Structures dominantes et règles d’implication
L’observation des types syllabiques permet de faire émerger les deux types dominants : CV et CVC qui représentent plus de 50% des syllabes avec CV comme type syllabique le plus fréquent. Cette distribution dans nos dialectes n’est pas exceptionnelle puisque c’est le cas pour la majorité des langues. Ces deux types représentent un total de 56%, 66%, et 77% respectivement dans le dialecte marocain, tunisien et libanais (les autres structures se partageant les fréquences restantes). La fréquence d’occurrences de ces deux types syllabiques est variable d’un dialecte à l’autre et les structures CV et CVC augmentant graduellement d’Ouest en Est (Figure 39).
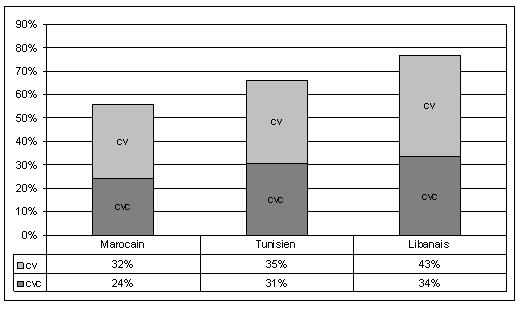
Les résultats sur la Figure 39 peuvent être comparés à ceux obtenus lors d’études antérieures sur les structures syllabiques les plus recrutées dans les langues du monde. Ces études ont montré d’une part l’émergence de deux types syllabiques dominants : CV et CVC, et d’autre part la haute fréquence de la structure CV qui constitue le type le plus recruté. La prédominance de la structure CV est également compatible avec certaines hypothèses qui considèrent CV comme structure universelle (MacNeilage, 1998).
La comparaison des langues du monde (Clemens et Keyser, 1983 ; Blevins, 1995-96) a montré depuis lontemps que les syllabes du monde étaient toutes des déclinaisons, par ajout ou soustraction d’éléments C pré ou post-vocaliques, d’une même syllabe de base : la syllabe CV. Ainsi, toute langue possède au moins la syllabe de type CV (Bloomfield, 1933 ; Jakobson et Hall, 1956 ; Maddieson, 1984, 1985).
Sur un extrait de 16 langues de la base de données ULSID, Rousset (2004) a constaté que les deux structures CV et CVC totalisent respectivement 53 % et 31 % des syllabes rencontrées dans ULSID, l’une dominant l’autre dans les langues. Elle a remarqué que 11 langues sur 16 favorisent le type ouvert CV, alors que les cinq autres (le wa, le thaï, le nya khur, le sora et le suédois) favorisent la structure fermée CVC. L’auteur remarque aussi que le type de structure CVC est favorisé dans 5 des 6 langues à tons attestées dans le corpus.
Vallée et Rousset (2004) confirment que les deux structures, CV et CVC constituent un patron de base dominant pour les langues qui, de manière générale, favorisent les structures syllabiques ouvertes si CV est dominant (CCV, CCCV… ) et, à l’inverse, les structures syllabiques fermées si CVC prédomine (CCVC, CVCC, CCVCC… ). Leurs observations confirment les tendances mises en évidence par les études typologiques antérieures.
Outre les travaux classiques en linguistique (e.g. Greenberg 1975), l’une des études récentes à établir des règles implicationnelles des structures syllabiques est celle de Blevins (1995). En se basant sur un échantillon de 11 langues, l’auteur a remarqué que la présence dans une langue d’une structure syllabique complexe, ouverte ou fermée, entraîne la présence, dans cette langue, de la structure moins complexe (la complexité étant estimée en fonction du nombre de segments dans l’attaque ou la coda). Ainsi, elle formule des lois implicationnelles régissant l’apparition des différents types de syllabes : ‘ « First, all languages have CV syllables. ’ ‘ Second, all languages exhibit the following property: if clusters of n Cs are possible syllable-initially, then clusters of n-1 Cs are also possible syllable-initially, and if clusters of n Cs are possible syllable - finally, then clusters of n-1 Cs are also possible finally. In addition, if a language does not allow syllables consisting solely of V, then it does not allow any V-initial syllables. » ’!. (Blevins, 1995-1996, p.217).
Ces règles ont été vérifiées par plusieurs linguistes comme Bannet (1998) sur un inventaire syllabique en suédois et Molinu (1999) sur un parler Sarde de l’Italie du sud. Les deux auteurs ont confirmé les règles implicationnelles proposées par Blevins (1995-1996). Nous retenons également l’étude de Rousset (2004) qui a vérifié à son tour ces règles sur l’inventaire syllabique dans un échantillon de 13 langues de l’ULSID. L’auteur a constaté que les implications sont liées à la fréquence, en remarquant que plus la complexité de l’attaque ou de la coda augmente, plus la fréquence de la structure diminue, elle présente donc les implications qu’elle a observé dans l’ordre suivant :
CCCV <<< CCV << CV
CCCVC <<< CCVC << CVC
CVCCCC <<< CVCCC << CVCC < CVC
VCCC <<< VCC << VC < V
CCVCC << (CCVC et CVCC)
CC << C
(avec < pour inférieur, << pour bien inférieur et <<< pour très largement inférieur).
Ces observations confirment les implications précédentes et ont permis à l’auteur de formuler 5 règles implicationnelles 59 .
Si nous examinons nos données à la lumière des implications proposées ci-dessus, nous constatons que dans l’ensemble des parlers nous pouvons observer que la présence de la structure à attaque complexe implique les structures avec attaque de n-i consonnes (i=1 à n-1) :
CCCV <<CCV <CV
CCCVC <<CCVC <<CVC
CVCC<<CVC
VC<<V

Nous avons regroupé les types de structures observées en fonction des deux types syllabiques prédominants : CV ou CVC (Figure 40). Nous pouvons constater que bien que la structure CV soit dominante dans les 3 dialectes, il n’y a pas d’écart important entre les proportions de (Cn)V et de (Cn)V(Cm).. Ainsi nos données ne confirment pas l’hypothèse selon laquelle une langue aura plus de syllabes ouvertes ou à l’inverse fermées, selon la dominance de CV ou de CVC, en particulier pour le tunisien dont les types (Cn)V(Cm) sont plus fréquent que (Cn)V.