La constitution des ontologies
L’objectif est, dans un premier temps, de représenter graphiquement les concepts que décrivent les éléments de connaissance par projet sous la forme de réseaux sémantiques. Ainsi, les relations sémantiques permettront aux utilisateurs de mieux comprendre le contexte des fiches de connaissance.
Dans un second temps, il sera utile de proposer des outils de recherche basés sur les liens entre ces concepts.
Par la suite, nous facilitons la mise en œuvre de la couche sémantique en utilisant le logiciel Protégé 2000. En effet, afin de développer ces ontologies, il convenait d’utiliser un logiciel d’édition d’ontologie capable de supporter le langage RDF et de générer des fichiers XML en export. Nous voulions bénéficier de l’ergonomie et des fonctionnalités additionnelles relatives à la gestion des ontologies que proposent certains éditeurs d’ontologie. Lambrix et al (2003) ont fait une étude comparative des éditeurs d’ontologie qui met en avant le logiciel Protégé 2000 concernant le coût du produit, son ergonomie, sa portabilité et la gestion des mises à jour et des regroupements d’ontologies.
Protégé 2000 est un éditeur qui permet de construire une ontologie pour un domaine donné ou une description précise, de définir des formulaires d’entrée de données, et d’acquérir des données à l’aide de ces formulaires sous forme d’instances. Le modèle de connaissance de Protégé 2000 est hiérarchique, les ontologies consistent en une hiérarchie de classe qui ont des attributs ayant eux-mêmes des propriétés. Ils correspondent donc aux liens que nous avons définis pour relier les connaissances car ils sont basés sur l’approche objet. L’édition des liens et des éléments de connaissance se fait par l’intermédiaire de l’interface graphique, sans avoir à formaliser ce que l’on a exprimé. Cette forme graphique est très ergonomique car elle autorise une liberté de conception importante à travers la personnalisation de son interface et des formulaires permettant de construire l’ontologie.
Protégé est également une librairie Java qui peut être étendue pour créer de véritables applications à base de connaissances en utilisant un moteur d’inférence pour raisonner et déduire de nouveaux faits par application de règles aux instances de l’ontologie et à l’ontologie elle même (méta-raisonnement). Ainsi, plus de 90 « plug-ins » sont disponibles permettant d’apporter de nouvelles fonctionnalités au logiciel que se soit pour l’export d’ontologie, la visualisation des éléments sémantiques obtenue ou le traitement des ontologies existantes.
Dans le contexte du web sémantique des « plugins » pour les langages RDF, DAML+OIL et OWL ont été développés pour Protégé. Ces « plugins » permettent d’utiliser Protégé comme éditeur d’ontologie pour ces différents langages, de créer des instances et de les sauver dans les formats respectifs.
Il est également possible de raisonner sur les ontologies en utilisant un moteur d’inférence général tel que JESS 8 , ou des outils d’inférence spécifiques au web sémantique basés sur des logiques de description tels que RACER 9 .
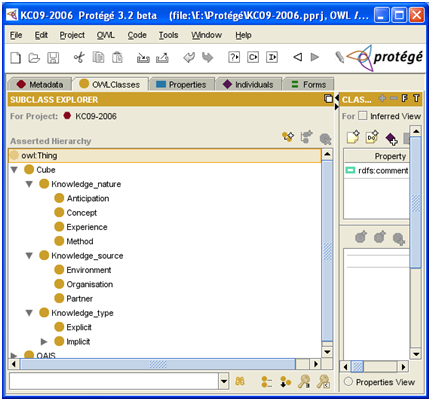
On retrouve dans cette première ontologie, les éléments du cube qui permettent d’indexer les fiches de connaissance.
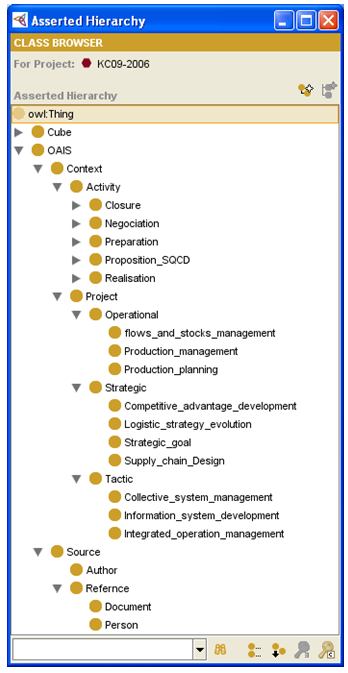
Cette deuxième ontologie repend les éléments qui nous seront utiles pour décrire le contexte. Elle reprend l’ensemble des activités du projet que l’on retrouve dans les diagrammes d’activité des partenaires, la typologie des projets inspirée de Ganeshan et al [Ganeshan et al , 1998], ainsi que les éléments permettant de décrire les sources de la fiche de connaissance.
Le fichier OWL contenant les ontologies est généré par la fonction export XML du logiciel et doit être reprise par le système pour indexer les fiches de connaissance. OWL, comme RDF(S), est une extension d'XML disposant d'une syntaxe à base de balise.
De même, le réseau sémantique étant modélisé avec UML, nous utilisons les travaux de Gasevic et al [Gasevic et al, 2004] pour la transformation du fichier XMI (XML Metadata Interchange (XMI) est un standard d'échange de données UML basé sur XML.) obtenu à partir du model UML afin de le convertir en fichier OWL. Le fichier XMI est converti en OWL en utilisant une feuille de transformation XML (XSLT) qui, au moyen de règles prédéfinies, fait correspondre les objets XMI aux primitives OWL.
Chaque fiche de connaissance ayant une URI spécifique, l’annotation se fait en reliant cette URI aux concepts de l’ontologie au moyen d’interface que nous présenterons à la fin de ce chapitre.