2.2.3.2. Une méthode d’imputation des revenus dans l’EMD de Lyon
Pour affecter à chaque ménage un revenu par UC, on part de l’hypothèse qu’il existe une répartition théorique des revenus à l’intérieur de chaque tranche de revenu. On affecte alors à chaque ménage une valeur aléatoire de revenu à l’intérieur de la tranche considérée.
Afin de déterminer ces valeurs, on procède de la manière suivante. Pour chaque tranche de revenu on estime le pourcentage de ménages se trouvant théoriquement en dessous et au-dessus du centre de la classe de revenu. Ce pourcentage est déterminé en fonction des pentes des segments de droite qui composent la courbe de la distribution cumulée de la population des ménages en fonction de leur revenu (Graphique 4)
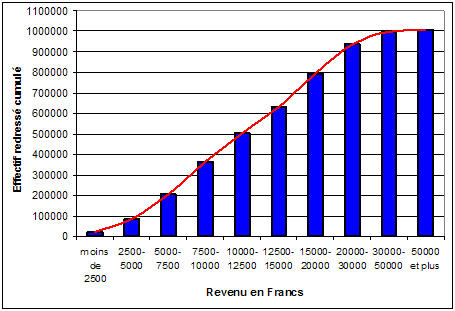
Source : EMD de Lyon 1994-1995
| Tranches de revenu | Proportion de ménages ayant un revenu inférieur au centre de la classe |
Proportion de ménages ayant un revenu supérieur au centre de la classe |
| moins de 2500 F. de 2500 à 5000 F. de 5000 à 7500 F. de 7500 à 10000 F. de 10000 à 12500 F. de 12500 à 15000 F. de 15000 à 20000 F. de 20000 à 30000 F. de 30000 à 50000 F. 50000 F. et plus |
Nd 51 46 57 54 55 72 83 93 Nd |
Nd 49 54 43 46 45 28 17 7 Nd |
Source : EMD de Lyon 1994-1995
Nd : non disponible ; il faut en effet disposer de la tranche de revenu inférieure et supérieure pour calculer la répartition théorique de la population à l’intérieur d’une classe de revenu ; pour ces tranches de revenu on affecte donc des valeurs arbitraires.
Sur la base de ces estimations, on affecte alors à chaque ménage un revenu correspondant à une valeur prise à l’intérieur de la classe de sorte que, in fine, on retrouve la distribution théorique souhaitée de part et d’autre du centre de classe. Pour chaque tranche de revenu, ces valeurs sont présentées en annexes (Annexe 3).
L’attribution d’une valeur de revenu précise, en lieu et place de la tranche de revenu déclarée est faite de manière ordonnée à partir de différentes simulations. Cette méthode d’affectation a été reproduite cinq fois : pour la première itération on part du premier ménage, pour la seconde du deuxième, et ainsi de suite jusqu’à la cinquième pour laquelle on part du cinquième ménage. On obtient ainsi cinq simulations 1 d’affectation aléatoire de revenus, pour chacune on détermine alors le revenu par UC, que l’on classe ensuite en déciles puis en quintiles (Tableau 8).
| EMD de Lyon 1994-1995 | ENT 1993-1994 | ||
| Revenu du ménage en déciles par uc |
Revenu moyen en F | Revenu du ménage en déciles par uc |
Revenu moyen en F |
| D1 D2 D3 D4 D5 D6 D7 D8 D9 D10 |
2275 3733 4765 5664 6675 7619 8694 10006 12042 18708 |
D1 D2 D3 D4 D5 D6 D7 D8 D9 D10 |
2048 3298 4134 4912 5704 6520 7529 8889 10942 18304 |
| EMD de Lyon 1994-1995 | ENT 1993-1994 | ||
| Revenu du ménage en quintiles par uc |
Revenu moyen en F | Revenu du ménage en quintiles par uc |
Revenu moyen en F |
| Q1 Q2 Q3 Q4 Q5 |
3019 5207 7148 9351 15443 |
Q1 Q2 Q3 Q4 Q5 |
2673 4515 6110 8211 14586 |
Source : EMD de Lyon 1994-1995 et ENT 1993-1994
Cette affectation aléatoire de valeurs discrètes de revenu pour chaque ménage permet de sortir des pièges et des effets de seuil liés aux classes de revenu. Si l’on reprend l’exemple précédent, on retrouve bien une relation croissante du niveau de motorisation des ménages tant en fonction de leur revenu qu’en fonction de leur revenu par UC. De même on dispose d’une bien meilleure répartition des célibataires vivant seuls dans les différents déciles de revenu (Tableau 9).
| Revenu en déciles | Revenu en déciles par UC | ||
| Revenu du ménage en déciles |
Niveau de motorisation | Revenu du ménage par UC en déciles | Niveau de motorisation |
| D1 D2 D3 D4 D5 D6 D7 D8 D9 D10 |
0,35 0,52 0,63 0,91 1,04 1,19 1,44 1,60 1,74 1,95 |
D1 D2 D3 D4 D5 D6 D7 D8 D9 D10 |
0,59 0,81 0,81 1,07 1,18 1,21 1,33 1,34 1,48 1,69 |
| Moyenne | 1,15 | Moyenne | 1,15 |
Source : EMD de Lyon 1994-95
Si cette option constitue un moindre mal, elle ne saurait pour autant être entièrement satisfaisante, car à un certain niveau de découpage de la population en sous-groupes, les biais d’affectation aléatoire ne sont plus compensés par les effets d’agrégation. Il serait donc souhaitable de modifier la procédure d’identification des revenus des ménages dans le cadre des prochaines enquêtes ménages d’agglomération.