III.2.4.3. Analyses statistiques – Tâche I : génération de mots
Les analyses statistique événementielle ont été menées en accord avec le modèle linéaire général (GLM, «General Linear Model», Josephs, Turner & Friston, 1997) et en utilisant la fonction de réponse hémodynamique (HRF, « Hemodynamic Response Function ») fournie par SPM5.
A un premier niveau de l’analyse statistique, les données individuelles ont été modélisées par un modèle à effet fixe. Nous avons défini deux types d’événement – génération de mots et répétition de « roro ». Une fonction « box-car » 4 correspondant à l’instant et la durée d’apparition des stimuli est convolué avec la HRF pour estimer le signal BOLD. Dans le domaine temporal, un filtre passe-haut fourni par défaut par SPM (1/128 Hz) a été appliqué pour éliminer les artéfacts dus aux variations lentes d’origine physiologique (e.g. battements cardiaques et respiration) ainsi qu’un filtre passe-bas (la fonction de HRF) pour contrôler l’auto-corrélation temporale du signal.
Pour chaque sujet, l’index de latéralisation (LI, « lateralization index ») de l’activité dans le gyrus frontal inférieur (pars triangularis et pars opercularis ; selon « automated anatomical labeling (AAL) », (Tzourio-Mazoyer et al., 2002)) est calculé pour le contraste génération de mot vs. répétition de « roro ».
Tenant compte de la variance entre les sujets, les LIs étaient calculés sur les valeurs des voxels activés à une série de seuils de significativité variables dans les cartes SPM-T du contraste (i.e. la combinaison linéaire) en question intéressé (Wilke and Schmithorst, 2006 ; Jansen et al., 2006b ; Deblaere et al., 2004). Une carte T est calculée en divisant une carte « con » (« con » pour contraste) par sa erreur standard, et une carte « con » est calculée en appliquant une combinaison linéaire (dit un contraste) sur une carte β. Une carte β comporte l’estimation des paramètres qui indiquent dans quelle mesure les formes d’onde s’adaptent aux données d’IRMf obtenues à chaque voxel. Les valeurs T (dans une carte T) ainsi que les valeurs β pondérés (dans une carte « con ») sont souvent utilisés pour décrire l’ampleur du changement du signal. Si sur le plan de la robustesse et de la reproductibilité les deux approches donnent les résultats similaires, les valeurs T comportent de plus les effets de la variance du signal (Jansen et al., 2006b).
La méthode Bootstrap est répétitivement appliquée (100 fois à gauche et 100 fois à droite, taux de réchantillonnage = 25%) à la carte T pour chaque seuil, dans les régions frontales inférieures. Le terme « Bootstrap » décrit, en statistique, une technique d’inférence statistique basée sur une succession de rééchantillonages. En d’autres termes, plusieurs rééchantillonages sont générés à partir d’un échantillon original dans le but d’estimer une distribution Bootstrap qui permet d’approcher la vraie distribution de l’échantillon original. Pour chaque combinaison de réchantillonages (donc 100 fois 100 combinaisons), un LI est calculé à partir des valeurs de voxels en utilisant le formulaire:
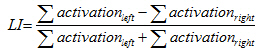
Une moyenne tronquée(25) est ensuite calculée à partir de ces LIs. La moyenne tronquée est un moyenne arithmétique calculée après élimination des valeurs extrêmes, e.g. une moyenne tronquée(25) utilise la moyenne de 50% des données sans prendre en compte les valeurs au dessus des 75% et les valeurs en dessous des 25%.
Ensuite, pour chaque participant, un LI moyenné pondérée est calculée sur la base de tous les LIs (LI moyenné tronquée à chaque seuil), chaque LI étant pondérée par son seuil respectif.
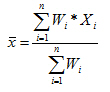
Cette méthode, en combinant la méthode Bootstrap et moyenne tronquée, permet d’améliorer la stabilité de résultats en détectant et limitant les influences des données extrêmes au niveau statistique ou artéfact qui peuvent biaiser le résultat (Wilke and Schmithorst, 2006). Le calcul a été réalisé par LI Toolbox 1.02 (Wilke and Lidzba, 2007 ; et voir Wilke and Schmithorst pour tous les détails de cette méthode étant appliquée à notre étude, 2006).
Les participants présentant un LI>0.5 ont été définis comme « typique » (latéralisé à gauche pour générer les mots), et ceux avec un LI<-0.5 ont été définis comme « atypiques ». Les participants avec un LI entre -0.5 et 0.5 sont été considérés comme « bilatéraux » pour générer les mots.