2.3.1. Classification en fonction du contexte
Pendant le processus de décodage des significations des unités lexicales, le contexte d'un exercice influence les conditions de décodage des unités lexicales puisqu'il permet une activation d'éléments sémantiques ou encore la construction d'une logique textuelle. Ainsi, le sens varie en fonction des co-occurrents présents dans la phrase et de la connaissance des éléments extérieurs au langage comme, par exemple, l'arrière plan de la communication. Nous proposons d'étudier différentes stratégies applicables par l'apprenant pour chacun des trois types d'insertion contextuelle.
Pour les exercices en contexte large, le travail avec les exercices est précédé d'un travail préalable où l'apprenant construit des schèmes conceptuels en fonction des événements et actions rencontrés pendant la présentation. Il peut activer des connaissances du monde par rapport au thème abordé et il rencontre du vocabulaire lié au thème de l'exercice. Les stratégies de décodage peuvent se baser sur la macrostructure (utilisation des connaissances du monde) et sur la microstructure (inférence séquentielle) :
- Utiliser les connaissances du monde :
Les connaissances du monde de l'apprenant peuvent aider à activer des traits sémantiques pour décoder une unité lexicale inconnue. Dans l'exercice suivant (qui consiste à associer les différentes phrases aux images du film), l'apprenant voit un film où un étudiant de Cameroun décrit sa vie d'étudiant. Nous supposons inconnu le terme "Kommilitonen" :

Les apprenants, qui connaissent la vie dans une résidence universitaire, savent que les étudiants s'y rencontrent facilement. Sachant que le mot "Kontakt" est transparent pour un apprenant français, il peut comprendre "Kontakt zu anderen … finden" (prendre contact avec les autres) et peut faire l'hypothèse que "Kommilitonen" signifie "d'autres étudiants". Dans une enquête (annexe 2), nous avons demandé à sept étudiants de décoder le terme "Kommilitonen" et de noter leur raisonnement.
Seulement un étudiant (K7) a utilisé ses connaissances du monde par rapport à la vie des étudiants étrangers et leur désir de rencontrer d'autres étudiants de leur pays. Ainsi il a fait l'hypothèse que "Kommilitonen" signifie "compatriotes". Ceci ne correspond pas à la signification exacte de "Kommilitonen", même si les "compatriotes" dans les résidences universitaires sont probablement aussi des étudiants. Cinq étudiants (K1, K3, K4, K5, K6) ont fait l'hypothèse que "Kommilitonen" signifie "colocataire" et ils se sont basés pour cela surtout sur les images et le texte. Bien que les "colocataires" dans les résidences universitaires soient certainement aussi des étudiants, cette hypothèse n'est pas correcte non plus. Enfin, un seul étudiant (K2) n'a trouvé aucune signification.
Les résultats de cette enquête permettent de tirer des conclusions par rapport au choix des stratégies de décodage et concernant la difficulté à décoder une unité lexicale à partir des connaissances du monde. Les étudiants semblent peu se servir de leurs connaissances du monde pour décoder une unité lexicale. Cela peut être expliqué par le fait que cette stratégie nécessite une prise de distance par rapport à la microstructure du texte. En outre, les connaissances du monde sont personnelles et une association avec une expérience personnelle peut ne pas correspondre aux traits sémantiques d'une unité lexicale. Ainsi, le fait de chercher des compatriotes à l'étranger pourrait aussi être un comportement typiquement français qui ne correspond pas forcément au comportement de tous les étudiants 12 . La stratégie d'utilisation des connaissances du monde pour le décodage d'une unité lexicale doit donc être complétée par d'autres stratégies de décodage.
- Utiliser une inférence séquentielle :
Lorsque l'utilisateur rencontre des unités lexicales inconnues dans les phrases présentes dans les exercices d’association, il peut recourir à une stratégie d'inférence séquentielle. Il infère dans ce cas le sens d'une unité lexicale à partir d'une séquence d'un film en combinant les différentes informations reçues. Dans un exercice par rapport à la fête de la bière à Munich, le cédérom "Einblicke" demande à l'apprenant de relier différentes phrases d'un film vidéo (visionné préalablement) à différentes images du film. Alors que les images sont présentées dans l'ordre du film, les phrases sont disposées en désordre :

| Phrases à associer aux images | (1) Die Vorbereitungen zum größten Volksfest in Deutschland, dem Münchner Oktoberfest, beginnen. | (2) Der Oberbürgermeister von München macht das erste Fass Bier auf. | (3) Ein Höhepunkt des Festes ist der traditionelle Umzug. Zwei Stunden ziehen Trachtengruppen durch die Straßen von München. | (4) Mit diesen Kutschen wurden früher Bierfässer transportiert |
L'apprenant va lire les phrases et reconstruire mentalement la présentation de la fête par le narrateur du film. Il essaie de reconstruire la logique séquentielle. Lorsqu'il ne connaît pas le terme "Vorbereitungen" dans la phrase (1), une reconnaissance des unités lexicales dans la même phrase peut aider pour établir des hypothèses. A supposer que l'apprenant connaisse l'unité lexicale "beginnen" (commencer), il peut faire l'hypothèse que cette phrase doit se trouver en début de la séquence du film. Ensuite, il peut se souvenir du début du film où il a vu des préparatifs de la fête et faire l'hypothèse que "Vorbereitungen" signifie "préparatifs".
Dans une enquête (annexe 2) auprès de trois étudiants, nous avons constaté qu'ils ont tous trouvé la signification "préparatifs" en procédant de la manière suivante : "Je comprends le reste de la phrase et avec le contexte je devine la signification de ce terme" (V2), "Les images qui suivent permettent de comprendre que la fête, organisée précisément et avec un rituel précis, nécessite d'être préparée à l'avance" (V3) et "Je décompose le mot et je l'associe à l'image en m'aidant des mots connus dans la phrase" (V5).
Ces indications montrent que les étudiants se basent effectivement sur les unités lexicales connues dans la phrase (1), qu'ils transfèrent des informations communiquées par les images et qu'ils essaient de construire une logique séquentielle et contextuelle. Par contre, l'inférence séquentielle n'a pas été utilisée par l'ensemble des étudiants, ce qui nous permet de conclure qu'il peut y avoir différentes manières pour arriver à la bonne réponse et que les étudiants n'utilisent pas toutes les stratégies possibles.
Les exercices en contexte réduit sont présentés en dehors d'une situation ou d'un discours. Ils empêchent l'utilisateur de construire une logique contextuelle ou d'activer des connaissances du monde. Les unités lexicales sont cependant insérées dans des phrases dont les constituants peuvent déterminer la signification de l'unité lexicale à décoder. L'apprenant doit se baser sur la microstructure de l'exercice.
- Utiliser un rapport entre deux unités lexicales et la référence de l'image :
Le rapport entre deux unités lexicales identifiées par l'utilisateur comme une paire peut permettre un transfert d'informations sémantiques. Cela est le cas pour l'exemple proposé par le cédérom "Reflex' Deutsch". L'apprenant doit choisir l'image qui correspond à une phrase en écrivant le numéro de la phrase à côté de l'image. Pour accomplir l'exercice, il doit comprendre les unités lexicales dans les phrases à associer, mais certaines unités lexicales peuvent être inconnues :
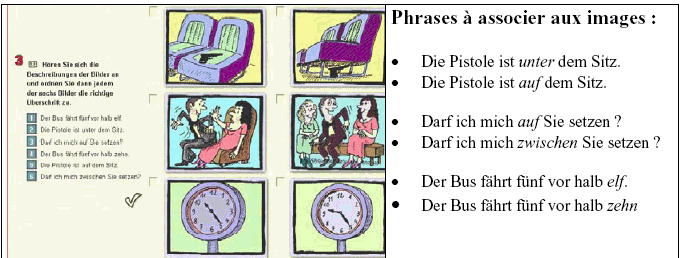
Cet exercice est composé de paires de phrases comme "Die Pistole ist auf dem Sitz - Die Pistole ist unter dem Sitz". Les unités lexicales qui diffèrent dans les deux phrases présentent des rapports d'antonymie ("auf-unter") ou de succession ("zehn-elf") illustrés par les images. Lorsque l'apprenant connaît au moins une des unités lexicales visées dans une paire de phrase, il peut déduire la deuxième à partir de la référence avec l'image.
Ecouter la forme phonétique :
Souvent, il est possible d'écouter un fichier sonore correspondant aux phrases de l'exercice. L'utilisateur y accède en cliquant sur l'icône du magnétophone. Un narrateur prononce ainsi les différentes phrases de l'exercice :

Pour la compréhension des différentes phrases, Roher (1990) mentionne que la disponibilité des informations sonores ("akustische Erinnerungsbilder") est une condition pour la compréhension écrite. Pour ce postulat, il se base sur les travaux de N. Geschwind (1980) :
‘"Offenbar hängt das Verständnis geschriebener Wörter davon ab, daß die lautliche Form im sensorischen Sprachzentrum wachgerufen werden kann." (dans : Roher (1990) ’La possibilité d'écouter la prononciation des unités lexicales dans les différentes phrases, ne permet pas directement de décoder une unité lexicale en particulier, mais nous pouvons supposer une facilitation de la compréhension écrite des unités lexicales.
Les exercices hors contexte manquent de rapport avec le déroulement d'une histoire et de liens avec les co-occurrents d'une phrase. L'apprenant est limité à l'unité lexicale même, et il ne peut qu'agir avec la stratégie suivante :
- Décomposer les unités lexicales :
Lorsque les unités lexicales à décoder sont présentées d'une manière isolée, elles empêchent l'inférence à l'intérieur d'une phrase. Il peut cependant être possible de décomposer les termes et de reconnaître des parties décomposées et de faire une référence entre une partie décomposée et l'image, comme dans l'exemple de "Abschleppwagen" :

L'unité lexicale "Abschleppwagen" peut être décomposée en "Abschlepp" et "wagen". Le terme "Wagen" peut être supposé connu de l'apprenant et il sait alors qu'un "Wagen" a quatre roues. Puisque nous voyons sur l'image un véhicule à quatre roues, il est possible de faire l'hypothèse que "Abschleppwagen" correspond à l'image et d'utiliser ensuite l'image comme référent vers la signification "dépanneuse". Alors que cette stratégie est valable pour les unités lexicales décomposables et monosémiques, elle est insuffisante pour toutes les unités lexicales qui sont influencées par le contexte de la phrase, le discours et l'utilisation culturelle par les locuteurs.