4.3.2.2 Fonction de coût et taille optimale en véhicules-kilomètres
Pour discuter l’intérêt et les limites de l’approche en panel et choisir les méthodologies les plus pertinentes, nous proposons tout d’abord l’analyse d’un modèle simple, mais non restrictif sur les rendements d’échelle : une fonction de coût translog avec la somme des véhicules-kilomètres comme unique output. Cette estimation est réalisée sur la base du package plm 358 du logiciel R 359 version 2.4.1.
Le modèle à effets fixes (individuels et temporels) que nous estimons au point moyen 360 est le suivant :
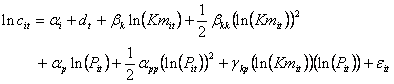
où les i et d t représentent les effets fixes individuels et temporels 361 ,
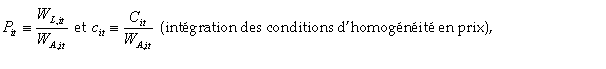
et it est un terme d’erreur non autocorrélé, d’espérance nulle et de variance finie.
Ce modèle est estimé en recourant à l’estimateur des MCO sur les différences à la moyenne. L’application du théorème de Frisch-Waugh permet de décomposer l’estimation des coefficients en deux étapes. Un modèle en différence intra-individuelle et temporelle est estimé 362 , puis les coefficients obtenus permettent d’identifier les effets individuels et temporels.
Et parallèlement à cette estimation d’un modèle à effet fixe (Within), nous détaillons dans le Tableau 56 les résultats des estimations du modèle à erreur composée 363 (Random) et du modèle ne considérant pas les effets individuels (Pooling) :

Dans le modèle à erreurs composées, les effets individuels sont struturellement aléatoires. On y suppose donc une absence totale de corrélation entre les effets individuels et les variables explicatives. Dans le modèle Pooling, est estimé un modèle en données croisées avec des dummies pour les différentes dates (within temporel).
| Within | Random | Pooling | ||||
| Coef | P(>|t|) | Coef | P(>|t|) | Coef | P(>|t|) | |
| 0 | 9,125 | *** | 9,179 | *** | ||
| k | 0,7184 | *** | 1,0595 | *** | 1,0680 | *** |
| kk | -0,0323 | 0,13 | 0,0499 | *** | 0,0149 | ** |
| p | 0,5700 | *** | 0,5467 | *** | 0,5203 | *** |
| pp | 0,1749 | *** | 0,1716 | *** | 0,0414 | 0,50 |
| kp | -0,0215 | * | -0,0223 | * | -0,0334 | ** |
| d 1996 | 0,02% | 0,97 | -0,66% | 0,25 | -0,53% | 0,72 |
| d 1997 | 0,85% | 0,12 | 0,17% | 0,78 | -0,14% | 0,92 |
| d 1998 | 1,50% | ** | 0,29% | 0,62 | -0,33% | 0,82 |
| d 1999 | 4,16% | *** | 2,29% | *** | 1,16% | 0,42 |
| d 2000 | 5,21% | *** | 2,83% | *** | 1,98% | 0,17 |
| d 2001 | 7,16% | *** | 4,57% | *** | 4,49% | ** |
| d 2002 | 8,38% | *** | 5,18% | *** | 4,89% | *** |
| scr | 1,316 | 1,778 | 11,582 | |||
| ddl | 806 | 946 | 946 | |||
| Probabilités critiques : 0 '***' , 0,001 '**', 0,01 '*' et 0,05 '.' | ||||||