2.1.4. L’intercompréhension
Pour compléter ces différentes tentatives de définition, une quatrième approche a largement été exploitée par de nombreux linguistes, et Hudson la reprend : il s’agit du critère d’intercompréhension. La définition la plus simple consiste à dire que si les locuteurs de deux variétés se comprennent mutuellement, alors les variétés concernées sont des déclinaisons de la même langue. Mais si les locuteurs ne se comprennent pas, ces variétés ne sont pas issues de la même langue. Définition trop simpliste qui fait de cet indice seul un critère non satisfaisant.
Pour expliquer cela, tout d’abord, Hudson revient sur la dénomination même des langues. Il est fréquent que ce qu’on appelle des langues, donc des codes qui portent des noms différents, soient mutuellement compréhensibles, alors que ce qu’on appelle des dialectes, donc des variétés d’une même langue, ne le soient pas du tout. Hudson prend les exemples de certaines « langues » scandinaves et de certains « dialectes » pratiqués en Chine.
‘Even popular usage does not correspond consistently to this criterion [of mutual intelligibility], since varieties which we (as laymen) call different languages may be mutually intelligible (e.g. the Scandinavian languages, excluding Finnish and Lapp) and varieties which we call instances of the same language may not (e.g. the so-called ‘dialects’ of Chinese). Popular usage tends to reflect the other definition of language, based on prestige, so that if two varieties are both standard languages, or are subordinate to different standards, they must be different languages, and conversely they must be the same language if they are both subordinate to the same standard. (Hudson, 1980 : 35)’Ce point de vue peut être complété par une remarque de Chambers & Trudgill (1980 : 4) concernant les langues scandinaves et l’intercompréhension qui existe entre elles :
‘While it is true, for example, that many Swedes can very readily understand many Norwegians, it is also clear that they often do not understand them so well as they do other Swedes. For this reason, inter-Scandinavian mutual intelligibility can be less than perfect, and allowances do have to be made: speakers may speak more slowly, and omit words and pronunciations that they suspect may cause difficulties.’Ce que mentionnent ici les auteurs est particulièrement intéressant dans le cas de l’arménien. Les critères de prestige et de taille ainsi que le fait que les deux variétés soient considérées comme étant deux standards distincts, laissent supposer qu’elles sont deux langues différentes. Ce n’est pour autant pas ce qui se passe pour l’arménien. Même si deux standards différents ont été établis pour cette langue, il est clair qu’il existe, malgré les différences linguistiques perceptibles, un degré certain d’intercompréhension entre les locuteurs.
C’est justement cette notion de degré qui est primordiale dans nos choix terminologiques. Il est trop simpliste de prétendre de façon binaire qu’il y a ou non intercompréhension entre les personnes. Il est en revanche beaucoup plus pertinent d’estimer que ce critère de l’intercompréhension est une question de degré. Il est bien entendu difficile et arbitraire d’évaluer à partir de quel point on peut considérer que deux variétés font partie d’une même langue, c’est pourquoi nous ne nous aventurerons pas dans de tels jugements.
Une des méthodes des linguistes à ce propos est de ranger les variétés linguistiques sur un continuum de dialectes, chaque paire de variétés linguistiques considérées comme proches étant intercompréhensible, mais des paires prises d’un bout à l’autre du continuum ne l’étant pas.
Selon nous, le fait le plus important à retenir est que l’intercompréhension n’est pas une relation entre des variétés linguistiques, mais entre des personnes qui usent de ces variétés. Ce sont elles qui se comprennent réciproquement ou non, et comme le précise Hudson (1980 : 36) :
‘The degree of mutual intelligibility depends not just on the amount of overlap between the items in the two varieties, but on qualities of the people concerned.’Même s’il est reconnu linguistiquement que les deux standards d’arménien comportent une certaine forme d’intercompréhension, d’une part grâce aux similitudes qui existent dans leurs systèmes et, d’autre part, par le fait que certaines de leurs différences linguistiques sont « emblématiques 79 » et donc relativement connues des utilisateurs, seuls les usages langagiers qui en seront faits réellement, une fois ces deux standards mis en contact, pourront déterminer qu’il existe différents degrés d’intercompréhension. Ceux-ci seront dépendants des locuteurs et de leurs comportements face à la variante opposée. Nous regarderons donc les indices que contient notre corpus et qui pourraient, par exemple, montrer une incompréhension due à une mauvaise connaissance des systèmes linguistiques, c’est-à-dire à des lacunes que posséderaient les locuteurs ou les interlocuteurs sur les variantes employées.
Ce critère d’intercompréhension va notamment nous permettre de savoir si les différents locuteurs arméniens font partie d’une seule et unique communauté linguistique, c’est-à-dire qu’ils partagent une même langue, ou bien de deux communautés linguistiques distinctes.Selon Labov (1976 : 258), la sociolinguistique a notamment pour but d’étudier « la structure et l’évolution du langage au sein du contexte social formé par la communauté linguistique ». Autrement dit, la sociolinguistique s’intéresse aux usages langagiers des locuteurs appartenant à une même communauté linguistique.Cette dernière s’observe soit à un niveau global, c’est-à-dire que la communauté linguistique est étudiée dans son ensemble, comme par exemple la communauté linguistique entière d’un pays par rapport à celle d’un autre pays ; soit à un niveau plus restreint, c’est-à-dire une communauté cette fois-ci réduite, choisie, ciblée, avec des spécificités, comme par exemple lors d’une analyse des interactions à l’intérieur d’un groupe de locuteurs bien identifié.
Il est clair que nous avons choisi une communauté linguistique très ciblée,c’est-à-dire un échantillon de population sélectionné en fonction d’un certain nombre de critères posés par notre objet de recherche. Nous cherchions à mettre en contact, en France, deux variantes d’arménien. Donc se trouvaient déjà exclues les personnes uniquement francophones, ou plus globalement les personnes non locutrices d’au moins une des deux variantes d’arménien. Ensuite, nous avions besoin que soient représentées les deux variantes d’arménien, et non une seule d’entre elles, il nous fallait donc des locuteurs d’arménien oriental ainsi que des locuteurs d’arménien occidental. Enfin, pour pouvoir les mettre en contact de façon naturelle et non construite et artificielle, il était nécessaire que les différents participants se connaissent un minimum, ainsi nous avons mis en scène soit des relations familiales, soit des relations amicales, soit des relations plus formelles, mais avec des personnes qui entretiennent un lien certes distendu, mais existant depuis plusieurs années.
La seule chose restant à définir est de savoir si nous considérons que nous avons deux communautés linguistiques distinctes, l’une regroupant les locuteurs d’arménien oriental et l’autre regroupant les locuteurs d’arménien occidental, ou bien si, en nous restreignant à la définition de base préalablement donnée, nous n’en établissons qu’une seule, représentée globalement par la langue arménienne. Nous préciserons notre choix une fois que les notions de langues et variantes seront clairement posées.
Pour être à même d’effectuer ces choix terminologiques, nous pouvons nous pencher sur les attitudes des interlocuteurs qui déterminent le degré d’intercompréhension qui existe entre eux. Nous pouvons ainsi nous servir d’une des deux qualités proposées et mises en avant par Hudson (1980), que l’auditeur peut posséder : la motivation. A quel point un interlocuteur B veut-il comprendre un locuteur A ? Cette motivation dépend d’un certain nombre de facteurs comme : combien B apprécie A, à quel point veut-il souligner les différences ou similitudes culturelles entre eux deux, etc. Comprendre quelqu’un d’autre requiert toujours un effort de la part de l’auditeur. Une motivation inexistante chez un auditeur entraînerait une écoute nulle du locuteur.
Hudson évoque la motivation qui est semble-t-il primordiale chez l’auditeur, et sur ce point, il rejoint Chambers & Trudgill (1980 : 4) :
‘Mutual intelligibility will also depend, it appears, on other factors such as listeners’ degree of exposure to the other language, their degree of education and, interestingly enough, their willingness to understand.’Mais il nous paraît nécessaire de souligner encore plus l’importance de la motivation chez le locuteur. En effet, il est intéressant de voir à quel point un locuteur essaye de se faire comprendre de son interlocuteur.
Plus la différence entre les variétés est grande, plus il faudra fournir des efforts de part et d’autre. Donc, si B ne peut pas comprendre A, ou si A n’arrive pas à se faire comprendre de B, cela veut tout simplement dire que la tâche était trop dure, trop importante par rapport aux motivations de A et/ou de B.
La deuxième qualité pertinente que peut posséder un protagoniste est l’expérience. Hudson se base à nouveau uniquement sur l’auditeur et propose de regarder l’expérience qu’il a de la variété qu’il écoute. Autrement dit, on s’intéresse aux connaissances que l’interlocuteur possède de la variété dans laquelle on lui parle. Nous ajoutons à cela, comme précédemment, l’expérience qu’a le locuteur pour s’exprimer dans la variété opposée. Evidemment, plus l’expérience de l’un ou de l’autre est grande et ancienne, plus ils seront aptes à comprendre et/ou parler l’autre variété.
En plus de la motivation commune avec l’auditeur, le locuteur partage également cette deuxième qualité qu’est l’expérience. Mais cette fois-ci, elle ne porte pas sur le même code. En ce qui concerne la motivation du locuteur A ou de l’auditeur B, elle naît de la même situation de communication et dépend du type de relation qu’entretiennent entre eux les deux protagonistes. Pour l’expérience sur la langue en revanche, le point de départ n’est justement pas le même : on observe l’expérience que l’auditeur B a de la langue A pour comprendre le locuteur A, vs l’expérience du locuteur A de la langue B pour essayer de parler la langue B.
Les deux acteurs ont ainsi deux qualités communes à leur actif qui prennent place dans ce que nous appelons le phénomène d’adaptation situationnelle. C’est-à-dire que selon leur motivation et selon la connaissance qu’ils auront de la variété de l’autre, ils pourront la comprendre ou même la parler. Ce principe essentiel d’adaptation émerge à partir du moment où, dans une situation de langues en contact, il y a une tentative de la part d’un des participants de modifier ou de ne plus utiliser uniquement son code originel pour communiquer avec son interlocuteur, qui possède un code originel différent.
Voici les différentes possibilités qu’ont le locuteur et l’auditeur pour s’adapter l’un à l’autre :
- L’auditeur B, en plus de sa motivation, ne possède que son expérience de la langue A pour améliorer au maximum sa compréhension auditive, ou bien des outils verbaux ou non verbaux pour apporter un feed-back à son interlocuteur et lui signifier sa mauvaise compréhension de ce que celui-ci disait.
- Le locuteur A dispose, en plus de sa motivation, de la possibilité d’aménager son discours en langue A pour mieux se faire comprendre. Il s’agit de l’utilisation du foreigner-talk, notion que nous développerons plus tard. Il peut, pour ce faire, développer une stratégie en deux points :
-
- il peut, par exemple, essayer de réduire son débit de parole pour s’assurer qu’il est bien suivi par l’auditeur B,
- il peut également éviter délibérément certains termes de vocabulaire, certaines constructions ou prononciations qu’il penserait difficile d’accès pour l’auditeur B (stratégies de la « simplification » en conversation exolingue).
- Le locuteur A dispose d’une deuxième solution qui consiste à utiliser un troisième code qui n’est ni le code A, ni le code B, autrement dit un code C, dont la condition sine qua non pour être employé est qu’il soit maîtrisé par les deux parties. Ce code C, dans notre étude, se trouve être le français. Il s’agit en quelque sorte d’un terrain plus ou moins neutre 80 , d’une sorte de langue véhiculaire (intra-situationnelle), d’une langue de « compromis » qui peut éviter ou élucider certains malentendus. Son utilisation dépend bien entendu de la situation de communication et donc des participants en présence qui peuvent s’y prêter plus ou moins bien.
- Enfin, la dernière solution à laquelle seul le locuteur A peut recourir est justement, de par son expérience de la langue B, l’utilisation de la langue B. C’est-à-dire qu’il va faire des tentatives d’adaptation pour essayer de parler la langue B, ces tentatives seront qualifiées de ratées ou réussies. Selon le degré d’exposition du locuteur A à ce code opposé, son utilisation à l’oral sera rendue possible ou non, mais il semble tout de même que cette stratégie soit, parmi les différents choix possibles, la plus complexe et la plus risquée à mettre en place. Une utilisation erronée peut faire naître des malentendus que seul le recours aux deux autres possibilités pourrait faire disparaître.
Si nous ne prenons pas en considération l’utilisation possible du français, la communication entre les locuteurs de dialectes différents d’arménien est une communication que l’on pourrait croire exolingue si nous nous contentons de dire qu’ils ne disposent pas d’un code réellement commun. Mais même si la langue arménienne possède des variantes, il existe tout de même un certain degré d’intercompréhension entre les locuteurs, et l’on passerait donc à une communication endolingue, entre individus de même « langue maternelle » 81 . Mais là encore nous ne pouvons, dans notre étude, nous contenter d’une dichotomie ferme, et nous placerons ces notions sur un continuum fonctionnant avec le critère d’intercompréhension. Plus l’intercompréhension entre les locuteurs parlant des dialectes différents d’arménien ou faisant des tentatives d’adaptation situationnelle sera grande, plus la communication sera endolingue et moins l’intercompréhension sera évidente, plus la communication sera considérée comme exolingue. Ceci nous empêche aussi de choisir fermement entre une ou deux communautés linguistiques, le premier cas reflétant un bon degré d’intercompréhension et donc une communication à tendance endolingue, et le deuxième cas représentant un degré d’intercompréhension nul et une communication à tendance exolingue. Nous reprenons les notions de communication exolingue vs endolingue qui sont généralement utilisées pour des langues différentes, et nous les adaptons au cas des dialectes (plus ou moins intercompréhensibles). Les deux extrémités du continuum seraient alors les suivantes :
- Communication exolingue (deux communautés linguistiques distinctes) : un locuteur arménien A en présence d’un auditeur arménien B parle uniquement son dialecte A, et jamais la variante de B, ce qui peut aboutir parfois à certaines incompréhensions (limitées par le fait que les codes parlés sont des variantes d’une même langue). Nous verrons que dans notre corpus, cette situation est de loin la plus fréquente, mais la communication n’est pas réellement exolingue étant donné que les deux systèmes linguistiques en contact possèdent une large base commune.
- Communication endolingue (une seule communauté linguistique) : un locuteur arménien A en présence d’un auditeur arménien B est capable de parler uniquement et de façon compréhensible la variante de B. Autrement dit, le locuteur A délaisse son code pour ne conserver que celui du locuteur B. Cette situation n’apparaît jamais dans nos données (nous excluons la base commune aux deux variantes).
- Entre les deux : nous aurions les locuteurs « adaptants », c’est-à-dire ceux qui mixent leur dialecte A avec certaines connaissances qu’ils ont de la variante B. Ici, nous aurions alors la création d’une sorte de communauté « bidialectale », pour les protagonistes ayant des notions dans les deux variantes en présence.
Voici la définition d’une communauté bilingue que proposent Hamers & Blanc (1983 : 28), que nous pouvons appliquer à la communauté bidialectale :
‘Pour qu’il y ait communauté bilingue il faut qu’il existe au moins deux groupes qui ne parlent pas la même langue et qu’il y ait au moins un certain nombre de membres dans chaque groupe qui soient bilingues (c’est-à-dire qui parlent une langue autre que leur langue maternelle), soit qu’ils parlent la langue de « l’autre groupe » de la communauté, soit qu’ils parlent une troisième langue utilisée comme lingua franca, une ou plusieurs de ces langues pouvant être les langues officielles de la communauté.’Un locuteur arménien fait donc partie de la communauté bidialectale s’il connaît un minimum l’autre variante d’arménien. Si nous mentionnons la place du français, nous basculerions d’une communauté bidialectale à une communauté bilingue cette fois-ci, le français remplissant le rôle de troisième code auquel on peut se référer en cas de difficultés dans les deux premiers.
Les membres qui feront partie de la communauté bidialectale auront ainsi, toujours d’après Hamers & Blanc (1983), plusieurs possibilités pour communiquer entre eux :
- soit ils parlent dans l’une ou l’autre des variantes arméniennes : c’est-à-dire soit dans leur variante d’origine, en partant du postulat que leurs interlocuteurs bidialectaux les comprennent, soit ils inversent leur variante, le locuteur A ne parlant plus que la variante B et le locuteur B ne parlant plus que la variante A (ce qui paraît peu probable) ;
- soit ils parlent dans l’une et l’autre des variantes arméniennes : ici, ils utilisent à leur guise les deux codes, de façon successive (code-switching) ;
- soit ils parlent un mélange des deux variantes arméniennes, autrement dit un code mixte, une sorte d’interlangue, ou plutôt d’« interdialecte », qui se sert simultanément des éléments faisant partie des deux variantes (code-mixing) 82 .
Ce choix de code va par ailleurs dépendre d’un certain nombre de contraintes d’ordre psychologique et sociologique, comme par exemple « une plus grande familiarité dans un sujet donné, le type d’interaction, le rapport entre les deux groupes, le statut relatif des deux langues, la perception des interlocuteurs, etc. » (Hamers & Blanc, 1983 : 31).
Voici la situation résumée sous forme de tableau :
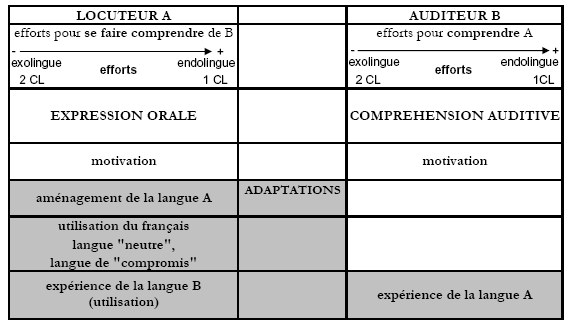
Dans une conversation en arménien entre locuteurs de dialectes différents, les deux parties auront la possibilité, si elles le souhaitent ou s’en sentent capables, de s’ajuster l’une à l’autre pour maximiser l’intercompréhension. En cela, cette situation pourrait se rapprocher d’une conversation exolingue se déroulant entre un locuteur natif et un alloglotte. Ce terme de conversation exolingue désigne généralement « toute interaction verbale en face à face caractérisée par des divergences significatives entre les répertoires linguistiques respectifs des participants » (Alber & Py, 1985 : 35).
Le locuteur natif et l’alloglotte dans une conversation exolingue, comme les locuteurs arméniens, ont recours à un certain nombre de procédés pour « compenser leurs divergences codiques initiales et assurer le bon déroulement de la conversation » (De Pietro, 1988 : 264). Les stratégies les plus connues et étudiées (correspondent dans notre tableau à « aménagement de la langue A ») dans de telles situations sont par exemple :
- la stratégie de « simplification », employée en général par le locuteur natif pour rendre son discours accessible à l’alloglotte,
- la stratégie de « reformulation », souvent utilisée par le natif également, pour parer aux éventuels malentendus dus à une incompréhension de l’alloglotte 83 .
La situation de contact que nous étudions se distingue d’une conversation exolingue (CE) sur plusieurs points :
- Les rôles des locuteurs : en CE, la plupart du temps, un des deux locuteurs prend le rôle de natif-enseignant, tandis que l’autre tient le rôle d’alloglotte-apprenant. La relation est donc asymétrique. Dans les conversations que nous étudions, aucun des locuteurs n’endosse l’un de ces rôles, ils ont des statuts symétriques de simples conversants et l’un ne sert pas de modèle à l’autre.
- L’inégalité des compétences linguistiques : l’alloglotte a une compétence moindre dans sa variante-cible par rapport au natif (dont c’est la variante-source). Dans nos conversations, les différents participants ont également des compétences inégales dans la variante arménienne opposée, mais ils ont la possibilité d’utiliser autant qu’ils le souhaitent leur propre variante (dans laquelle ils ont des compétences supérieures) pour s’exprimer. Ainsi, cette inégalité n’apparaît pas quand chaque locuteur arménien utilise sa variante-source.
- Les divergences codiques initiales : en CE, elles sont importantes puisque dans la plupart des cas étudiés, le natif et l’alloglotte ont des langues-sources différentes, alors que dans notre étude, les codes en contact sont des dialectes d’une même langue, ils possèdent une base d’éléments linguistiques communs, et sont donc intercompréhensibles, malgré les impressions décalées des locuteurs. De ce fait, les stratégies utilisées par les participants ne seront pas de même nature que celles utilisées en CE. Ces dernières ne semblent pas utiles dans la situation étudiée ici (ou en tout cas aussi utiles que dans les interactions monolingues). L’intercompréhension étant d’emblée assurée, les adaptations apparaissent alors comme des stratégies facultatives et « de confort », c'est-à-dire qu’elles sont destinées à améliorer (et non à assurer) l’intercompréhension. Elles sont certes peu fréquentes dans nos données, mais elles augmentent considérablement la qualité de l’interaction et c’est en cela qu’elles se montrent particulièrement originales à étudier.
Que ce soit du côté du locuteur ou de l’auditeur, la compréhension sera améliorée en fonction du degré de connaissances que l’un et/ou l’autre auront de la variante opposée et de leur motivation à s’en servir. Ainsi, par exemple, pour entre autres optimiser la compréhension, un locuteur de la variante A peut essayer de parler la variante B, c’est-à-dire qu’il s’adaptera dans son expression orale. Du côté de l’auditeur, selon ses capacités, il peut comprendre totalement ou partiellement la variante opposée, c’est-à-dire qu’il s’adaptera dans sa compréhension auditive.
Les deux qualités abordées par Hudson, et que nous avons développées et complétées, soulèvent un dernier problème à propos du critère d’intercompréhension. Cette dernière n’a pas forcément à être réciproque ou bilatérale (« equal in both directions », Chambers & Trudgill, 1980 : 4), étant donné que les participants A et B n’ont pas nécessairement le même degré de motivation pour se comprendre ou se faire comprendre l’un l’autre, et qu’ils n’ont pas non plus la même expérience concernant la variété de l’autre. Ainsi, même s’il s’est avéré que les deux standards arméniens sont mutuellement compréhensibles, nous observerons en contexte, avec des participants ayant des compétences, des expériences et des motivations bien différentes, comment les choses se passent réellement. Il est important de retenir que les différents degrés d’intercompréhension que nous observerons chez les protagonistes sont à placer sur un large continuum allant de la compréhension totale à l’incompréhension totale.
‘Typically, it is easier for a non-standard speaker to understand a standard speaker 84 than the other way round, partly because the former will have had more experience of the standard variety (notably through the media) than vice versa, and partly because he may be motivated to minimise the cultural differences between himself and the standard speaker (though this is by no means necessarily so), while the standard speaker may want to emphasise these differences. (Hudson, 1980: 36)’En ce qui concerne l’arménien, on ne peut pas vraiment parler de locuteur maîtrisant une variété standard ou non standard, étant donné que les deux variétés sont également considérées comme des standards.
L’étude des systèmes linguistiques de l’arménien oriental et de l’arménien occidental (Chapitre 2) montre, d’après le nombre de similitudes et de liens qui apparaissent, qu’il existe une forme d’intercompréhension certaine entre ces deux variétés. Elle sera plus ou moins marquée et forte chez les utilisateurs de la langue, chacun ayant des motivations différentes ainsi que des connaissances plus ou moins fournies du système de l’autre. Après avoir supposé selon les premiers critères de taille, de prestige et de standardisation que les deux variétés d’arménien semblaient bien correspondre à deux langues distinctes, le critère de l’intercompréhension, même s’il est critiquable à bien des égards, a pour mérite de rapprocher les deux standards d’arménien et montre que nous sommes bien en présence de deux variétés d’une même langue, que nous appelerons désormais des variantes, terme générique et peu ambigu : variante orientale et variante occidentale. Ces deux codes occupent les mêmes sphères langagières, mais ils sont utilisés par des locuteurs appartenant à deux groupes différents. D’une part, les aires d’utilisation sont donc identiques, superposées, et les utilisateurs distincts, et d’autre part, chaque variante regroupe sous son nom un ensemble de dialectes, et c’est en cela que le terme de variante apporte une précision supplémentaire que le terme de variété ne possède pas, ce dernier plaçant tous les types de codes (langues, dialectes...) au même niveau. Les deux variantes d’arménien sont donc deux variétés qui se situent à un même niveau et fonctionnent en parallèle, chacune représentant un certain nombre de dialectes qui désignent les mêmes unités de façon plus ou moins différentes. La langue arménienne possède donc deux variantes ou deux standards sous lesquels apparaissent des dialectes. Chaque locuteur arménien maîtrise un dialecte particulier qui, selon ses connaissances, son expérience et le contact avec d’autres codes, devient un véritable idiolecte, c’est‑à-dire un dialecte personnalisé, aménagé, avec des variations individuelles. En passant donc de la langue à l’idiolecte, on s’éloigne de plus en plus d’un système abstrait pour se plonger dans la réalité et se rapprocher d’un système personnel, existant et concret.