Chapitre 5. L’analyse du corpus
1. Méthodologie pour le traitement des données
1.1. Traitement global
Avant de présenter concrètement le travail d’analyse, il nous faut expliquer les étapes préalables qui ont été nécessaires pour y parvenir. Pour traiter nos données, nous nous sommes inspirée de la méthodologie proposée par Mackey (1976), s’intéressant de près au fonctionnement de ce que lui appelle les interférences, c’est-à-dire l’utilisation de traits qui appartiennent à une langue alors qu’on est en train d’en parler une autre. Plus globalement, il s’agit de comprendre ce qui se passe quand deux codes entrent en contact. Nous reprenons dans notre analyse les trois démarches suggérées par Mackey, mais nous proposons d’aller encore plus loin pour comprendre le fonctionnement des adaptations. Pour décrire l’interférence, ou plus généralement ce qui se passe en situation de contact de codes, il faut :
‘(1) découvrir précisément quel est l’élément étranger que le locuteur introduit dans son discours ; (2) analyser ce qu’il en fait (substitution ou modification) ; et (3) établir dans quelle mesure les éléments étrangers remplacent les éléments de la langue réceptrice.La première de ces démarches consiste à identifier l’élément étranger, à le comparer avec ses équivalents dans le parler unilingue de la région et à découvrir dans la langue étrangère la source qui est à l’origine de l’interférence. Cette démarche repose sur une description précise et complète des deux langues en cause et sur une analyse des différences qu’elles présentent. (Mackey, 1976 : 401)’
Mackey soulève le fait que les descriptions différentielles de codes en contact sont rares et souvent incomplètes. Sans prétendre avoir établi une sorte de grammaire contrastive de l’arménien, il s’agit en tout cas bien de cette méthodologie pour laquelle nous avons opté pour comprendre le fonctionnement des adaptations dans les interactions, et cette grammaire présentée au Chapitre 2 est le point de départ de notre analyse.
La méthodologie que nous avons adoptée est avant tout composée d’une série de pré-traitements (transformation, extraction, numérotation…) indispensables à son exploitation. Le corpus Pâques a été transcrit sur une durée de 20 min. La transcription a pu être récupérée pour être exploitable dans le logiciel Excel. Pour ce faire, la totalité des items composant le corpus a été saisie semi-automatiquement dans un fichier Excel, sous forme de tableau 137 . A l’aide d’un logiciel éditeur de texte du nom de Emacs, un travail de réécriture de texte a été nécessaire, en utilisant d’une part des « rechercher-remplacer » sur des expressions régulières et d’autre part, des macros créées dans ce logiciel.
La transcription en format txt a alors pu être transformée en format colonne, appelé aussi CSV 138 , que le logiciel Excel est capable de lire sous forme de tableau. La transcription entière a d’abord subi un premier nettoyage dans le logiciel Emacs : ont été retirés la traduction en français, les silences, les didascalies et les crochets (signes de chevauchement entre plusieurs locuteurs).
Une numérotation automatique a ensuite été ajoutée, différente de celle pré-existante dans la transcription de base. Dans cette dernière, nous avions numéroté toutes les lignes (y compris les lignes de traduction, de silence et de commentaires), ne voulant pas entrer dans une numérotation délicate des tours de parole, souvent difficile à délimiter pour diverses raisons. Dans le logiciel Emacs, la seconde numérotation laisse intacte celle d’origine, pour permettre de retrouver dans la transcription les items relevés dans le corpus, et ne fait que numéroter les items retenus les uns après les autres. Cette numérotation permet de recomposer à tout instant la structure de la transcription (sans traduction) de départ, c’est-à-dire de retrouver l’ordre chronologique du déroulement des items disposés dans une même colonne, ce qui permet d’élargir et de repérer le contexte d’emploi de ces items.
Une fois ce premier nettoyage effectué dans Emacs, les données ont été transférées dans Excel, les basculant sous forme de tableau. Chaque item numéroté est alors apparu à la suite du numéro de la ligne sur laquelle il figurait dans la transcription, le locuteur qui l’employait et la variante d’origine du locuteur. Un deuxième travail de nettoyage a alors été nécessaire sous Excel, durant lequel d’une part, nous avons supprimé le reste des commentaires et des silences, ainsi que tout matériau verbal ou non verbal non pertinent pour notre analyse (telles les marques d’hésitation par exemple), et d’autre part, nous avons volontairement procédé à certains regroupements qui s’avéraient indispensables pour notre étude.
Voici un extrait du tableau obtenu sous Excel et qui figure dans les annexes (Annexe VII).
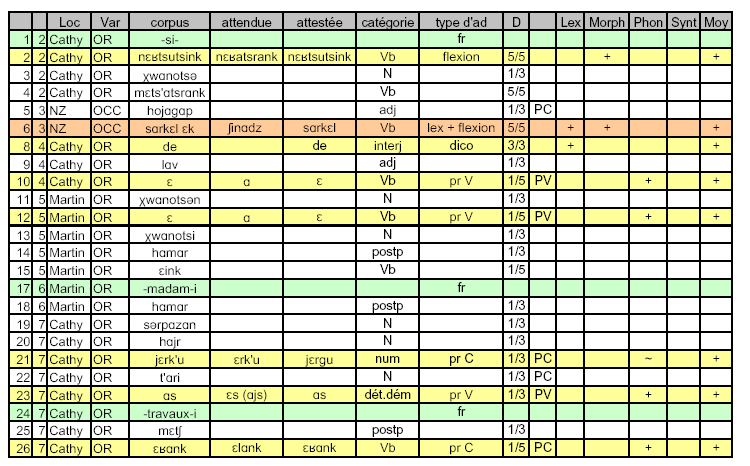
Nous avons ainsi regroupé, sous une entrée unique, les formes verbales analytiques (auxiliaire + participe ou particule d’actualisation + base verbale 139 ), étant donné qu’en cas d’adaptation, certaines de ces formes n’étaient pas partiellement (c’est-à-dire uniquement l’auxiliaire qui varie d’une variante à l’autre), mais totalement affectées (comme c’est le cas dans l’exemple exposé dans la note 3). Ce choix a pu nous éviter de démultiplier les catégories morpho-syntaxiques en évitant par exemple d’étiqueter différemment le morphème être comme étant tantôt un auxiliaire pour les formes verbales analytiques, tantôt un verbe plein. Ce morphème apparaît donc soit seul, soit accompagné de la base verbale dont il est l’auxiliaire, et dans les deux cas, ces formes sont étiquetées comme étant des verbes (formes simples ou composées). La totalité des items (simples ou complexes) recensés dans le corpus, après nettoyage et regroupement, s’élève alors au nombre de 1269.