Longueurs moyennes d’énoncés
Depuis que R.Brown (1973 : 54) a proposé un calcul simple et standardisé de la longueur moyenne d’énoncé (L.M.E) en morphèmes, qu’il considérait comme un excellent indice du développement grammatical, cette mesure a été reconnue et préférée à l’âge pour comparer des enfants à niveau égal de développement (Brown, 1973 ; de Villiers & de Villiers, 1973). En fait, la L.M.E permet de déterminer le niveau de langage de manière assez fiable (Bernstein & Tiegerman Faber, 1997 ; cf. Parker & Brorson, 2005 : 367), au moins jusqu’à 36 mois (voir par exemple Klee et al., 2004) et son évolution pourrait être l’indice de changements développementaux (Fey, 1986 ; Paul, 200 ; cf. Parker & Brorson, 2005 : 367). Elle ne donne cependant pas d’indication sur le développement linguistique en tant que tel, comme le suggérait Brown : Leonard & Finneran (2003) ont par exemple montré que l’appariement d’enfants dysphasiques avec des enfants contrôles sur la base de la L.M.E en morphèmes était en partie trompeur, car les énoncés constitués du même nombre de morphèmes sont moins riches chez les enfants dysphasiques, qui produisent plus d’inflexions erronées, mais aussi plus de groupes prépositionnels et de formes en –ing que les enfants contrôles. Si elle peut trahir tout autant que traduire le développement grammatical, la L.M.E calculée en morphèmes n’apporte peut-être pas plus qu’un simple découpage de l’énoncés en mots. Pour s’en assurer, des études récentes ont calculé le coefficient de corrélation entre les deux mesures, et montré que le calcul de L.M.E en mots était tout aussi fiable pour des langues dont les marques morphologiques sont relativement peu nombreuses : c’est le cas de l’anglais (Parker & Brorson, 2005) mais aussi du français (Parisse & le Normand, 2006).
Dans l’étude comparative que nous venons de citer, Thordadottir (ibid : 255 & sq.) relève aussi une différence entre longueurs moyennes d’énoncés, à la fois en morphèmes et en mots : celle-ci montre une tendance opposée à la mesure du nombre moyen de mots produits, puisque les enfants francophones produisent en moyenne des énoncés plus longs que les enfants anglophones au même âge.
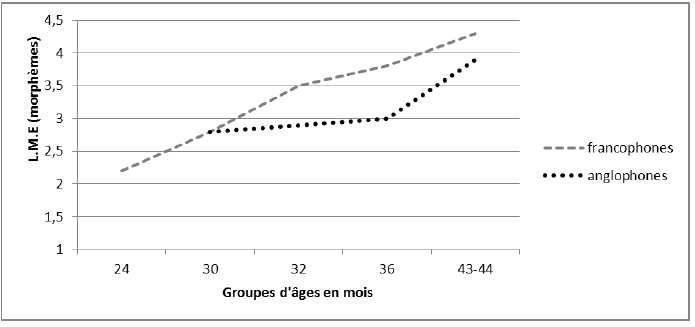
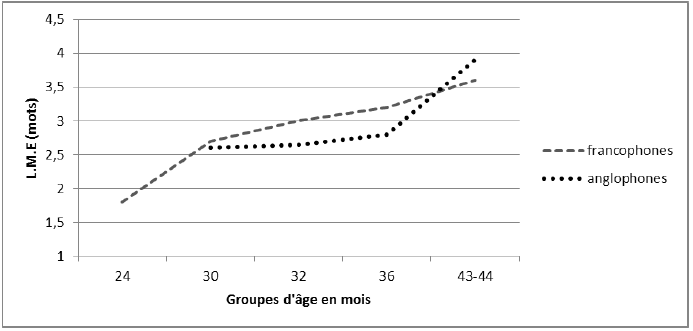
On note cependant que pour la longueur moyenne en mots, la différence est moindre. Or, nous l’avons dit, il existe une très forte corrélation entre l’une et l’autre mesure, en anglais (r = 0,998, p<0,00122) et en français (r = 0,991, p<0,00123). De plus, le calcul en mots présente l’avantage d’être plus rapide et plus fiable, parce qu’il n’est pas tributaire de décisions prises par le chercheur et/ou des catégories de l’analyseur automatique grâce auquel on réalise le découpage en morphèmes : « Counting words is easier, faster, more reliable and theoretically more sound because no ad hoc theoretical decisions need to be made » (Arlam-Rupp et al. 1976 : 233). Nous avons donc calculé les L.M.E en mots pour chacun des enfants de nos corpora, afin d’interroger la comparabilité des données sous cet angle.
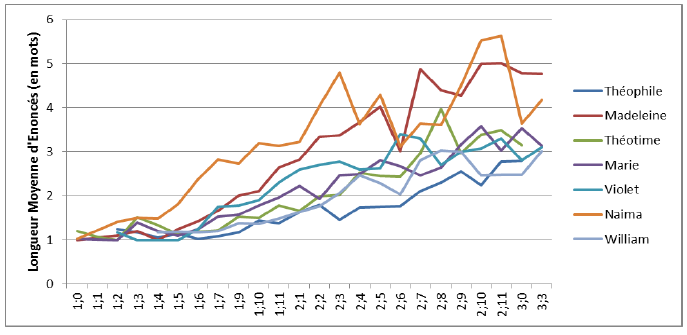
On le voit, les courbes sont dans l’ensemble bien entremêlées, sauf pour Madeleine et Naima. D’autre part, on ne retrouve pas vraiment dans nos données la tendance des enfants français à produire des énoncés plus longs à âge égal. Les longueurs moyennes d’énoncés de Marie et de Théotime se situent régulièrement entre celles de William et celle de Violet, ce qui montre bien que les différences entre les enfants l’emportent sur les différences inter-langue.