’ils étaient censés y répondre) ;
- le relevé des réponses effectives, comportant d’une part les fréquences brutes, présentées sous forme de tableaux de distribution de fréquences, et d’autre part les fréquences relatives présentées pour la plupart sous forme de graphiques (histogrammes ou diagrammes circulaires).
Les données sont accompagnées d’un bref commentaire résumant les faits les plus frappants, lorsque cela s’avère nécessaire.
- les résultats de l’analyse bivariée. L’analyse bivariée, dans notre cas, correspond essentiellement au croisement des réponses de chaque question avec les variables suivantes : catégorie et sous-catégorie d’usager. On trouve donc en annexe :
Pour les croisements avec les catégories, comme ceux avec les sous-catégories, nous avons de plus effectué le test du chi-deux ; nous n’en livrons que le résultat, sous la forme d’un tableau qui se présente la plupart du temps comme ceci :
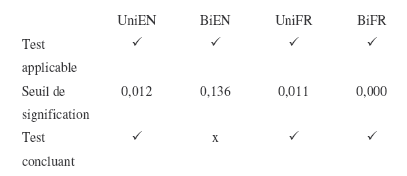
Les divers éléments de ce tableau méritent quelques commentaires :
- Appellations utilisées à la première ligne
Nous avons précisé que nous avions élaboré deux sondages, l’un en français, l’autre en anglais. En réalité, pour les buts de l’analyse, nous les avons subdivisés selon les sections « dictionnaires unilingues / dictionnaires bilingues » et considérons qu’il y en quatre, à savoir : uniEN, uniFR, biEN, biFR 319 .
- Test applicable
A ce niveau du test du chi-deux, nous vérifions si les trois conditions d’application énoncées sont remplies () ou non (x). Il se trouve que, pour l’analyse de la répartition des réponses par sous-catégories, la valeur de la fréquence théorique nous a posé problème pour l’ensemble des questions à cause du très petit nombre d’étudiants, et tout particulièrement à cause du très faible nombre d’étudiants de sciences et techniques ayant répondu au sondage anglais (uniEN : 2, biEN : 1) 320 . Lorsque les conditions (2) et (3) posent problème, une des solutions possibles pour ne pas complètement rejeter le test est d’effectuer certains regroupements (Colin, Lavoie et al. (1992 : 276), Foster (2001 : 156)). Dans notre cas, le seul 321 regroupement intéressant à faire était de mettre ensemble tous les sondages unilingues d’une part, et tous les sondages bilingues d’autre part.
- Seuil de signification / test concluant
Nous ne donnons pas la valeur du chi-deux, qui n’est pas en elle-même significative. Nous nous limitons à donner celle du seuil de signification fournie par SPSS, et les conséquences qui en découlent : test concluant () ou non (x).
Pour terminer sur le sujet de l’analyse bivariée, précisons qu’à l’occasion, nous avons aussi effectué des croisements entre diverses questions de la partie B (et pratiqué bien évidemment le test du chi-deux). Le résultat de ces croisements, présenté sous la même forme que les précédents, se trouve à la fin des résultats de chaque question.
Dans ce chapitre, nous avons exposé en détail la méthodologie utilisée pour la réalisation et la diffusion de notre enquête (conception de l’enquête avec élaboration de la problématique, rédaction de l’enquête proprement dite, collecte et traitement des données) ainsi que les divers écueils auxquels nous avons dû faire face. Dans le chapitre à venir, nous allons décrire les principaux résultats et formuler nos conclusions sous la forme d’une synthèse qui s’appuie sur l’ensemble des données fournies dans l’annexe B 322 .