2.4.1. Le code-mixing
Le code-mixing, que l’on peut appeler dans notre cas particulier le mélange de glosses, touche 54% des formes adaptées par les différents locuteurs. Plus d’une forme sur deux est donc partiellement adaptée, mais à la différence des précédentes, ces formes sont parfaitement attestées dans une des deux variantes arméniennes.
Voici la répartition de ces mélanges glossiques :
- la plupart des items touchés par le code-mixing contiennent une adaptation complète aux niveaux morphologique et/ou lexical et une non-adaptation ou une adaptation partielle au niveau phonétique.
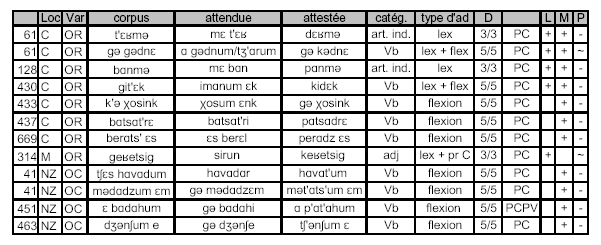
Dans le tableau ci-dessus, nous avons regroupé quelques exemples pour illustrer ce type de code-mixing. Ils sont essentiellement produits par Cathy, locutrice d’arménien oriental, ainsi que par NZ, locuteur d’arménien occidental. Les variations les plus significatives se produisent aux niveaux morphologique et lexical. Dans tous ces exemples, nous voyons bien que Cathy, Martin et NZ ont à chaque fois choisi le morphème ou le lexème spécifiques à la variante-cible, et ce sont ces deux niveaux qui à la fois, paradoxalement, semblent leur demander le plus d’effort tout en étant le mieux maîtrisés.
Amorce d’interprétation : ces deux strates linguistiques sont donc les plus révélatrices des connaissances qu’ils possèdent de la variante opposée. Le fait que les locuteurs aient retenu les caractéristiques morphologiques et lexicales propres au système opposé semble plus valorisant car les divergences à ces niveaux-là sont plus saillantes que des caractéristiques phonétiques portant sur une différence vocalique ou une alternance de voisement au niveau consonantique.
Ces exemples d’adaptation illustrent le phénomène de code-mixing puisque dans les cas présentés ici, les locuteurs conservent à chaque fois la prononciation de leur variante d’origine, et utilisent les caractéristiques morphologiques et/ou lexicales de la variante opposée. C’est en cela qu’on qualifie ces adaptations de partielles, mais ce sont par ailleurs ces formes qui se rapprochent le plus des formes attestées dans la variante opposée.
Le tableau suivant montre d’autres exemples de code-mixing, pour lesquels, cette fois‑ci, la forme relevée se rapproche plus de la forme de la variante d’origine que de celle de la variante‑cible :
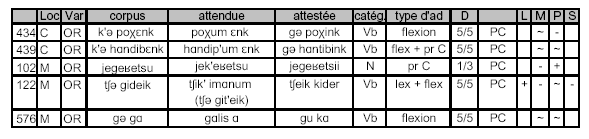
Ces items sont essentiellement produits par Cathy et Martin, donc du côté oriental exclusivement. Dans les cas présentés ici, l’adaptation est incomplète au niveau phonétique (sauf pour le troisième exemple où seule la phonétique est adaptée, et la morphologie flexionnelle conservée), mais surtout, elle est incomplète, voire inexistante au niveau morphologique. Les exemples 1, 2 et 5 représentent des formes verbales qui ont voulu être utilisées par les locuteurs au présent de l’occidental, dans les contextes dans lesquels elles apparaissent. Mais d’une part, le fait que leur adaptation morphologique soit partielle, et d’autre part, le fait qu’il existe une similarité entre le présent de l’occidental et le futur (deuxième forme) de l’oriental, font que nous retrouvons des formes qui sont plus proches de ce qui existe dans la variante orientale que de formes attestées dans la variante occidentale. Ainsi, ces trois exemples particuliers montrent plus des tentatives d’adaptation que des adaptations effectives. On peut penser que Cathy et Martin avaient pour but d’exprimer un temps présent en occidental, ils se sont pour cela éloignés de la forme prototypique de l’oriental (avec Aux-um + BV), mais sans pour autant atteindre la forme de présent réellement attestée en occidental : ils ont utilisé finalement des formes verbales du futur deuxième forme de l’oriental.
Amorce d’interprétation : ceci nous suggère une fois de plus que les locuteurs ne semblent pas avoir conscience de la similarité intra-variante de ces deux temps verbaux.
En produisant donc des formes analytiques telles que k'ə poχɛnk(« nous changeons »), k'ə hɑndibɛnk (« nous rencontrons ») au lieu de gə poχink, gə hɑntibink, les locuteurs ont utilisé, manifestement de façon non intentionnelle, des formes qui existaient dans leur propre système, mais pour exprimer un autre temps. Pour les deux premiers exemples, une des différences supplémentaires qui se présente et qui peut expliquer le caractère incomplet de l’adaptation est le fait que ces formes verbales proviennent de modèles flexionnels différents en oriental et en occidental, modèles que les locuteurs ne maîtrisent pas forcément. En effet, les verbes « changer » et « rencontrer » font partie des verbes en –ɛl en arménien oriental (poχ-ɛl, hɑndip’-ɛl) et des verbes en –il en arménien occidental (poχ-il, hɑntib-il), ce dernier modèle flexionnel étant spécifique de l’occidental. C’est en cela que ces quelques items sont adaptés de façon partielle et se rapprochent cette fois-ci plus de ce qui préexiste dans la variante-source des locuteurs qui les utilisent.
Nous venons de voir des illustrations de deux configurations que nous avons présentées dans notre cadre théorique. La première série d’exemples montrait des cas de ce que nous avons appelé code-mixing à dominante langue-cible et la seconde série d’exemples illustrait des cas de code-mixing à dominante langue-source. Le but était ici de signifier qu’il était prudent de placer tous ces exemples non pas dans des catégories strictes et isolées les unes des autres, mais sur un continuum montrant le degré de variabilité des dialectes en contact et surtout leur degré de perméabilité.
Tous les exemples de code-mixing présentés ici correspondent à des items hybrides qui n’appartiennent ni à la variante orientale, ni à la variante occidentale. Nous obtenons ainsi des formes que nous pourrions qualifier d’« interdialectales », si nous suivons la terminologie proposée par Trudgill (1986) et inspirée par les études sur l’« interlangue » qui peut apparaître dans l’acquisition d’une langue seconde 158 . Souvent ce concept d’interlangue représente des formes simplifiées, présentes dans aucune des deux langues dont elles sont originaires. Mais cette notion de simplification n’apparaît pas réellement dans nos données. Les formes hybrides ou incomplètes, autrement dit interdialectales, produites, ne montrent pas une simplification de l’un ou l’autre des systèmes dont elles proviennent. Elles montrent une fusion de certains éléments, les locuteurs conservant dans leur propre dialecte les éléments les plus difficiles à modifier et adaptant les éléments du système voisin les plus saillants. Ce sont des sortes de formes « émergentes », ou « opportunistes » qui apparaissent dans une situation de contact spécifique et qui n’ont que peu de chances de se stabiliser. Elles sont éphémères.
Amorce d’interprétation : notre objet d’étude, en isolant un cas particulier de code-mixing appelé le mélange de glosses 159 , permet de problématiser la notion de « grammaire-en-interaction ». A quel point les formes normées correspondent-elles à celles réellement actualisées en discours ? Les exemples de mélange de glosses montrent qu’une utilisation personnalisée des systèmes par les locuteurs révèle un certain degré de perméabilité entre ces systèmes qui n’est pas attendu en langue. Cette instabilité n’est pas perceptible en langue et n’est par ailleurs pas forcément perçue par les locuteurs qui font usage des deux codes. En effet, selon les représentations langagières et les compétences qu’ils ont de leur propre code et du code opposé, ils ne seront pas toujours sensibles à ce degré de perméabilité. L’exemple des formes verbales employées dans le but d’exprimer un présent occidental (qui n’est autre qu’un futur oriental) en face d’un locuteur concerné par un tel effort d’adaptation montre bien le décalage qui existe entre la perception des systèmes par les locuteurs, l’utilisation qu’ils en font et la réalité attestée et décrite en langue.