2.2.3. Adaptation de la notion de registre
Une autre possibilité terminologique, que nous avons rapidement évoquée, apparaît souvent dans la littérature sociolinguistique pour accompagner notamment la notion de dialecte : il s’agit du registre de langue employé.
Si nous comparons le terme de registre à celui de dialecte, nous constatons que le premier est utilisé en référence aux différentes variétés d’une langue selon l’usage, tandis que le second définit les variétés d’une langue selon l’utilisateur. Un locuteur peut maîtriser plusieurs registres, par contre, il est beaucoup moins attendu qu’il maîtrise plusieurs dialectes. Nous ne nous situons pas du tout sur le même plan : les registres sont en quelque sorte les différentes façons d’utiliser un même code, qu’il s’agisse d’un dialecte ou d’une langue, selon les circonstances. Ainsi, par rapport à la situation de communication et en fonction de l’interlocuteur qu’il a en face de lui, le locuteur sélectionne les éléments adéquats dans les registres dont il dispose. Il parle certes toujours le même code, mais n’utilise pas le même registre s’il écrit une lettre au président de la République ous’il raconte une blague à un ami !
Les dialectes, quant à eux, sont les différents codes qu’un locuteur suffisamment compétent peut éventuellement avoir à sa disposition. Là encore, selon la situation de communication établie, selon son niveau de maîtrise et l’interlocuteur auquel il s’adresse, il n’utilisera pas forcément le même dialecte.
‘At the risk of slight oversimplification, we may say that one’s dialect shows who (or what) you are, whilst one’s register shows what you are doing. (Hudson, 1980: 49)’Halliday (1978) propose une autre classification à propos des registres. Il distingue trois types de dimension pour les différents registres de langue : le « champ », le « mode », la « teneur » (c’est-à-dire le « style ») 86 . Selon ces trois variables, on aura affaire à des registres différents.
Mais comme l’évoque Hudson (1980), nous pouvons dire que comme les dialectes, les registres sont difficiles à délimiter. Ce ne sont que des variétés, comme les dialectes, et on ne peut pas les définir en soi, tant elles varient d’une situation de communication à une autre. Il est même possible parfois d’avoir des cas où le dialecte de quelqu’un correspond au registre de quelqu’un d’autre. C’est par exemple ce qui se passe avec des locuteurs natifs d’un dialecte standard ou non standard : les formes qui font partie du dialecte du locuteur standard, font partie d’un registre spécial chez le locuteur non standard. Une fois de plus, les interprétations seront donc différentes selon les informations dont nous disposerons et qui varieront selon la situation de communication et les locuteurs.
Dans notre étude, lorsque les deux variantes d’arménien entrent en contact, il est possible que les participants souhaitent entre autres améliorer l’intercompréhension. Pour ce faire, ils tentent de produire ce que nous avons appelé des adaptations situationnelles à la variante opposée, c’est-à-dire qu’ils essayent, par exemple, d’utiliser par moments le même système linguistique que celui de leur interlocuteur, et qui n’est pas leur système de base. Ensuite, le fait que ces adaptations soient réussies ou non nous amène sur un plan évaluatif que nous n’aborderons pas pour le moment, le plus important à retenir étant les tentatives qui sont faites. Si nous reprenons la proposition de Halliday (1978), ces adaptations pourraient ressembler à une volonté d’utiliser un registre particulier, dans une situation de communication particulière et avec des participants spécifiques. Les locuteurs ont la possibilité de changer de registres uniquement dans ce type de situation, c’est-à-dire lorsque les deux variantes, de par l’utilisation qu’en font les participants, sont en contact.
Afin de simplifier les choses autant que faire se peut, nous ne conserverons pas la notion de registre qui ne nous paraît pas suffisamment distinctive pour parler des différences purement linguistiques qui existent entre l’arménien oriental et l’arménien occidental. Nous la restreindrons volontairement à l’usage de différents styles langagiers chez un même locuteur parlant un seul et même code, même si, contrairement à ce que l’on a coutume de penser, ces styles ne portent pas seulement sur le lexique, mais également sur des phénomènes phonologiques, intonatifs, morphologiques ou syntaxiques. A ce propos, Gadet (1997) en étudiant la langue française et toutes les formes de variations qu’elle peut comporter, développe dans ce cas précis la notion de variation stylistique ou situationnelle que nous pouvons tout à fait appliquer à notre situation et explique :
‘[...] il n’y a pas de locuteur à style unique. Contrairement à l’idée reçue selon laquelle seules les couches cultivées seraient capables de maniements variés modulés selon les situations, tous les locuteurs disposent de plusieurs styles en liaison avec la situation dans laquelle ils se trouvent, l’interlocuteur auquel ils s’adressent, le sujet dont ils parlent, les enjeux sociaux qu’ils mettent dans l’échange... (Gadet, 1997 : 5)’Quand on parle ici de registres, de niveaux ou de styles, on s’appuie sur une autre classification (celle de Coseriu, 1973) diaphasique qui concerne très souvent le lexique et qui peut, par exemple, aller du vulgaire à l’archaïque, en passant par l’argotique, le populaire, le familier, le courant, le soutenu ou le littéraire. Autrement dit, l’utilisation que font les locuteurs de la langue est jugée, par rapport à une certaine norme, qu’il est évidemment difficile d’établir, de définir et de maintenir. Ceci dit, une simple classification diaphasique n’est pas suffisante, il faudrait dans l’idéal la compléter et la croiser avec une classification diastratique (en fonction des groupes sociaux) et même diatopique (en fonction du lieu d’origine des locuteurs).
Notre but n’étant ni de juger les usages langagiers des locuteurs, ni de tenter de classer leurs paroles selon les différents styles dont ils disposent, nous n’emploierons finalement pas la notion de registre.
Nous retiendrons en revanche cette démarche intéressante des locuteurs qui consiste à changer de registres en fonction de la situation de communication et des participants, en l’appliquant plus globalement à nos deux variantes d’arménien. C’est a priori ce qui risque de se passer : selon l’interlocuteur qui sera en face, selon la situation de communication établie, selon les capacités du locuteur, celui-ci va ou non changer de variante.
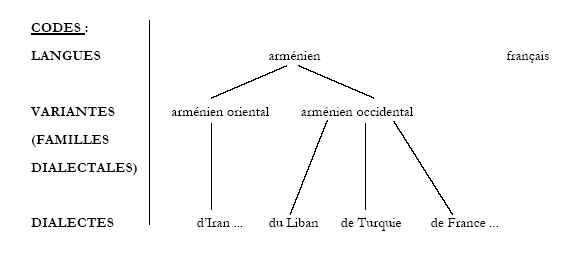
Voici un premier schéma pour reprendre les différents codes disponibles dans le corpus (pour les dialectes, nous n’avons noté que ceux qui étaient attestés dans nos données) :