4.3.1.3 Modèle et méthode économétriques
Les fonctions de coût translog sont relativement nombreuses à avoir été estimées dans les transports urbains (Tableau 53), depuis les travaux très largement cités de Viton (1981). Progressivement, les modèles et les méthodes économétriques mises en œuvre se sont afinées et diversifiées. D’une part les spécifications estimées sont de moins en moins restrictives : linéaire, Cobb-Douglas puis translog. D’autre part, les données utilisables sont de plus en plus nombreuses, ce qui permet de ne plus se restreindre à un réseau particulier en série temporelle ou à une étude ponctuelle en coupe. Les standards s’orientent assez nettement vers des estimations de fonctions translog sur données de panel (Thiry & Lawarree 1987, Kumbhakar & Bhattacharyya 1996, Matas & Raymond 1998, Karlaftis McCarthy & Sinha 1999a, Filippini & Prioni 2003).
Les modèles sur séries temporelles réduisent l’étude à un réseau particulier, agrègent la perspective jusqu’au niveau macroéconomique. Dans les transports urbains, les séries temporelles souffrent généralement de peu de variance et sont très sensibles à des déterminants locaux. Les estimations sur la base de séries temporelles ont été historiquement surtout utilisées dans les années 1980, avec des données macroéconomiques (Berechman 1983, De borger 1984) ou locales (Berechman & Guiliano 1984, Androkopoulos & al 1992) plus facilement disponibles. Récemment, même si la prise en compte de la dimension dynamique du modèle augmente sensiblement la pertinence de ce type d’estimation (Karlaftis, McCarthy & Sinha 1999b), les estimations sur séries temporelles sont devenues rares.
Les estimations en cross-section donnent indéniablement une vision plus intéressante de la structure de production du secteur. L’étude conjointe de firmes dont les tailles sont très différentes est beaucoup mieux à même de mettre en évidence les effets d’échelle, comme nous le verrons dans la sous-section 4.3.2. En contrepartie, les estimations en données croisées supposent que les firmes ont accès à la même technologie de production et le même environnement, ce qui peut être discuté ou testé par certaines variables de contrôle.
L’hétérogénéité des services (distinction des modes, de la nature plus ou moins urbaine des voies empruntées…) et l’hétérogénéité des environnements ne sont pas toujours identifiés. Toutefois, on observe certains efforts de recentrage des échantillons pour limiter l’hétérogénéité non pertinente 348 et de nombreuses tentatives fructueuses d’intégration de variables de contrôle :
- Vitesse commerciale moyenne des réseaux 349 : Viton 1992, Levaggi 1994, De Rus & Nombela 1997, Gagnepain 1998, Fraquelli Piacenza & Abrate 2004, Piacenza 2005
- Taux de remplissage des véhicules lorsque l’output est orienté demande (passagers ou passagers-kilomètres) : Levaggi 1994, Kumbhakar & Battacharyya 1996, Jha & Singht 2001
- Nombre d’arrêts : Filippini, Maggi & Prioni 1992, Filippini & Prioni 2003
- Contraintes urbaines (densité de population, centralité…) : Levaggi 1994, Dalen & Gomez-Lobo 2003
- Caractéristiques institutionnelles (propriété, contrat) : Kumbhakar & Battacharyya 1996, De Rus & Nombela 1997, Gagnepain 1998, Dalen & Gomez-Lobo 2003, Filippini & Prioni 2003, Piacenza 2005
- Ratio pointe/base : Button & O’Donnell 1985, Viton 1992, Karlaftis McCarthy & Sinha 1999a.
Les estimations qui exploitent en tant que telles des données de panel tendent à s’imposer du fait de leur pertinence particulière dans le cas des transports urbains. La double dimension temporelle et individuelle des données de panel permet de tenir compte de l’influence de caractéristiques non observables des réseaux sur leur comportement, dès lors que celles-ci restent stables dans le temps (Sevestre 2002). Les modèles en données de panel permettent de décomposer la variance totale de la variable de coût à expliquer C it entre une composante inter-individuelle, une composante intertemporelle, et une composante « intra-individuelle intratemporelle » (ou variance résiduelle) :
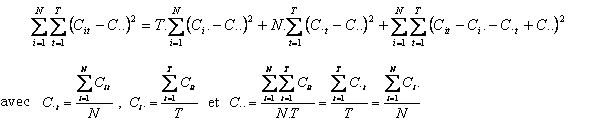
Les estimations en panel, par rapport aux estimations en coupe, offrent la possibilité d’intégrer une dimension temporelle rassemblant les évolutions technologiques affectant l’ensemble des réseaux 350 . Cette composante ne semble pas négligeable dans la plupart des estimations réalisées. Une mesure simple de l’effet du temps s’obtient par exemple avec des variables binaires 351 . La fonction de coût estimé est alors de la forme :
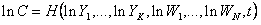
L’évolution de la productivité peut être définie comme l’augmentation de la production, pour un niveau d’input constant (PGY). Il est alternativement possible de considérer que c’est la diminution de la consommation d’inputs, pour une production constante (PGX). Caves, Christensen & Swanson (1981) établissent les formules suivantes en rappelant la dualité de la fonction de coût et de la fonction de production :
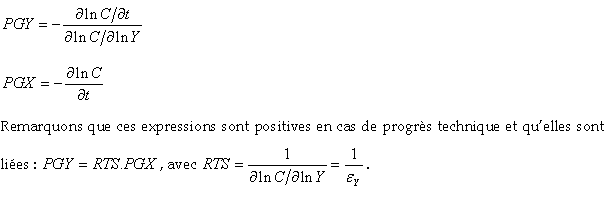
Les déplacements de la fonction de coût dans le temps sont généralement interprétés comme des phénomènes de progrès technique. Dans les TCU, les causes peuvent être multiples (Thiry & Lawarree 1987) : changement dans l’organisation de la production, évolution de la réglementation nationale (travail, sécurité…), efficacité de la gestion et de l’organisation, qualité des facteurs de production, évolution de la voirie et des conditions de circulation… Il s’agit, dans ce secteur mature, relativement souvent de pertes de productivité.
En conclusion de la sous-section 4.3.1, les estimations réalisées sur la base d’un output agrégé (véhicules-kms, places-kms ou passagers-kms) montrent que la composante panel s’est standardisée, aux cotés d’une spécification flexible comme la translog. Les possibilités offertes sont plus nombreuses, mais cela nécessite aussi d’importantes bases de données.
Précédemment, nous avons discuté et montré les limites de l’estimation d’une fonction de coût variable par l’utilisation d’une variable de capacité, ainsi que l’idée de la distinction des rendements de densité par la considération des longueurs de ligne. Les points sur lesquels nous allons maintenant nous concentrer sont ceux de la taille optimale des exploitations en fonction de l’output choisi. La sous-section suivante propose de les évaluer grâce aux données dont nous disposons sur les réseaux français.