1. Pour la connaissance de la variation en arménien
Le travail mené ici contribue à enrichir les études de dialectologie arménienne, parce qu’en prenant pour point de départ les deux standards arméniens, il s’est intéressé aux pratiques langagières des locuteurs, à leurs dialectes d’origine et à leurs idiolectes construits dans et par la situation de contact. Cette problématique est promise à un avenir certain, sachant que les situations de contact entre les deux variantes d’arménien sont de plus en plus fréquentes et sont amenées à perdurer et ce, pour deux raisons principales :
- elles sont amenées par la dispersion des Arméniens dans une diaspora implantée sur tous les continents : dans les différents pays d’accueil, des locuteurs arméniens d’origines diverses communiquent ensemble, ce qui fait que les cas où les multiples dialectes entrent en contact sont de plus en plus nombreux ;
- elles sont également amenées par le développement du tourisme en Arménie depuis une dizaine d’année, après la chute de l’Union Soviétique. Les locuteurs OCC de la diaspora sont attirés par l’Arménie et font un « retour » aux sources en allant visiter le pays et en rencontrant les locuteurs locaux. Précisons qu’il ne s’agit pas d’un retour au sens strict, puisque, hormis la vague de migration la plus récente, les Arméniens de la diaspora ne sont pas originaires d’Arménie, mais des régions orientales de Turquie et/ou d’un autre pays d’accueil. Les touristes « arméniens » se rendent donc dans un pays qu’ils ne connaissent pas, qui n’est leur terre d’origine que par procuration, le seul territoire, qui est véritablement considéré comme arménien, auquel ils peuvent s’identifier et où ils peuvent (re)trouver leurs racines.
Notre travail illustre un cas particulier de la première configuration : des locuteurs issus de vagues de migration différentes habitent en France, à Lyon, et se rencontrent régulièrement. Le cas envisagé ici connaît une histoire et une évolution particulières. Aussi, son étude est utile pour la dialectologie arménienne, mais le facteur individuel se révélant très important, il conviendra de rester prudent quant aux généralisations que nous pourrions être amenée à faire à partir de ce corpus pour traiter d’autres situations de contact de dialectes en diaspora.
‘Les langues de diaspora, du fait de la dispersion d’une part, de l’absence d’instance normalisatrice centrale de l’autre, connaissent un éclatement de la norme, et une multiplicité de variantes au statut incertain, et dont le morcellement peut conduire jusqu’à l’idiolecte. Cela entraîne un rapport tantôt distendu, tantôt conflictuel entre une multiplicité de pratiques linguistiques observables en situation et souvent divergentes, et leur difficile totalisation dans une langue commune. (Donabédian, 2001 : 15)’Au stade initial de ce travail, nous avons proposé une grammaire contrastive non exhaustive de l’arménien oriental et de l’arménien occidental, indispensable pour parvenir à mettre en avant les points communs et les divergences que comportaient les deux systèmes linguistiques proches auxquels nous nous sommes intéressée, aux niveaux phonétique, morpho-syntaxique et sémantico-lexical. Pour notre étude, ce sont bien entendu les différences qui ont attiré notre attention, et nous les avons reprises sous forme de tableaux (cf. p.54, 59, 75).
Le traitement global des données que nous avons effectué lors de l’analyse quantitative, nous a permis d’obtenir des résultats préliminaires reflétant dès le départ l’interaction qui existe entre ces deux systèmes linguistiques proches. Nous proposons dans les pages qui suivent une synthèse des résultats les plus importants.


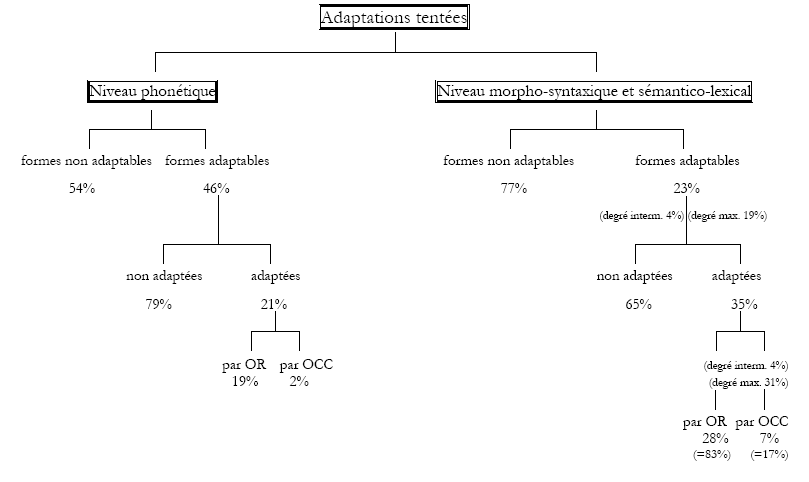
L’étude statistique a mis en avant le fait que plus d’un item sur deux tirés du corpus (56%, soit 605 items sur 1068), toutes dimensions linguistiques confondues, avait des propriétés formelles le rendant sujet à des adaptations. Notre étude a donc porté sur cet ensemble d’items et non sur les formes qui étaient en tout point identiques entre les deux variantes, ce qui nous fournit une base de départ d’items différents importante (les 44% restants) pour le travail d’analyse.
Cette base se réduit toutefois (de 44% à 23%) lorsqu’on met de côté les différences phonétiques et qu’on ne prend plus en considération que les niveaux morpho-syntaxique et sémantico-lexical. Le nombre d’items identiques passe à 77% de la totalité des formes observées dans le corpus. La conclusion à ce niveau-là est que nous avons la preuve en discours d’être face à des systèmes linguistiques extrêmement proches. Ce pourcentage est beaucoup plus élevé que le précédent (56%) parce que nous avons délibérément traité séparément les différences apparaissant au niveau phonétique. Si nous tentions, malgré les difficultés, de les hiérarchiser, les différences phonétiques apparaîtraient certes comme les plus fréquentes puisque la plupart des items contiennent des segments consonantiques ou vocaliques qui peuvent varier, mais très certainement comme celles qui gêneraient le moins la compréhension. Les locuteurs ont tout au plus des « accents » différents, qui seraient difficiles à reproduire d’un point de vue articulatoire, mais qui n’empêchent pas l’intercompréhension. En effet, pour les consonnes, si nous nous appuyons sur l’impression des locuteurs selon laquelle les systèmes se contentent d’inverser le trait de voisement des occlusives et affriquées (les consonnes voisées d’une variante correspondant aux consonnes non voisées de l’autre variante), et non plus sur la répartition plus complexe telle qu’elle a été décrite au niveau des systèmes (et qui met en jeu les traits secondaires de glottalisation et d’aspiration), la compréhension ne semble que peu affectée. Bien entendu, il existe un certain nombre de paires de mots qui, de par la différence de prononciation, auront des sens complètement différents d’une variante à l’autre, mais ces cas sont relativement peu nombreux, et ne sont donc pas les plus gênants pour la compréhension. De plus, dans de tels cas d’ambiguïté orale, le contexte peut largement aider à lever toute source de malentendu potentiel.
Exemple de malentendu potentiel : պատ⇒ ce mot est prononcé [p’at’] en arménien oriental et [bad] en arménien occidental, et signifie « mur », les consonnes occlusives non voisées et voisées sont simplement inversées d’une variante à l’autre. Mais la prononciation occidentale telle qu’elle apparaît ici correspond alors à un tout autre mot en arménien oriental, cette fois-ci écrit բադet prononcé donc [bad] en oriental et [pad] en occidental, et qui signifie « canard ». Mais bien entendu la plupart du temps, le contexte permettra de savoir si un locuteur parle d’un mur ou d’un canard !
Hormis ces cas particuliers, la prononciation consonantique portant sur l’inversion de voisement ne semble pas freiner ou handicaper la compréhension mutuelle des locuteurs. Il en va de même pour la prononciation vocalique. Cette dernière se différencie d’une variante à l’autre uniquement pour trois voyelles concernant leurs lieux d’articulation et leurs apertures. La différence est dialectale, stylistique ou lexicale selon le point de vue adopté (expert vs profane), mais ne gêne là non plus en rien la compréhension et l’identification des items émis par les locuteurs de variante opposée. Les chiffres suivants ont d’ailleurs le mérite de le confirmer.
En regroupant les segments consonantiques et vocaliques sujets à variation, il s’est avéré que sur la totalité des items du corpus, 46% sont potentiellement adaptables, c'est-à-dire qu’ils contiennent des phonèmes dont les réalisations diffèrent selon qu’ils sont émis par des locuteurs d’arménien oriental ou des locuteurs d’arménien occidental. Cette strate linguistique est de loin la plus fournie en possibilités d’adaptations. Mais parmi ces items, 21% seulement sont effectivement adaptés par les divers locuteurs, et donc 79% ne le sont pas. Ce dernier chiffre est conséquent et montre la difficulté ou la non-sensibilité que rencontrent les locuteurs pas tant en perception 184 (il paraît clair en tout cas chez les locuteurs OR qu’ils entendent la distinction binaire et réduite : consonnes occlusives et affriquées voisées vs non voisées), qu’en production. En effet, quand bien même ils distinguent à l’écoute les différences phonétiques portées par certains mots, ils ne s’approprient que rarement le système phonétique de leurs interlocuteurs, tout simplement parce qu’ils ne possèdent peut-être pas les capacités articulatoires acquises et non « naturelles » pour le reproduire. La strate phonétique se distingue alors des autres strates linguistiques car c’est la seule qui nécessite un investissement physique de la part des locuteurs, ce qui peut éventuellement constituer une barrière à l’adaptation. En effet, les efforts articulatoires qu’il faut produire peuvent aboutir à une forme d’hypercorrection qui peut être perçue comme une caricature moqueuse du système de l’autre, aussi bien pour l’émetteur que le récepteur. Quoi qu’il en soit, cette étude nous permet de nous rendre compte du décalage qui existe entre la perception pouvant être reprise à huis clos sous forme caricaturale (lors d’entretiens avec les locuteurs OR qui nous expliquaient, en les imitant, la prononciation de leurs partenaires OCC) et la production effective face à des locuteurs dont c’est la prononciation d’origine et qu’il faut éviter de « froisser » en usant de la caricature ou en abusant de « règles » phonétiques approximatives ou erronées. Il reste toutefois difficile de savoir si ce non-emploi reflète une difficulté de la part de certains locuteurs, un manque de sensibilité dans la perception systématique ou plus simplement une non-nécessité de s’adapter sur cette strate-là, la compréhension n’en paraissant pas altérée. Quoi qu’il en soit, ces premiers résultats offrent déjà des pistes intéressantes pour la vérification de la première hypothèse émise au niveau phonétique, que les résultats suivants vont permettre de confirmer.
Au niveau phonético-phonologique, nous sommes partie du postulat que le système le plus complexe englobait le système le moins complexe. En transposant ce principe au niveau des locuteurs, cela traduisait l’idée que les locuteurs d’arménien oriental (qui possèdent le système consonantique le plus riche, à distinction ternaire) auraient plus de facilité à utiliser un système consonantique simplifié (binaire) qui est celui de l’arménien occidental. A l’inverse, les locuteurs d’arménien occidental auraient plus de difficultés à produire des formes qui ne font pas partie de leur système. Autrement dit, à ce niveau-là, les locuteurs d’arménien oriental ont, d’un point de vue articulatoire, plus de possibilités pour produire les sons appartenant au système occidental que l’inverse. Cette hypothèse a pu être vérifée dans nos données grâce à l’analyse quantitative que nous avons menée. Nous en avons d’ailleurs profité pour élargir l’étude de la prononciation en nous intéressant non seulement aux productions consonantiques, mais également aux productions vocaliques. Ces dernières étaient tout aussi complexes à analyser. Parmi les 21% de formes phonétiquement adaptées, la plupart sont émises par des locuteurs OR. En effet, 88% des formes phonétiquement adaptées sont adaptées par les locuteurs OR vs 12% par le seul locuteur OCC (qui s’adapte). Ces chiffres seraient encore plus accentués dans les autres corpus. Par exemple dans les sous-corpus Anna et Prêtre, les locuteurs OCC ne produisent aucune adaptation phonétique, là où les mêmes locuteurs OR continuent d’en produire régulièrement. Ceci peut donc confirmer le fait que les locuteurs OR, ayant un système phonologique plus riche que les locuteurs OCC, ont plus de possibilités et produisent donc plus de segments phonétiques appartenant au système occidental. Ces chiffres sont tout de même à interpréter avec prudence parce qu’ils continuent de regrouper les segments consonantiques et vocaliques qui ne sont pas traités de la même manière, mais également parce que les adaptations consonantiques sont proportionnellement moins fréquentes que les adaptations vocaliques. Ceci étant dit, le système vocalique de l’arménien oriental (au-moins pour les trois voyelles qui nous intéressent particulièrement et qui sont sujettes à variation) apparaît là encore plus riche que le système occidental, de par la variation dialectale (ɛ/ɑ, amenée par la présence du ɑ) présente sur certains items qui n’est pas prévue en arménien occidental (qui ne compte que la première des deux formes). Notre conclusion est donc toujours valable : le système phonétique (consonantique ou vocalique) des locuteurs OR est plus fourni que celui des locuteurs OCC et leur permet d’avoir recours dans certains cas à des adaptations sur des segments consonantiques ou vocaliques qu’ils ont repérés dans la variante occidentale. Le système phonétique des locuteurs OCC étant plus réduit, il ne leur permet pas d’avoir la même sensibilité de perception et de production. A cela il faut ajouter un facteur sociolinguistique important que nous avons déjà signalé et qui permet d’expliquer ce phénomène : parmi les deux groupes de locuteurs (sur lesquels porte cette étude), le groupe OR a dès le départ été plus soumis à la variante occidentale que l’inverse. Finalement, si l’on regarde comment se situent les différents protagonistes par rapport au système voisin, les locuteurs OCC se trouvent concernés par le phénomène décrit par Weinreich (1974) de sous-différenciation de phonèmes (under-differentiation of phonemes), c'est-à-dire qu’ils ne parviennent pas à distinguer et donc neutralisent des phonèmes qui ne sont pas présents dans leur système :
‘Under-differentiation of phonemes occurs when two sounds of the secondary system whose counterparts are not distinguished in the primary system are confused. (Weinreich, 1953: 18)’Quant aux locuteurs OR, ils se trouvent à l’inverse en position de sur-differenciation de phonèmes (over-differentiation of phonemes), c'est-à-dire qu’ils conservent le surplus de distinctions existant dans leur système et le reportent sur le système voisin. Qu’il s’agisse de l’une ou l’autre des configurations, si l’on exclut les adaptations réussies (66% de la totalité des adaptations phonétiques), partielles (14%) et les hypercorrectismes (20%), les deux types de locuteurs conservent la plupart du temps (dans 79% des cas) la prononciation originelle de leur variante‑source. Autrement dit, les adaptations porteront sur d’autres variables.
Pour les niveaux morphologique et sémantico-lexical, lors de la comparaison des deux systèmes arméniens, nous avions émis une deuxième hypothèse suggérant que plus le degré de distance entre les items étudiés serait élevé, moins les adaptations seraient probables, car trop difficiles à produire. Pour vérifier cette hypothèse, nous avons proposé de mettre en place une méthodologie originale qui consistait à établir des degrés de distance à attribuer aux items étudiés, pour estimer à quel point les formes étaient différentes les unes des autres d’une variante à une autre. Dans le sous-corpus étudié, à ces niveaux-là, nous avons vu que 77% du matériau était commun (donc degré de distance nul) et 23% était sujet à adaptation 185 . Parmi ces 23%, la plupart des formes relèvent du degré de distance maximum et 65% de ces formes ne sont pas adaptées, 4% des formes de degré intermédiaire sont adaptées et 31% des formes de degré maximum sont adaptées. Mis à part le fait que les adaptations ne sont pas extrêmement fréquentes, nous constatons qu’elles existent bien et surtout que la plupart d’entre elles sont des formes qui sont marquées du degré de distance le plus fort. Notre hypothèse de départ sur les degrés de distance s’est ainsi vue infirmée puisqu’il s’avère que les adaptations morphologiques (et lexicales) se produisent au niveau du degré de distance le plus fort. Autrement dit, la tendance est certes aux non-adaptations, mais parmi les formes adaptées, ce sont les formes les plus différentes d’une variante à l’autre qui sont adaptées par les locuteurs.
Concernant les taux de réussite des adaptations à ces niveaux-là, nous avons également rapporté des résultats intéressants : tout d’abord, 72% des adaptations morphologiques sont réussies et elles sont toutes marquées du degré de distance maximum (5/5). Ensuite, 100% des adaptations lexicales sont réussies et sont, là encore, toutes issues du degré de distance le plus élevé. Enfin, sur toutes les adaptations morphologiques et lexicales, 83% sont tentées par les (deux) locuteurs OR et 17% par le locuteur OCC. Autrement dit, il est intéressant de constater que sur ces strates-là, pour lesquelles nous n’avions pas formulé d’hypothèses à partir des systèmes linguistiques mais uniquement une hypothèse beaucoup plus générale au niveau socio‑historique, les locuteurs OR sont une nouvelle fois ceux qui font le plus de tentatives d’adaptations.
Cette étude quantitative n’aurait pas été complète si nous n’avions pas cherché à savoir d’une part, quelles sont les catégories morphosyntaxiques les plus touchées par les adaptations et d’autre part, quels sont les types d’adaptations qui sont le plus tentés par les locuteurs OR et OCC. En ce qui concerne la première question, il apparaît très nettement que la catégorie des verbes est de loin la plus touchée par les adaptations : 59% des adaptations portent sur des verbes vs 8% sur des noms, 7% sur des pronoms, les autres catégories représentant entre 1% et 6% des adaptations. Un premier élément de réponse pouvant expliquer cette tendance est le fait que cette catégorie des verbes apparaît comme étant la plus représentée dans le corpus (23%), donc la plus susceptible d’être soumise aux adaptations, d’un point de vue purement statistique. Mais ce phénomène n’est pas suffisant en soi, car l’écart de représentativité par rapport aux autres catégories morphosyntaxiques n’est pas très grand. Ainsi, rappelons simplement que les substantifs, les adverbes et assimilés ainsi que les items français sont aussi relativement bien représentés dans le corpus (respectivement 19%, 16% et 15%). Le deuxième élément de réponse à proposer, qui paraît plus pertinent, est le fait que les verbes contiennent des éléments adaptables qui sont manifestement plus accessibles aux locuteurs. Ainsi, une fois de plus, nous mettons les variations de prononciation de côté, celles-ci n’ayant aucune raison d’être plus faciles à produire sur un verbe que sur un nom (c'est-à-dire n’ayant aucune raison d’être privilégiées par la catégorie morphosyntaxique d’appartenance). Il nous reste alors à regarder ce qui se passe aux niveaux morphologique et lexical. Il s’avère que l’écart se creuse non pas au niveau lexical (les bases nominales sont d’ailleurs plus sujettes aux adaptations lexicales que les bases verbales 186 ), mais au niveau morphologique, ce qui signifie que la morphologie verbale est plus accessible aux locuteurs adaptants que la morphologie nominale ou pronominale. Autrement dit, les locuteurs semblent mieux connaître, mieux maîtriser les adaptations morphologiques qui se déroulent au niveau des verbes que celles se produisant au niveau des noms ou des pronoms. Ce qui irait dans le sens de ce que suggère Weinreich (1953 : 34) :
‘Other things being equal, and cultural considerations apart, morphemes with complex grammatical functions seem to be less likely to be transferred by the bilingual than those with simpler functions.’Il semble ainsi plus facile et plus accessible pour un locuteur adaptant de repérer et d’assimiler un morphème verbal exprimant un temps présent par exemple, qu’un morphème nominal représentant une marque casuelle telle que celle de l’ablatif. Cette dernière demande une maîtrise plus profonde et plus détaillée du système. Une seconde interprétation possible porterait sur une différence de visibilité des traits spécifiques. C'est-à-dire que sans être nécéssairement plus facile d’accès, le morphème de TAM peut apparaître, pour un locuteur, comme une différence emblématique plus forte qu’un morphème casuel. Nous reviendrons, à propos du troisième axe de recherche, sur la valeur métalinguistique des adaptations de ce type.
Il est délicat de faire une comparaison, mais cette tendance reste malgré tout valable bien que la morphologie verbale paraisse plus riche (donc plus sujette à adaptation) que la morphologie nominale (il y a par exemple en système plus de morphèmes de TAM que de marques casuelles), parce que la première, malgré ses possibilités, n’est exploitée que très partiellement par les locuteurs (il n’y a à peu de choses près que le degré commun et le degré maximum de distance qui sont exploités). Donc au moins au niveau morphologique, nous pouvons dire que le verbe se trouve être la catégorie la plus soumise aux adaptations. C’est probablement à ce niveau-là que les différences entre les deux variantes sont les plus visibles (parce qu’elles sont dotées du degré de distance le plus fort) donc les plus facilement repérées par les locuteurs adaptants, en tout cas, plus facilement que pour les noms et les pronoms par exemple. En poussant l’analyse encore plus loin et en regardant ce qui se passait au niveau des temps verbaux, un phénomène intéressant est apparu. Les trois temps et modes les plus utilisés par l’ensemble des locuteurs (du sous-corpus Pâques) sont le présent de l’indicatif, le passé narratif et le subjonctif présent. Le passé narratif et le subjonctif présent sont mis de côté étant donné qu’ils possèdent une forme identique en arménien oriental et en arménien occidental (degré 1/5). En revanche, l’utilisation qui est faite du présent de l’indicatif est très révélatrice. Rappelons simplement que ce temps est marqué du degré de distance le plus élevé, c'est-à-dire que les deux variantes proposent deux constructions morphosyntaxiques complètement différentes pour exprimer cette même valeur temporelle. La moitié des formes verbales de NZ (locuteur OCC) au présent est formulée avec le morphème occidental et l’autre moitié avec le morphème oriental (sur les 13 adaptations concernées, toutes sont réussies). Ces chiffres sont déjà intéressants à étudier, mais les données suivantes le sont davantage. Martin (locuteur OR) produit plus de formes verbales au présent occidental (66%) qu’au présent oriental. Enfin, 100% des formes verbales au présent de Cathy (locuteur OR) sont produites avec le morphème spécifique à la variante occidentale. Cet exemple illustre bien la capacité de ces locuteurs à adopter la morphologie verbale, qui plus est la plus différente, de la variante opposée, allant même jusqu’à ne se servir que de celle-ci.
La seconde question portant sur les types d’adaptations va de pair avec la précédente, mais est moins précise. Ainsi, même si les données ne sont pas comparables entre les locuteurs des deux variantes parce que les adaptations sont beaucoup moins fréquentes du côté occidental que du côté oriental 187 , nous nous sommes rendue compte que les types d’adaptations employés par les uns et par les autres étaient assez semblables. Voici les résultats sous forme de tableau comparatif :
| Types d’adaptations | Locuteurs OR | Locuteur(s) OCC |
| Prononciation vocalique (PV) | 26% | 31% |
| Prononciation consonantique (PC) | 23% | 5% |
| Flexion | 16% | 22% |
| Lexique | 14% | 18% |
| Adaptations multi-strates | 24% | 14% |
L’écart le plus important entre les locuteurs des deux variantes se situe au niveau de la prononciation consonantique et ne vient que renforcer une nouvelle fois ce que nous avons exposé précédemment : les locuteurs OR produisent plus d’adaptations phonétiques au niveau consonantique que les locuteurs OCC. Le reste de l’étude « comparative » (qui n’en est pas réellement une) montre des écarts beaucoup moins importants pour les autres types d’adaptations. Ce qui signifie que les locuteurs adaptants exploitent à peu près (de façon croisée) les mêmes possibilités d’adaptations de part et d’autre. Autrement dit, ils ont recours pratiquement aux mêmes phénomènes, candidats aux adaptations, que les systèmes linguistiques opposés offrent dans chacune des variantes. Les systèmes prévoient donc des adaptations parfaitement possibles, d’un point de vue structurel, des deux côtés, et il s’avère que ce sont, à peu de choses près, les mêmes potentialités qui sont exploitées par les locuteurs. Enfin, il est important de noter que la plupart du temps, les morphèmes adaptables (qu’il s’agisse de morphèmes libres ou liés) sont interchangeables d’une variante à l’autre, c'est-à-dire que presque chaque morphème potentiellement adaptable possède son équivalent dans le système voisin. Donc la plupart du temps, le morphème d’un système remplace tout simplement celui de l’autre système, il ne vient pas enrichir ce système qui n’en serait pas déjà pourvu 188 .
La constitution d’un corpus et son exploitation nous ont permis de comprendre comment les systèmes se manifestent en discours et les possibilités offertes aux locuteurs qui les utilisent. Nous sommes parvenue à dégager certains types de fonctionnement qu’il serait intéressant de confirmer à l’aide d’autres travaux, mais une des véritables richesses d’une telle étude appuyée sur un corpus est l’aboutissement à des contradictions ou en tout cas à des réévaluations par rapport aux prédictions (en système) de départ. La réévalutation la plus originale porte sur l’effet de la distance (en morphologie et dans le lexique), pour lequel nous avons vu que finalement les formes les plus différentes étaient celles qui étaient les plus sujettes aux adaptations et les plus adaptées. Un deuxième apport grâce au corpus concerne, comme nous le verrons plus loin, les théories de la linguistique de contact qui s’appliquent traditionnellement aux systèmes éloignés en contact mais ne se réalisent pas nécessairement de la même manière dans des cas de systèmes proches en contact. Cela étant dit, comme tout corpus, le nôtre ne peut prétendre à une représentativité absolue, et nous n’excluons pas que les généralités que nous en avons tirées puissent être contredites par d’autres données.