Transcription de la parole et des aspects multimodaux
Les recherches menées en Analyse Conversationnelle sont réalisées principalement à partir des transcriptions écrites des interactions enregistrées. L’utilisation d’enregistrements vidéo d’activité conversationnelle permet d’élargir le choix quant aux matériaux à transcrire en vue d’une analyse. En effet, nous avons la possibilité de transcrire soit les productions verbales des participants uniquement, soit leurs productions verbales et multimodales (i.e. gestes, regards, postures, déplacements, etc.). Notre problématique de départ s’intéresse aux interactions téléphoniques médiées par ordinateur dans des centres d’appels, c'est-à-dire d’une part, une communication visiophonique par écran interposé ; et d’autre part, une communication téléphonique avec une mobilisation de ressources technologiques (écran, souris, clavier, téléphone) permettant d’avoir accès aux informations essentielles dans l’activité de service. Ces deux situations d’interaction demandent aux participants de réaliser des activités multimodales simultanément à leurs interactions verbales.
Nous avons donc du transcrire nos données d’un point de vue de la parole, mais aussi multimodal pour décrire les actions et les activités, rendues pertinentes par les participants, à l’intérieur de nos analyses. Dans un premier temps, nous avons transcrit la parole des enregistrements vidéo, à l’aide de l’audio extrait, nous avons vérifié le détail des chevauchements et des pauses. Dans un deuxième temps, nous avons transcrit les actions multimodales pertinentes pour les extraits analysés ici. Nous avons repris des conventions de transcription20 adaptées à nos données pour les annotations multimodales en tenant compte des statuts des participants, à savoir en fonction de l’identité conseiller/opérateur ou patient/client. Ces annotations permettent de délimiter le début et la fin d’un geste ou d’un regard d’un des participants, simultanément à un tour de parole ou à un silence.
Exemple :
SAM §sur quelle bornette/§
samG §écrit sur papier §
Voici un tableau récapitulatif des conventions utilisées pour l’annotation des actions multimodales :
| Professionnels | Patients/Clients | 3 ème Participants | |
| Description gestes | § | £ | @ |
| Description regards | + | $ | % |
En plus de l’annotation des gestes et des regards de la part des participants, il est important pour nous de transcrire certaines informations affichées sur l’écran d’ordinateur suite à des actions gérées par la conseillère (HumPrior) ou l’opérateur (LocBike). Ces informations peuvent être pertinentes dans l’interaction de service en cours comme nous le verrons dans les analyses. C’est pourquoi, nous avons décidé d’attribuer une convention de transcription particulière lors de l’annotation d’informations pertinentes affichées sur l’écran, par le signe #.
Enfin, nous avons eu recourt à un outil logiciel pour faciliter la transcription des actions multimodales de certains extraits analysés : le logiciel d’annotations ELAN21. Dans notre pratique, il permet d’annoter le début et la fin d’une action, d’un évènement, d’un regard et de l’aligner temporellement aux tours de parole (le cas échéant). Ainsi, nous pouvons jouer en boucle cette action, évènement ou regard et affiner l’alignement temporel. ELAN a la particularité d’afficher les annotations sous forme de partition (cf. image 8, ci-dessous), chaque ligne correspond à une ligne de participant déclinée en fonction du critère oral, geste, regard, etc. La lecture des annotations se fait horizontalement, de gauche à droite, sur une ligne temporelle correspondant à la durée des extraits vidéo à annoter.
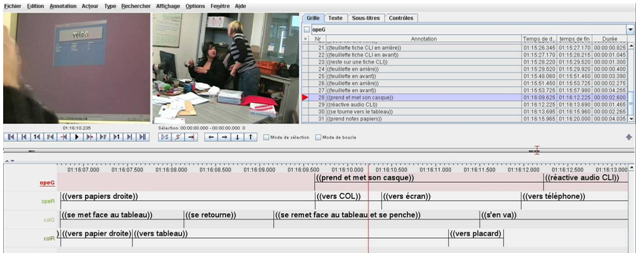
Après avoir annoté les actions avec ELAN, il suffit de reporter ces annotations dans notre transcription en format liste, utilisé pour les analyses présentées ici. Voici le résultat sur la transcription de l’oral en format liste après l’extraction et l’alignement des annotations multimodales réalisées avec ELAN :

Nous avons réalisé nos analyses à partir de ces transcriptions orales et multimodales en associant parfois la description écrite de l’action multimodale à sa capture en image. Ces captures d’écran sont marquées dans la transcription en liste par l’indication « imN » où N correspond au numéro de l’image de façon chronologique pour chaque extrait. Nous avons conservé les conventions utilisées pour l’annotation des actions multimodales décrites dans le tableau 1 ci-dessus, pour préserver l’association entre celui qui produit l’action et sa description écrite. Nous établissons donc la différence entre les légendes « imN » vs. « image N » où imN correspond aux captures d’image d’action multimodale associées temporellement à l’interaction orale, alors qu’image N correspond à des captures d’écran explicatives pour montrer par exemple le contexte de l’interaction dans lequel évoluent les participants ou encore le dispositif technique mobilisé.