1.2. Cas particulier des adaptations
Tous les items relevés apparaissent verticalement et chronologiquement dans le tableau Excel, dans une même colonne appelée « formes relevées dans le corpus » qui ne sont autres que les attestations enregistrées en discours. Cette colonne est complétée par celle donnant la nature morpho-syntaxique de l’item ainsi que son degré de distance (par rapport à la forme attendue), établi après comparaison des deux systèmes linguistiques arméniens, dont il fait partie. Dans le cas où des adaptations se produiraient, et c’est dans ce cadre-là que la méthodologie proposée par Mackey (1976) nous a été utile, il a été nécessaire de remplir, dans un premier temps, deux autres colonnes apportant des informations complémentaires :
- A côté de la forme relevée dans le corpus, nous avons fait figurer la forme attendue dans la variante-source, c’est-à-dire dans la variante d’origine du locuteur, celle qu’il était attendu qu’il utilise dans son propre système en l’absence d’interférence et donc de contact avec un interlocuteur d’un autre dialecte.
- Nous avons également indiqué la forme attestée dans la variante-cible 140 (toujours en comparaison avec la forme relevée dans le corpus, mais aussi à rapprocher de la forme attendue dans la variante-source). Il s’agit, cette fois-ci, de la forme qui existerait effectivement dans la variante dialectale de l’interlocuteur, et non plus dans la variante d’origine du locuteur. Nous précisons qu’à chaque fois que cela a été nécessaire, nous avons vérifié avec nos locuteurs les formes d’origine (à tous les niveaux linguistiques) pour rester le plus proche possible des formes orales faisant partie de leurs systèmes.
‘[…] Lorsqu’on analyse une interférence dans un texte, il faut d’abord en découvrir la source dans le dialecte de la langue d’où elle provient, puisqu’elle sert de modèle. […] Après avoir identifié la source dans la langue d’où vient l’interférence, nous la comparerons avec son produit dans le texte. Cela nous permettra de déterminer le type de substitution qui a été effectué. […] On peut considérer l’interférence sous deux aspects : ce que le bilingue importe (importation) et ce qu’il en fait (substitution). (Mackey, 1976 : 399)’En comparant rigoureusement les contenus des trois colonnes adjacentes, nous avons pu comprendre le fonctionnement des adaptations. Plus la forme de la première colonne (forme relevée dans le corpus) ressemblait à celle de la deuxième (forme attendue dans la variante-source), plus l’adaptation était minimale et subtile 141 mais pour autant bien existante ; et plus la forme de la première colonne se rapprochait de celle de la troisième (forme attestée dans la variante-cible), plus l’adaptation était importante (qu’elle soit partielle ou totale). L’adaptation est complète et maximale si la forme de la colonne 1 est complètement identique à la forme de la colonne 3. Mais bien souvent, les adaptations se situeront sur un continuum entre les colonnes 2 et 3. Le schéma suivant permet de visualiser les variantes possibles d’une même attestation tirée du corpus :

Voici un exemple extrait du tableau d’analyse :

Pour résumer :
- si colonne 1 = colonne 3, alors l’adaptation à la variante opposée est totale et donc « réussie »,
- si colonne 1 ≠ colonne 2 et colonne 3, alors l’adaptation à la variante opposée est seulement « partielle » (et donc « partiellement réussie » ou « non-réussie »).
La deuxième tâche après cette phase de nettoyage, de regroupement et de comparaison, consistait à mettre sur chaque attestation issue du corpus une étiquette permettant de définir clairement sa catégorie morpho-syntaxique d’appartenance. Pour ce faire, nous nous sommes basée sur les catégories auxquelles nous avions eu recours lors de la description des deux systèmes arméniens..
Le premier graphique présenté ci-dessous donne une idée de la répartition des différentes catégories morpho-syntaxiques existant en arménien et qui sont présentes dans la totalité du corpus Pâques, sans distinction de variantes.
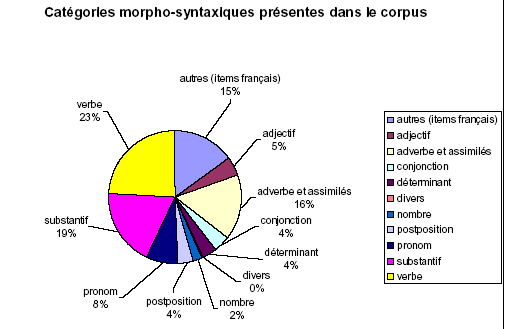
Sous l’étiquette « autres » qui, contrairement aux autres, ne représente pas une catégorie morpho-syntaxique, nous regroupons tous les items français apparaissant dans le discours. Par là, nous avons souhaité uniquement mettre en valeur la place que prenait la langue française dans la totalité du corpus Pâques. Nous n’avons pas établi de graphique initial représentant clairement la répartition des deux langues, l’arménien et le français, dans la totalité du corpus, mais après calcul, cette répartition s’élève à 85% d’arménien pour 15% de français. Nous avons choisi d’intégrer le français dans le graphique présenté ci-dessus pour montrer la place minoritaire qu’il occupait dans le sous-corpus étudié. Les interventions françaises viennent se fondre dans le discours arménien, à des moments où celui-ci fait défaut pour différentes raisons. Nous serions donc en présence d’une forme de code-mixing ou de code-switching arménien-français. Nous ne serons pas en mesure d’exploiter ces données concernant le français (voir cependant, dans ce même chapitre, quelques pistes en 4.), le but de notre travail étant avant tout de décrire ce qui se passe au niveau des deux variantes d’arménien lorsqu’elles sont mises en contact en discours. Pour cette raison, nous n’avons pas détaillé le contenu morpho-syntaxique de cette partie ad hoc du graphique. Dans une nouvelle étude, il pourrait être intéressant de savoir notamment quelles sont les catégories morpho-syntaxiques les plus touchées par l’utilisation du français.
Les autres catégories proprement morpho-syntaxiques apparaissant au fil du corpus renvoient à toutes les catégories qui sont pertinentes en arménien et qui ont été décrites lors de la présentation des systèmes des deux variantes d’arménien (voir Chapitre 2). Elles sont recensées dans le tableau suivant qui indique le nombre d’items présents dans le corpus pour chacune des catégories :
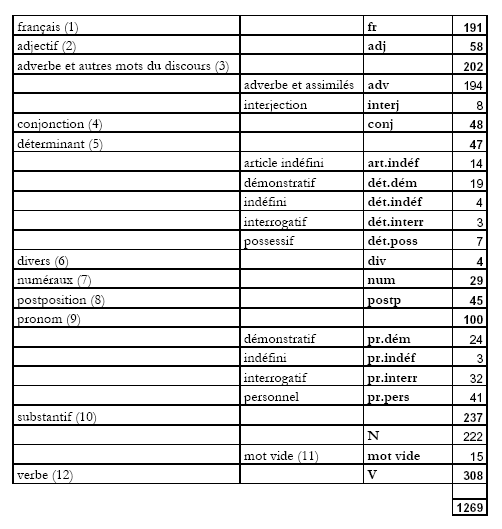
(1) Français : nous retrouvons ici tous les mots français.
(3) Adverbes et mots du discours : la catégorie des adverbes est une catégorie floue, bien difficile à définir et à délimiter. Elle sert, en général, à regrouper sous la même étiquette tous les mots pleins qui ne sont ni des noms, ni des verbes, ni des adjectifs, ni des adpositions.
‘[…] dès lors qu’on cherche à préciser la délimitation traditionnelle de la classe des adverbes, on aboutit rapidement à la conclusion qu’il n’existe aucun moyen de définir positivement l’ensemble des mots ainsi étiquetés. L’étiquette ‘adverbe’ telle qu’elle est traditionnellement utilisée n’est guère plus qu’un terme commode pour désigner les mots qui, pour une raison ou pour une autre, ne se rangent de manière évidente dans aucune des autres classes de mots. (Creissels, 2006a : 249)’L’étude approfondie de cette catégorie hybride n’étant pas nécessaire dans le cadre de notre travail, nous nous contentons de sa définition traditionnelle. Notre but est essentiellement de montrer la représentativité de chacune des familles morpho-syntaxiques pertinentes.
(4) Conjonction : cette catégorie regroupe les conjonctions de subordination et les conjonctions de coordination.
(5) Déterminant : dans la catégorie des déterminants, un traitement particulier a été accordé systématiquement au déterminant article indéfini, étant donné qu’il a un comportement morpho-syntaxique complètement différent en arménien oriental et en arménien occidental. Il est donc très intéressant à étudier : sa forme est différente ainsi que sa position puisque d’une variante à l’autre il est placé devant le nom ou derrière celui-ci. Pour les autres déterminants, lorsque la distinction ne sera pas pertinente, nous aurons tendance à les regrouper sous le même hyperonyme.
(6) Divers : cette catégorie surnommée divers est une catégorie volontairement floue, dans laquelle nous retrouvons quelques rares unités isolées dont l’étiquetage précis et systématique ne nous a pas semblé distinctif et pertinent (ex : k’arts’es « on dirait que », megen « d’un coup »…).
(7) Numéraux : nous avons regroupé dans cette partie les numéraux, qui peuvent porter des étiquettes différentes selon le contexte dans lequel ils sont employés. La plupart du temps, ils incarnent le rôle de déterminant numéral cardinal, mais ils peuvent également être un type de pronoms dits « indéfinis particuliers », qui sont des « quantificateurs ». Ceci se produit dans le cas où ils fonctionnent anaphoriquement, c’est-à-dire qu’ils ont « un antécédent nominal dont ils identifient un sous-ensemble ou dont ils empruntent la valeur lexicale » (Riegel et al., 1994 : 211).
(8) Postposition : l’arménien est une langue à postpositions, c’est-à-dire qu’il possède des mots de relation invariables qui se placent après le mot qu’ils rattachent à un autre élément de l’énoncé. Les autres mots de relation sont les conjonctions que l’on retrouve en (4).
(9) et (10) Pronom et substantif : pour les catégories nominales et pronominales, nous regarderons plus en détail les variations qui nous intéressent entre les deux variantes d’arménien et qui portent sur la déclinaison.
(11) Mot vide : nous distinguons, parmi les substantifs, une sous-catégorie particulière. Cette terminologie de mot vide 142 est employée par certains auteurs, mais il serait certainement plus approprié de parler d’« archi-hyperonymes » ou de « mots omnibus » pour désigner des mots comme « chose », « machin », « truc » qui existent en français et qui ont également leur équivalent en arménien avec le mot bɑn / pɑn. Il s’agit de mots qui sont dépourvus de sens particulier, mais qui prennent un sens spécifique au sein du contexte dans lequel ils sont employés. Ils servent très souvent à remplacer dans le discours du locuteur le mot auquel il ne parvient pas à avoir directement accès. Ils peuvent également servir à compléter des informations qui ne seraient pas nécessairement véhiculées par le matériau verbal, mais qui pourraient être apportées par le matériau non-verbal comme les gestes, les mimiques, les postures, la présence ou l’absence de référent ; enfin, on peut encore les retrouver en tant que simples mots-phrases, tout comme les interjections. Ces procédés existent bien en arménien, puisque nous avons retrouvé dans l’ensemble du corpus Pâques, une quinzaine d’occurrences de ce type.
(12) Verbe : nous retrouvons dans cette dernière catégorie, de loin la plus riche (308 occurrences sur un total de 1269 formes), aussi bien les formes verbales simples que les formes verbales analytiques. Ici, ce qui nous intéressera particulièrement sont les différentes réalisations possibles d’une variante à l’autre pour exprimer la temporalité verbale.
Une fois toutes les unités simples ou complexes étiquetées, nous avons fait un premier classement sous Excel, par catégories morpho-syntaxiques, pour obtenir le premier tableau.
D’après les données du tableau et d’après le graphique qui les reprend sous forme de pourcentages, nous nous apercevons que les catégories les mieux représentées dans le corpus étudié sont de loin les verbes, les substantifs, les adverbes ainsi que les occurrences en langue française, ces deux dernières catégories étant quasi également représentées. Ce que nous souhaitons voir à partir de ces premières données, ce sont les catégories qui sont concernées par les adaptations, avec le postulat que les plus représentées sont celles qui sont les plus sujettes aux adaptations.
Pour pouvoir évaluer et identifier les adaptations, nous avons proposé de mettre en place une nouvelle étape, non mentionnée par Mackey, et qui nous paraît spécifique et indispensable dans un cas de situation de contact de systèmes proches 143 . Cette étape consistait à attribuer de façon systématique à tous les élements du corpus relevés un degré de distance marquant la différence ou la similitude des formes entre les deux systèmes linguistiques. Autrement dit, en partant des similitudes mais aussi des différences exposées en langue, entre l’arménien oriental et l’arménien occidental, nous sommes parvenue à établir, pour chaque catégorie morpho-syntaxique étudiée, différents degrés de distance entre les deux variantes. Ces degrés déterminent sur une échelle d’un côté les formes et sens totalement communs aux deux variantes, et de l’autre, les formes différentes pour des sens identiques. Entre ces deux extrémités, réside un certain nombre de degrés, selon la catégorie morpho-syntaxique dans laquelle nous nous plaçons.
Toutes les catégories incarnées par les différentes formes du corpus 144 ont au moins un degré de distance commun, il s’agit du degré de distance nul, existant entre la variante orientale et la variante occidentale, que nous avons appelé degré 1. Ceci veut tout simplement dire que les éléments relevés et portant le degré de distance 1 sont des éléments identiques aux niveaux sémantique et formel (i.e. de la forme) en arménien oriental et en arménien occidental. Ce premier degré de différence (nul) est apparu dans notre présentation des systèmes linguistiques pour catégoriser avant tout les formes verbales ainsi que les formes pronominales qui comptent le plus de variations entre les deux systèmes, mais il nous paraît important de pouvoir utiliser ces échelles proposées pour toutes les catégories présentes dans le corpus. Toutes les formes nominales, pronominales, verbales, etc. qui seront identiques en arménien oriental et en arménien occidental se verront donc marquées du degré de distance 1. Ce marquage a notamment pour but de révéler à quel point les deux systèmes arméniens sont d’un côté identiques et de l’autre, différents, et ainsi de voir quelle part du discours est consacrée aux adaptations. La complexité de cette évaluation réside dans le fait que les degrés de distance que nous avons déterminés permettent de montrer uniquement les différences morpho-syntaxiques et lexicales entre les deux systèmes et ne reflètent pas les différences phonétiques 145 , qui constituent pourtant une autre des divergences majeures attestées entre les deux standards arméniens. Nous avons d’ailleurs décidé de consacrer un traitement particulier à celles-ci, que nous exposerons plus tard. Ce qui signifie donc que pour un même item relevé dans le corpus, nous avons noté à la fois le degré de distance hors phonétique et le degré de distance phonétique.
Les variations de prononciation consonantique ou vocalique bénéficiant donc d’un traitement distinct, nous pouvons en revenir aux autres degrés de distance que nous avons attribués à chaque unité (simple ou complexe) entrée dans le tableau, pour compléter l’étiquetage morpho-syntaxique.
- Degré 1 : c’est le seul qui, dans les deux variantes, soit totalement transcatégoriel, c’est‑à-dire que pour toutes les catégories morpho-syntaxiques recensées, le codage par ce degré-là signifie toujours que la forme et le sens du mot sont identiques en arménien oriental et en arménien occidental. En revanche, à partir du degré supérieur, nous avons développé des nuances plus ou moins fines selon les catégories morphosyntaxiques et les différences attestées en langue.
Toutes les catégories, excepté celles des verbes et des pronoms personnels sur lesquelles nous reviendrons, contiennent des unités qui possèdent deux autres degrés de distance qui sont les suivants :
- Degré 2 : la forme de l’élément concerné est partiellement différente d’une variante à l’autre, mais le sens est identique. Même s’il s’avère que ce degré se manifeste rarement (il existe en langue), nous avons préféré le prévoir pour éviter une simple et stricte dichotomie entre forme identique vs forme différente, pour le même sémantisme. Nous avons prévu une étape intermédiaire qui, sans basculer à une forme totalement divergente, irait tout de même au-delà d’une simple variation phonétique de type consonantique ou vocalique (relevant du degré 1).
Nous avons notamment considéré que relèvent de ce degré 2 les substantifs portant la déclinaison particulière du génitif-datif. En effet, lors de l’exposition des différences au niveau des systèmes nominaux, nous avons établi que dans la déclinaison de la plupart des noms, la forme casuelle du nominatif-accusatif était identique dans les deux variantes arméniennes (degré 1/3), celle du génitif-datif était partiellement différente (identique au singulier mais différente au pluriel) (degré 2/3), et les trois autres (ablatif, instrumental et locatif) étaient complètement différentes (degré 3/3). Nous avons donc établi trois degrés de proximité/distance.
- Degré 3 : ce dernier degré est prévu pour rendre compte des formes qui, cette fois-ci, sont totalement différentes mais conservent un sémantisme identique d’une variante à l’autre. Ce degré concerne par exemple les différences au niveau des déclinaisons nominales (les trois précédemment citées), au niveau de la formation du déterminant article défini, au niveau des formes des pronoms ou d’autres déterminants (essentiellement les pronoms ou déterminants démonstratifs), mais aussi plus simplement, au niveau du lexique qui varie en arménien oriental et en arménien occidental.
Tous les exemples qui figurent dans les catégories comportant trois degrés de distance (entre la variante orientale et la variante occidentale) sont systématiquement classés : 1/3, 2/3, 3/3.
Quant aux systèmes verbaux et aux pronoms personnels, le traitement est plus fin puisque nous leur avons attribué, au moment de la description, deux degrés supplémentaires. Reprenons‑les rapidement.
Pour les pronoms, les systèmes prévoient d’avoir d’une variante à l’autre (cf. Chapitre2, p.75) :
- degré 1 : formes identiques, sens identique,
- degré 2 : formes similaires, sens identique,
- degré 3 : formes identiques, sens différent,
- degré 4 : formes différentes, sens identique,
- degré 5 : formes spécifiques.
Après avoir fait le codage, dans le corpus Pâques, nous ne relevons que des formes appartenant aux degrés 1 et 2, mais nous conservons bien entendu le marquage sur 5.
Quant aux verbes, la totalité des degrés proposés dans le tableau (cf. Chapitre2, p.54) est représentée dans le corpus. Nous avons donc :
- degré 1 : formes identiques, sens identique,
- degré 2 : formes identiques, sens proche,
- degré 3 : formes similaires, sens proche,
- degré 4 : formes identiques, sens différent,
- degré 5 : formes différentes, sens identique.
Nous ajoutons au sein du degré 5 : les formes verbales composées accompagnées du morphème de négation, les formes verbales portant le morphème du causatif (qui est différent en oriental et en occidental), les verbes en -ɛl à l’impératif ainsi que les verbes irréguliers dont la base passé varie à la 3e personne du singulier (cf. tableau récapitulatif Chapitre 2, p.99-100).
Toutes les formes pronominales et verbales concernées porteront donc une marque du degré de distance sur 5 : 1/5, 2/5, 3/5, 4/5, 5/5 146 .
Plus le degré de distance sera élevé, plus les variantes traiteront les phénomènes grammaticaux de façon différente. Ce marquage des degrés de distance nous permet de faire des regroupements en plaçant d’un côté les formes parfaitement communes aux deux variantes, c’est-à-dire celles porteuses du degré 1, et de l’autre, toutes les formes qui peuvent être sujettes aux adaptations, pour ainsi voir les représentativités des unes et des autres au sein d’un corpus entier.
Afin d’étudier les formes concernées par les adaptations, dans le tableau Excel, nous avons doté du degré de distance adéquat (de 1 à 5 maximum) toutes les attestations du corpus. Ensuite, nous avons notamment pu regrouper toutes les attestations porteuses d’adaptations afin de les étudier de plus près et de noter sur quoi portait l’adaptation en question, qu’elle soit réussie ou non.
Une colonne supplémentaire a ainsi été ajoutée pour indiquer, en fonction bien entendu de la catégorie morpho-syntaxique de l’item concerné, à quel niveau intervenait l’adaptation. Les modifications peuvent ainsi porter sur :
- la flexion :
-
- la flexion verbale peut se trouver modifiée, c’est ce qui pourrait se passer si un locuteur cherchait à utiliser une forme verbale qui a un aspect et/ou un sens différent dans la variante voisine ;
- la déclinaison nominale et pronominale peut également être touchée lorsqu’un locuteur renonce à quitter sa variante d’origine pour emprunter ponctuellement celle de son interlocuteur, puisque les cas ne sont pas nécessairement marqués par les mêmes morphèmes d’un standard à l’autre ;
- le lexique : c’est une catégorie particulière, dont la dénomination est volontairement floue, pour qu’elle puisse contenir tous les lexèmes 147 qui peuvent constituer une entrée dans le dictionnaire, entrée qui ne serait pas la même d’une variante à l’autre, malgré un signifié identique ou quasi identique. Nous y retrouvons aussi bien des items lexicaux (noms, verbes, adjectifs) que des items grammaticaux (cas particulier du déterminant article indéfini) ;
- la prononciation : c’est notamment dans cette colonne que nous pouvons apporter l’information indiquant une adaptation au niveau de la strate phonétique, information nouvelle reprise par ailleurs dans le tableau Excel. La distinction est ici faite entre une adaptation modifiant la prononciation vocalique de l’item ou sa prononciation consonantique ou à la fois vocalique et consonantique. Nous y reviendrons plus loin.
Cette nouvelle colonne permet donc d’indiquer ce qui est touché par l’adaptation dans l’item concerné. Il existe, pour le système arménien, cinq possibilités qui sont d’ailleurs parfaitement compatibles entre elles 148 : la flexion verbale, la déclinaison (nominale ou pronominale), le lexique, la prononciation vocalique et la prononciation consonantique. Beaucoup d’adaptations seront mixtes, c’est-à-dire touchant plusieurs strates linguistiques simultanément.
Après avoir relevé toutes les attestations du corpus et avoir approfondi le cas particulier des adaptations, il nous restait encore à traiter la réussite des adaptations tentées. Pour ce faire, nous avons encore ajouté quelques colonnes dans le tableau Excel pour permettre de rendre compte sur quelle strate linguistique portent les adaptations et de coder celles qui sont réussies et celles qui sont non-réussies. Nous avons donc mis en place quatre sous-colonnes permettant d’évaluer la réussite au niveau lexical, morphologique, syntaxique et phonétique des adaptations relevées. Nous avons noté à l’aide d’un système ternaire les phénomènes concernés :
- + : l’adaptation est « réussie »,
- - : l’adaptation est « non-réussie » ou « manquée », c'est-à-dire que l’item obtenu n’est attesté dans aucune des deux variantes,
- ~ : l’adaptation est « partiellement réussie ». Au sein d’une même dimension linguistique, l’adaptation peut n’être qu’approximative, c’est-à-dire que certains éléments appartenant à la variante opposée ont été repris mais d’autres non, ou d’autres l’ont été mais de façon erronée.
Ce codage nous permet notamment de comptabiliser le nombre total d’adaptations non‑réussies et de repérer la ou les strates linguistiques qui sont concernées par ces non-réussites. Ce codage permettra également de confirmer ou d’infirmer l’hypothèse de départ selon laquelle, après comparaison des deux systèmes arméniens, nous suggérons que plus les systèmes sont différents, plus les adaptations sont difficiles à produire et/ou improbables.