1.2. Le corpus micro
1.2.1. La transcription
La constitution d’un corpus de données authentiques comporte deux opérations principales : la première consiste en la phase d’enregistrement à proprement parler, composée de la capture des données et de leur numérisation ; la seconde consiste en la transcription des données recueillies, ou d’une partie des données, et dans notre cas particulier en la traduction de celles-ci qui vient obligatoirement compléter la transcription. Chacune de ces opérations établit à sa façon une sélection des données. Nous avons distingué ces deux opérations en choisissant d’établir, comme nous l’avons précédemment mentionné, deux types de corpus, un corpus macro reprenant la première opération, et un corpus micro représentant la seconde procédure. Nous venons de décrire précisément le contenu et la façon dont a été recueilli le corpus macro, c'est-à-dire la façon dont a été menée la première phase de traitement des données. La seconde phase, servant à constituer le corpus micro, a consisté à sélectionner certains passages tirés du corpus macro et à les traiter avec des logiciels spécialisés afin de les transcrire et de les analyser. Plus nous affinons le traitement des données, plus l’objet de recherche se précise et se restreint. Ainsi, l’objet de recherche reflétant une situation particulière de contact de dialectes (par rapport à d’autres situations de communication monolingue ou plurilingue) s’est vu affiné lors de l’établissement du corpus et de son traitement. Les différents choix que nous avons dû faire pour assurer la réalisation du projet, en sélectionnant les locuteurs en contact, les lieux d’enregistrements, puis les transcriptions, ont précisé, contraint et limité de plus en plus notre objet de recherche.
La phase de transcription des données sélectionnées a été de loin l’étape la plus délicate à entreprendre. Pour mener à bien ce travail, nous nous sommes essentiellement servie du logiciel d’alignement, Praat, qui permet d’aligner de façon très précise l’audio et la transcription (notamment dans le cas particulier des chevauchements de parole), et auquel nous avons été sensibilisée et formée par des chercheurs de notre laboratoire. Il se présente en format partition, ce qui offre l’avantage de situer l’axe du temps horizontalement, et permet d’attribuer une ligne (appelée tier) à chaque locuteur ainsi qu’à tout autre type d’annotation utile. Des barres verticales permettent d’isoler les segments audios et d’insérer entre chaque paire (de barres verticales), la transcription correspondant au signal audio. En revanche, le format partition de ce logiciel convivial pour la transcription et l’écoute multiple, n’est pas adapté à notre travail d’analyse. Pour cette raison, nous avons eu recours à des convertisseurs, élaborés dans notre laboratoire 132 , qui vont nous permettre de changer de format et de passer d’un format partition à un format liste, c’est-à-dire que cette fois-ci, l’axe du temps est représenté verticalement. C’est ainsi qu’on parvient notamment à lire les transcriptions en format texte (par exemple dans Word).
Nous présentons ci-après un extrait de transcription effectuée sous Praat :
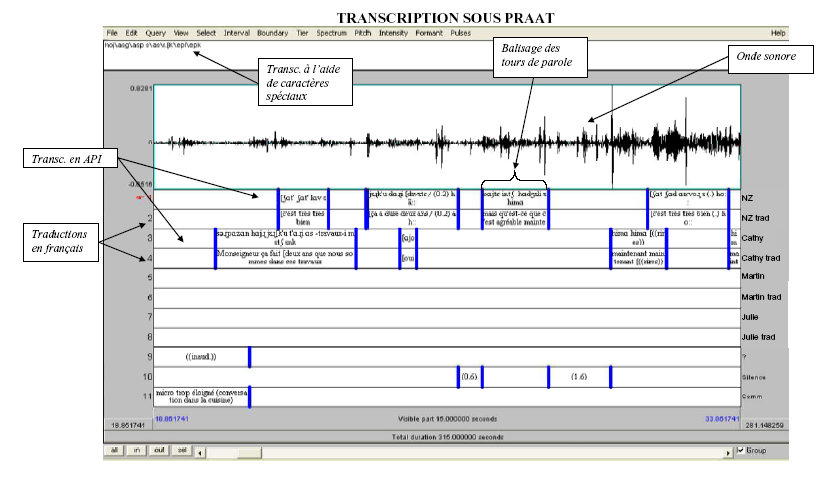
La langue des interactions enregistrées n’étant pas « simplement » le français, un des premiers choix que nous avons eu à faire concernait le code qui allait convenir pour transcrire au mieux le matériel verbal capté. Il ne suffisait pas seulement de choisir, comme ce qui est courant dans des interactions monolingues présentées à des lecteurs endolingues, entre une transcription en orthographe standard ou une transcription en orthographe adaptée. Il nous fallait rendre compte d’une langue étrangère pour la plupart des lecteurs et qui possédait son propre système d’écriture. Le choix de recourir à l’Alphabet Phonétique International (disponible dans Praat grâce à une liste de combinaisons de codes ad hoc) pour l’arménien parlé s’est alors avéré indispensable, et ce, pour deux raisons principales. Premièrement, pour un souci d’accessibilité : l’arménien possédant comme nous venons de le dire son propre système graphique, celui-ci est difficilement déchiffrable pour des non-spécialistes de la langue. Deuxièmement, cet alphabet neutralise une des différences qui nous intéresse entre les deux variantes d’arménien, et qui se situe au niveau phonologique. Rappelons qu’il existe dans le dialecte oriental une triple distinction pour les consonnes occlusives et affriquées : voisées / non voisées / aspirées qui, au moment du passage au dialecte occidental, devient double (suppression du trait d’aspiration) et s’inverse. Comme nous l’avons déjà montré, l’alphabet arménien ne permet pas de rendre compte de ce type particulier de variation, et l’A.P.I. est de loin l’outil le plus précis pour noter ces différences majeures de prononciation.
Un des problèmes qu’a soulevé l’utilisation de l’A.P.I. a été la segmentation en unités, qui ne sont évidemment pas les mêmes à l’écrit et à l’oral, où le blanc (qui sépare les mots) et la ponctuation n’ont aucune pertinence. Les unités graphiques, c'est-à-dire les mots (simples ou complexes), n’ont pas de pertinence à l’oral (qui regroupe des groupes rythmiques et syntaxiques), dans les transcriptions en A.P.I.. Pourtant, dans un souci de lisibilité, nous avons été obligée d’emprunter cette notion de mot graphique (basé sur le système d’écriture arménien) et de la réemployer dans les transcriptions en A.P.I.. Ainsi, nous avons pu reconstituer l’arménien en reproduisant toutes ses variations de prononciation, en respectant son découpage en unités graphiques telles qu’elles apparaissent à l’écrit (qu’il s’agisse de mots ou de morphèmes), tout en évitant d’utiliser son alphabet spécifique qui d’une part neutralisait la prononciation, et d’autre part empêchait la lecture.
Ce travail de transcription a constitué une des difficultés majeures de notre étude et a révélé la solitude à laquelle nous avons été confrontée. En effet, nous nous sommes intéressée à la transcription fine en A.P.I. de deux variantes d’une langue étrangère comportant notamment des différences phonétiques, et nous avons utilisé un logiciel spécialisé auquel nous avons dû nous former, nécessitant des codes particuliers pour représenter les symboles. Notre tâche s’est donc avérée bien vaste et compliquée. Il a été impossible de trouver un transcripteur qui, en plus de maîtriser l’A.P.I., aurait maîtrisé les deux variantes arméniennes, aurait été sensible à leurs différences pour être capable de les noter, tout cela sans être normatif, c'est-à-dire sans juger les énoncés qu’il entendrait, issus de données orales naturelles et non construites. Notre seule tentative a vite avorté à cause de la difficulté la plus délicate à surmonter qui est l’obsession normative du transcripteur (« ce locuteur parle mal, je vais corriger ses fautes de grammaire et rétablir ce qu’il aurait dû dire… ») combinée à l’influence de l’alphabet arménien qui l’empêche de percevoir et donc de noter les différences phonétiques (qui sont neutralisées dans l’alphabet arménien). Alors seule face à cette montagne de données enregistrées, nous avons dû nous rendre à l’évidence qu’il nous serait impossible d’en transcrire même plusieurs heures, sachant qu’il fallait au minimum une heure pour transcrire (sans compter le travail de traduction) une minute d’interaction. C’est ce qui nous a contrainte à constituer deux types de corpus : un corpus macro dont les analyses globales seraient basées sur des écoutes répétées ainsi que sur des prises de note sur les passages intéressants des interactions pour comprendre leur déroulement, et un corpus micro contenant environ une heure de transcription et reflétant trois situations différentes. Le corpus macro a été suffisamment riche et diversifié pour nous permettre de tirer certaines généralités quant à l’économie des choix de langues, là où le corpus micro nous a permis de nous arrêter sur une étude de cas particulier, mettant en valeur le phénomène des adaptations qui nous intéressait. Constatant que celui-ci est minoritaire dans la totalité des données, il aurait été d’une part inutile de transcrire des heures entières de conversation, et à l’inverse difficile d’exploiter uniquement des segments, contenant des adaptations, isolés de tout contexte ou presque. Le sous-corpus Pâques (à l’intérieur du corpus micro) présente des séquences particulièrement riches en adaptations, pour lesquelles nous avons pu concevoir une analyse quantitative et qualitative.
Cette transcription est de surcroît complétée d’une traduction en français, pour la rendre accessible. Dans Praat, elle apparaît dans une ligne spécifique sous chaque tier de locuteur ; dans Word, elle apparaît également sous chacun des tours de parole arméniens des locuteurs. Nous avons voulu cette traduction la plus proche possible du français standard ou oral, en conservant malgré tout une traduction littérale pour certains mots, expressions ou concepts qui n’avaient pas leurs équivalents en français. Elle ne sert que de support à la lecture et à la compréhension du sens global de l’interaction, et permet juste d’indiquer matériellement (en les soulignant) les segments sur lesquels portent les phénomènes qui nous intéressent. Pour comprendre le fonctionnement des adaptations, il faudra se référer systématiquement aux tours de parole en arménien pour tenter d’identifier les segments ainsi que les strates linguistiques touchées par ces adaptations. Lorsque cela s’est avéré nécessaire, la traduction française s’est rapprochée du mot à mot arménien, et certains découpages morphosyntaxiques ont parfois été effectués (gloses).
Un des derniers problèmes à résoudre concerne la mise en valeur des items touchés par les adaptations. Très souvent dans les études portant sur le code-switching ou le code-mixing, les exemples relevés comportent une police pour la « langue matrice » et une police pour la « langue insérée » différentes l’une de l’autre.
Nous avons fait le choix, plus neutre, de souligner les items concernés par le phénomène général d’adaptation, ce qui a l’avantage d’éviter de surcharger la transcription, déjà enrichie de sa traduction et de toutes ses conventions. Le soulignement indique au lecteur que l’item marqué comporte une variation, et qu’il est différent (partiellement ou totalement) de la forme initiale attendue dans la variante-source. Ainsi, en évitant au niveau du corpus de distinguer les codes à l’intérieur d’un même item, nous évitons d’anticiper sur le travail d’analyse et d’interprétation. De plus, toutes les formes soulignées faisant partie d’une étude approfondie (cf. Chapitre 5), leur double-marquage aurait été parfaitement redondant et plus que complexe à déchiffrer. En effet, le travail portant sur deux variantes d’une même langue, une partie importante des systèmes linguistiques est commune aux deux. Ainsi, si un item commun aux deux variantes ne comporte qu’une différence au niveau phonétique, l’utilisation de deux codes simultanés sur un même item est impossible et le privilège d’un code sur un autre serait incorrect. L’utilisation du soulignement nous a donc paru le meilleur moyen pour mettre en valeur les items qui comportent une différence quelle qu’elle soit et qui bénéficieront plus loin d’une analyse détaillée.

La transcription fine respecte enfin des conventions permettant de coder à l’écrit certains phénomènes propres à l’oral. Là encore, nous nous sommes basée sur des outils existant et développés au sein de notre laboratoire, et nous avons choisi d’adopter la convention de transcription appelée ICOR. Nous avons d’ailleurs fait partie du groupe de discussions pour l’élaboration de cette convention large et commune, permettant notamment d’effectuer des études quantitatives sur certains phénomènes (comme les chevauchements). Nous n’utilisons ici qu’un sous-ensemble de la convention ICOR, disponible dans son intégralité en ligne 133 , autrement dit uniquement les phénomènes que nous avons eu besoin de transcrire, auxquels nous avons ajouté des phénomènes spécifiques à notre situation (qui apparaissent en gras dans les colonnes « Phénomènes » et « Conventions en format liste »). Cette forme étendue de la convention ICOR est accompagnée d’exemples tous issus de notre corpus.
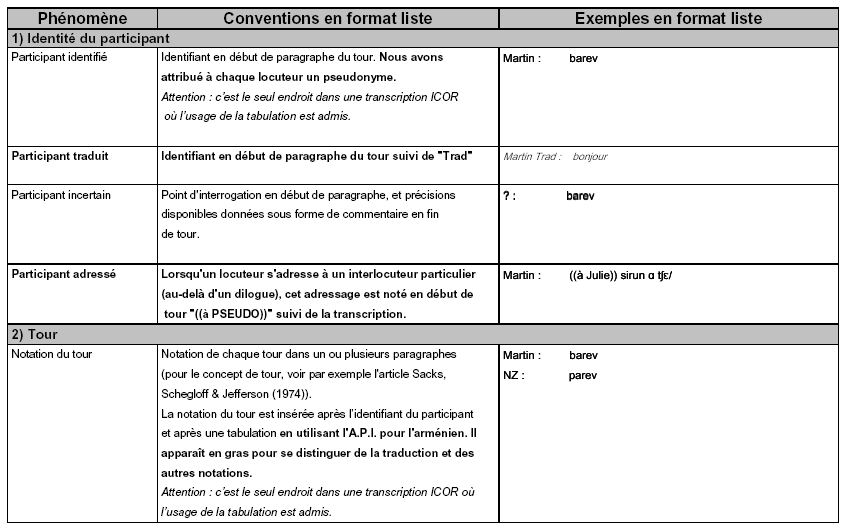
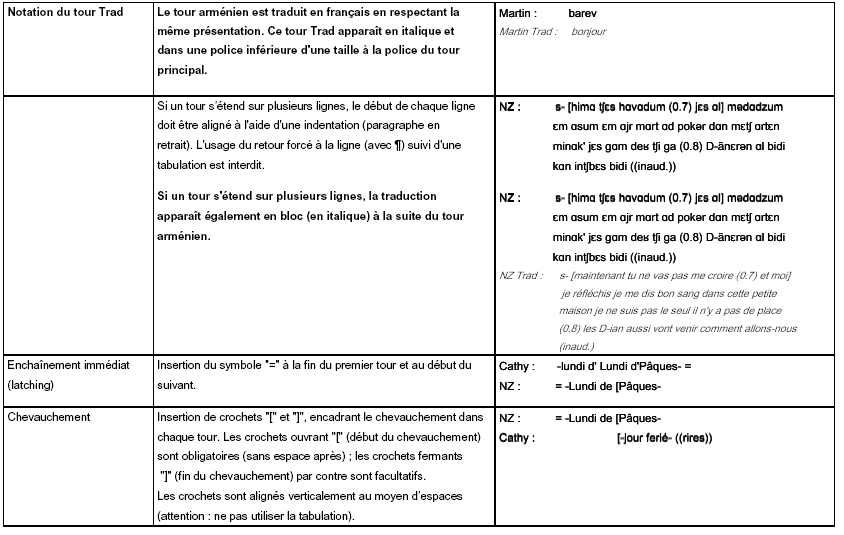
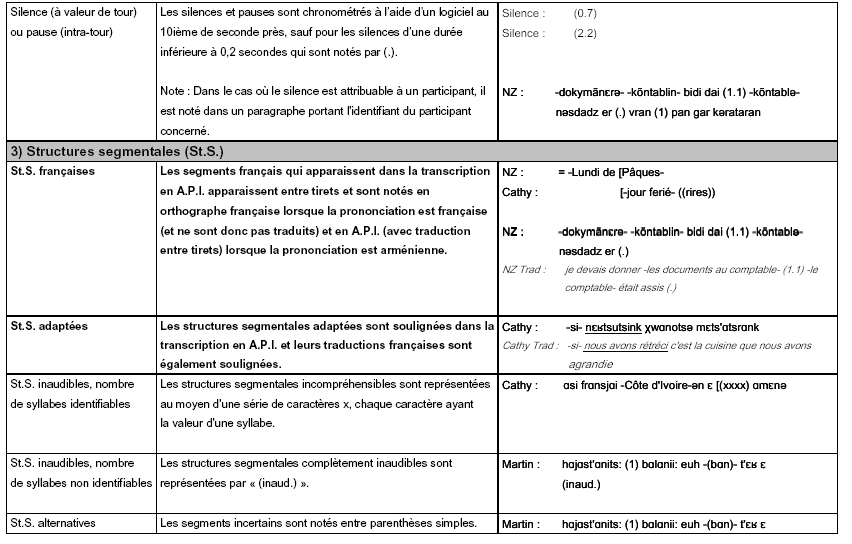
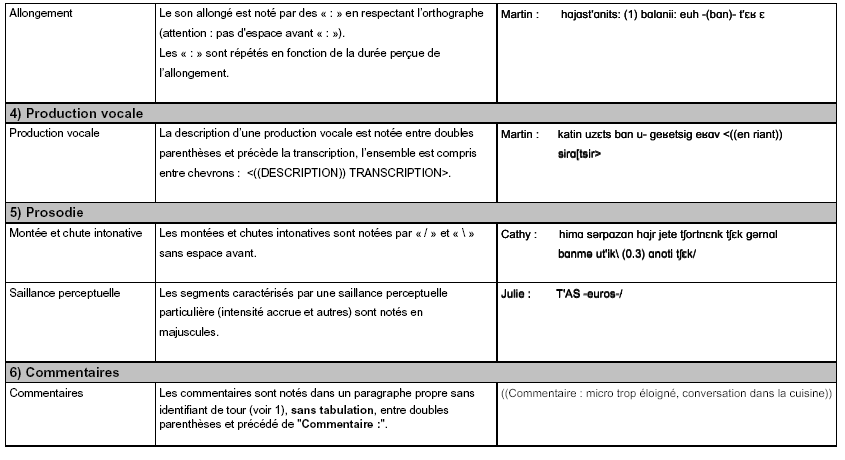
Grâce aux différents outils employés, notre étude basée sur des données authentiques auxquelles nous avons donné une dimension écrite pour pouvoir aisément les analyser, dispose à la fois d’éléments précis et techniques en profondeur, ainsi que d’une mise en forme conviviale et confortable en surface.