2. Modèles de lecture « à double voie »
2.1. Modèle à Double Voie en Cascade
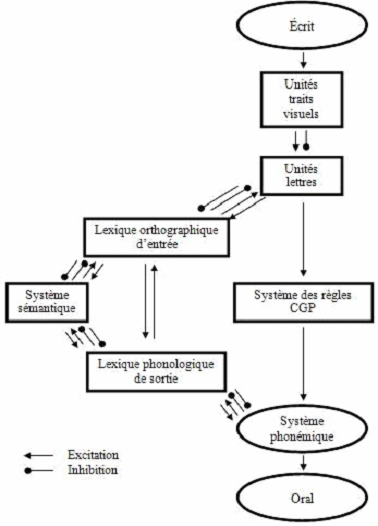
Le modèle cognitiviste de référence, classique, de la Double Voie (Coltheart, 1978) assume que la reconnaissance visuelle de mots isolés (et leur prononciation) s’effectue selon deux voies distinctes de traitement, activées parallèlement. Succinctement, la récupération des informations peut se concevoir soit par adressage, c’est-à-dire par appariement direct entre la représentation phonologique et la représentation orthographique dans le lexique mental, soit par assemblage, c’est-à-dire par segmentation de la représentation orthographique pour construire la représentation phonologique. Dans le premier cas, on parle de voie directe lexicale (ou de phonologie adressée) alors que dans le deuxième cas, on parle de voie indirecte prélexicale (ou de phonologie assemblée). En lecture silencieuse, le modèle décrit la voie indirecte comme la voie lente utilisée pour la mise en correspondances des graphèmes et des phonèmes, voire d’unités plus larges, mais aussi pour traiter les mots longs ou peu fréquents. En revanche, la voie directe est considérée comme la voie rapide requise pour le traitement des mots courts et fréquents.
Ici, nous allons plutôt nous intéresser à la version implémentée de ce modèle (Figure 4) en abordant le modèle connexionniste de la Double Voie en Cascade 9 (i.e., Dual Route Cascade, DRC, Coltheart, Curtis, Atkins & Haller, 1993 ; Coltheart, Rastle, Perry, Langdon & Ziegler, 2001). Ce modèle permet de simuler la lecture à voix haute et silencieuse de mots monosyllabiques de huit lettres au maximum dans les langues alphabétiques (i.e., ici, le cas de l’anglais). Il est aussi capable d’apprendre progressivement des règles de correspondances graphème-phonème (i.e., CGP) sur la base des mots proposés. Dans le DRC, l’information se propage en cascade d’un niveau à l’autre (i.e., ou plutôt d’un module à l’autre) à partir de représentations symboliques locales (e.g., traits, lettres, phonèmes…). La voie lexicale accède ainsi à la forme stockée en mémoire grâce à des liens bidirectionnels d’activation et d’inhibition graduels. Par contre, la voie prélexicale n’opère que des activations unidirectionnelles. Pour Coltheart et al. (1993 ; 2001), quelle que soit l’entrée visuelle, les deux voies s’activent simultanément et parallèlement avant de converger vers le module de sortie (i.e., le système phonémique). Alors que la voie lexicale effectue un traitement parallèle de toutes les lettres, la voie prélexicale traite les lettres séquentiellement, de gauche à droite. L’avantage de ce modèle est de simuler correctement la lecture de mots à pratiquement 99.99% et de ne faire que 1.07% d’erreurs sur des pseudomots. Le DRC simule également les effets traditionnels de fréquence, de régularité, de pseudohomophonie ou de taille du voisinage lexical et non lexical. Toutefois, ce modèle ne simule pas l’apprentissage de la lecture, il offre plutôt un cadre explicatif aux mécanismes de mise en place d’un système de lecture.